近日,华为分析服务6.9.0版本发布,正式上线探索能力。开发者可自由定义与配置分析模型,支持报告实时预览,数据洞察体验更加灵活与便捷。
新上线的探索能力中,有漏斗分析、事件归因、会话路径分析三个高级分析模型。在原有能力的基础上,时效性进一步增强,开发者在完成配置与报告创建后,即能查看具体内容。通过低时延、快响应的数据分析,能够及时发现用户在关键转化节点和链路的流失异常,基于此可迅速制定调优策略,有效提升运营效率。
一、漏斗分析:直观分析各环节流失率,达成持续有效的用户增长
关键业务流程的漏斗创建可帮助运营直观分析转化异常,迅速定位问题节点;而响应更快、时间颗粒度更细的转化周期更有利于及时发现异常环节的用户流失。
探索下的漏斗分析沿用原漏斗分析模型,在此基础上新增转化周期自定义能力,可按照分钟、小时、天级三个维度自由定义,不再局限于原有的自然天与会话转化周期。例如,在电商大促活动刚开始的黄金阶段,运营可能会更加关注用户在前几小时甚至几十分钟内的用户转化情况,那么可以通过自定义转化周期的方法,灵活调整并实时预览报告,迅速定位异常流失,及时调优。
![]() 电商转化漏斗示意,非真实数据
电商转化漏斗示意,非真实数据
需要注意的是,随着探索漏斗分析的上线,我们将关闭原漏斗分析菜单入口,您的历史漏斗分析报告将全部迁移至探索报告中,可在相关页面查看。
二、归因分析:精准还原每次转化的贡献分布,帮助企业优化资源配置
探索下的归因分析依旧沿用原“归因分析—事件归因分析”模型,开发者可自由定义目标转化事件和待归因事件,并根据业务特点选择更适合的归因模型。
举个例子,当促销福利类活动上线时,运营通常会通过Push消息、应用内弹窗等各类方式触达用户,以实现用户付费转化提升的目的。那评估不同形式的营销贡献占比则可以通过事件归因来实现,我们将“支付完成”作为目标转化事件,以“点击应用内消息”、“营销Push点击事件”为“待归因事件”,通过建立相关归因报告后即能预览不同营销策略对购买商品的贡献率,合理调整和优化预算分配。
![]()
归因报告示意,非真实数据
和漏斗分析一样,原事件归因分析菜单入口也将下线关闭,您可以在探索中查看历史创建的事件归因分析报告。
三、会话路径分析:了解用户应用内行为,验证运营思路,指导产品迭代
和原会话路径分析不同的是,探索下的会话路径分析支持开发者自由选择需要分析的目标事件与页面,同时事件级路径还支持定义起始事件和结束事件。
面对错综复杂的用户应用内实际流转情况,会话路径的探索则更加明确与聚焦。开发者通过关键事件的筛选,可以更便捷地分析出什么样的路径转化周期更短,哪条路径更符合用户的使用习惯等,让产品的进一步迭代优化更具思路与方向。
![]() 会话路径报告示意,非真实数据
会话路径报告示意,非真实数据
作为一站式用户行为分析平台,华为分析服务既为开发者提供了丰富的预置分析模型,又上新了更加灵活的高级数据探索能力,满足更多开发者精细化运营诉求,提供更好更快的数据运营体验。 以上就是华为分析服务探索能力的相关介绍,欲了解更多更新内容,欢迎访问华为分析服务官网,获取分析服务开发指导文档。
了解更多详情>>
访问华为开发者联盟官网
获取开发指导文档
华为移动服务开源仓库地址:GitHub、Gitee
关注我们,第一时间了解 HMS Core 最新技术资讯~
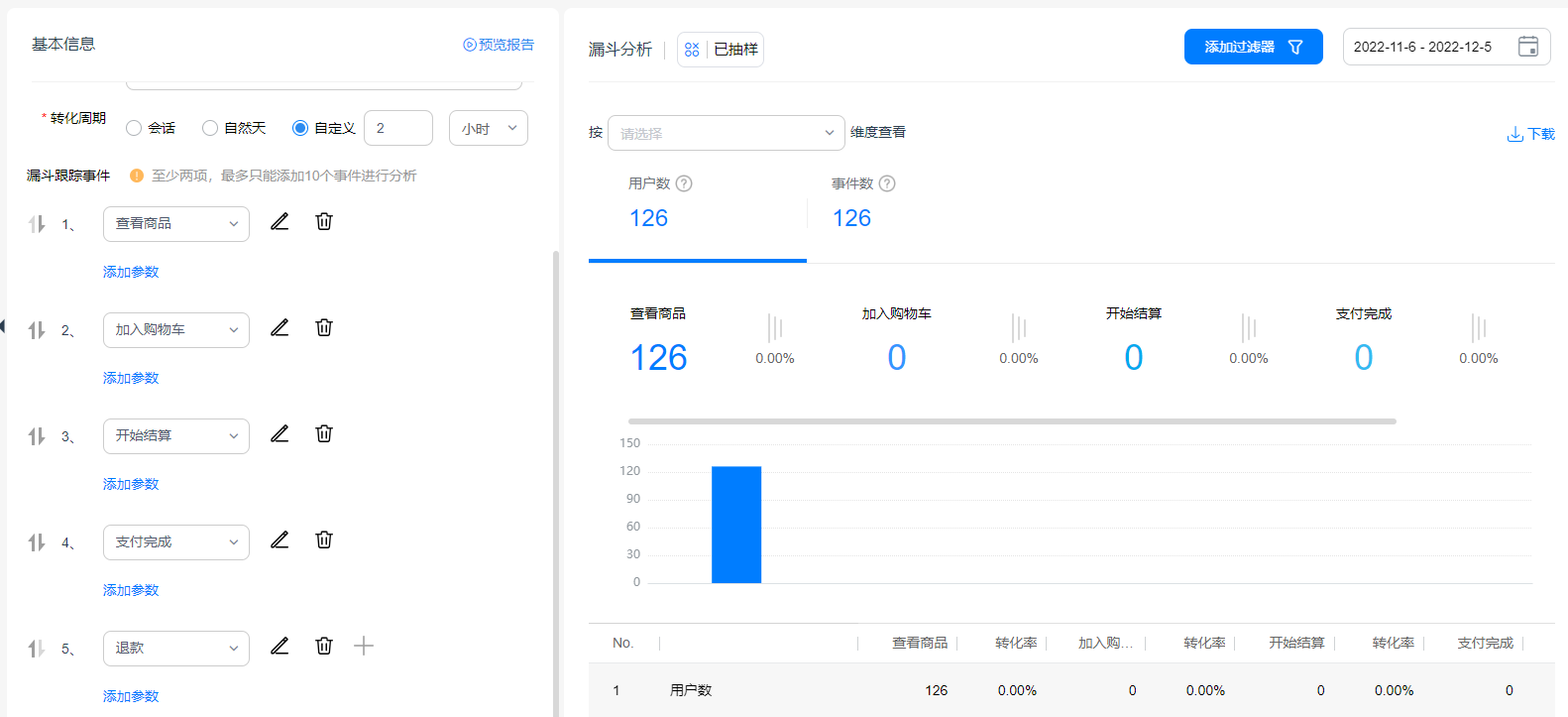 电商转化漏斗示意,非真实数据
电商转化漏斗示意,非真实数据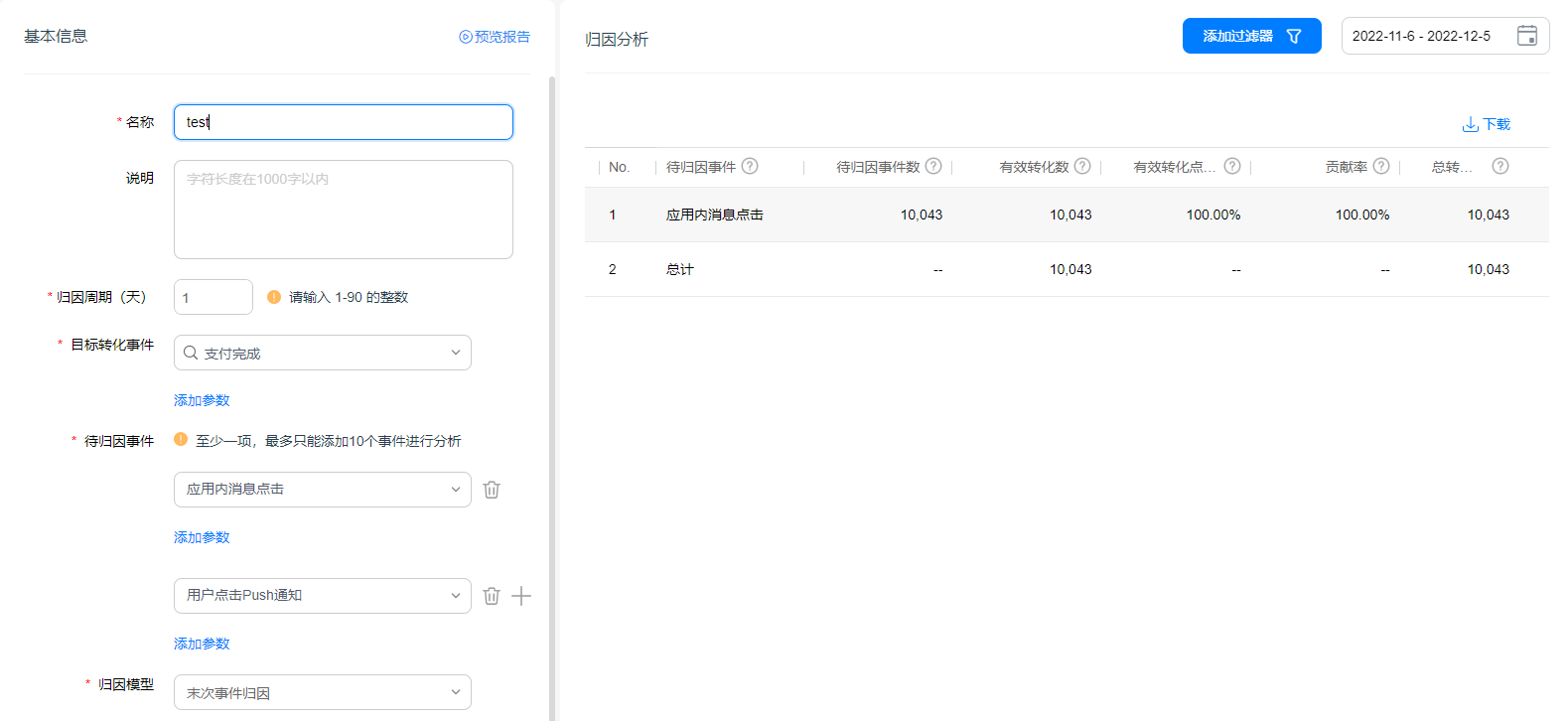
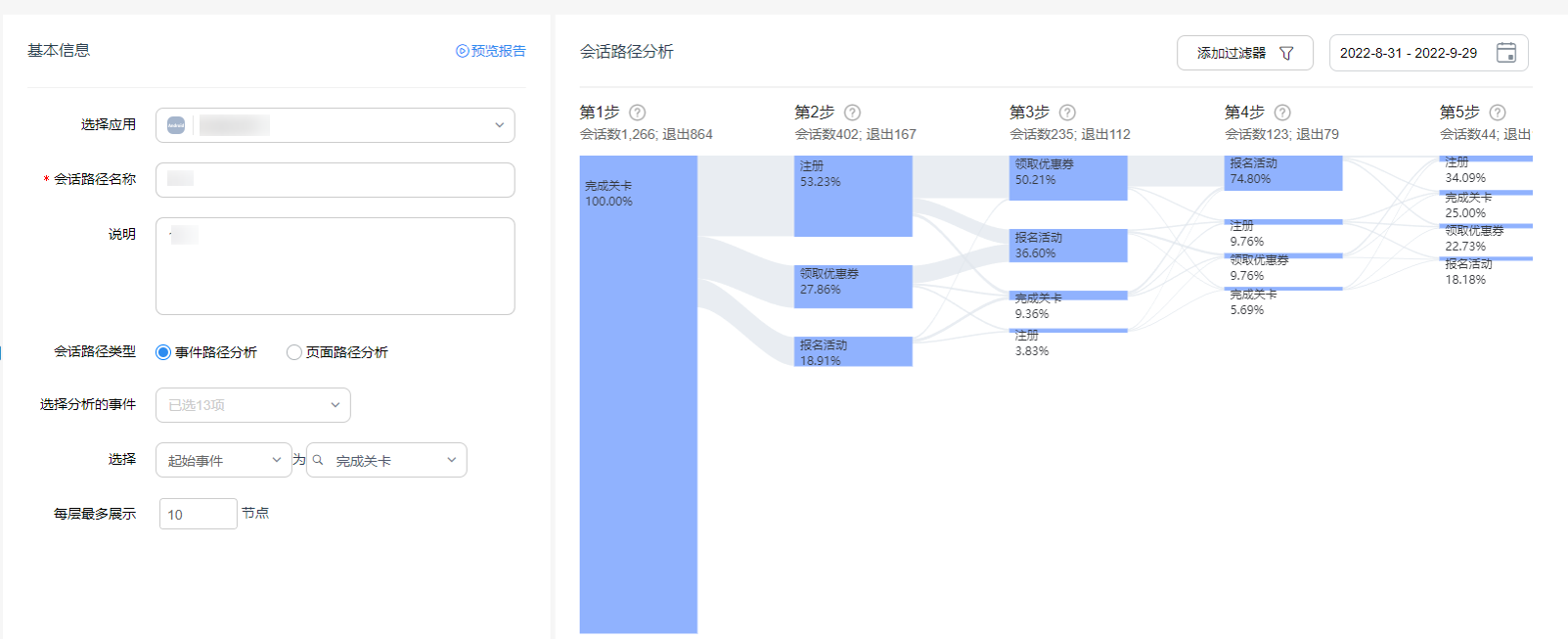 会话路径报告示意,非真实数据
会话路径报告示意,非真实数据