我们在这里选用了 MSR-VTT (Microsoft Research Video to Text)[7] 数据集的部分数据(1000个)。MSR-VTT[8] 是一个公开的视频描述数据集,由 10000 个视频片段与对应的文本描述组成。你可以选择从 google drive 或者通过以下代码下载和解压数据,解压后的数据包括了以下几个部分:
sample_num = 1000 # you can change this sample_num to be smaller, so that this notebook will be faster. test_df = pd.read_csv(test_csv_path) print('length of all test set is {}'.format(len(test_df))) sample_df = test_df.sample(sample_num, random_state=42)
from IPython import display from pathlib import Path import towhee from PIL import Image
def display_gif(video_path_list, text_list): html = '' for video_path, text in zip(video_path_list, text_list): html_line = '<img src="{}"> {} <br/>'.format(video_path, text) html += html_line return display.HTML(html)
# For the first time you run this line, # it will take some time # because towhee will download operator with weights on backend. dc = ( towhee.read_csv(test_sample_csv_path).unstream() .runas_op['video_id', 'id'](func=lambda x: int(x[-4:] "'video_id', 'id'")) .video_decode.ffmpeg['video_path', 'frames'](sample_type='uniform_temporal_subsample', args={'num_samples': 12} "'video_path', 'frames'") \ .runas_op['frames', 'frames'](func=lambda x: [y for y in x] "'frames', 'frames'") \ .video_text_embedding.clip4clip['frames', 'vec'](model_name='clip_vit_b32', modality='video', device=device "'frames', 'vec'") \ .to_milvus['id', 'vec'](collection=collection, batch=30 "'id', 'vec'") )
Recall@topk 是在 top k 个结果的“查全率”。比如,共有 5 个目标结果,Recall@top10 为 40% 则表示前十个结果中找到了 2(5*40%)个目标结果。本案例中每次只有一个目标结果,因此 Recall@topk 同时也意味着准确率(Accuracy)。
dc = ( towhee.read_csv(test_sample_csv_path).unstream() .video_text_embedding.clip4clip['sentence','text_vec'](model_name='clip_vit_b32', modality='text', device=device "'sentence','text_vec'") .milvus_search['text_vec', 'top10_raw_res'](collection=collection, limit=10 "'text_vec', 'top10_raw_res'") .runas_op['video_id', 'ground_truth'](func=lambda x : [int(x[-4:] "'video_id', 'ground_truth'")]) .runas_op['top10_raw_res', 'top1'](func=lambda res: [x.id for i, x in enumerate(res "'top10_raw_res', 'top1'") if i < 1]) .runas_op['top10_raw_res', 'top5'](func=lambda res: [x.id for i, x in enumerate(res "'top10_raw_res', 'top5'") if i < 5]) .runas_op['top10_raw_res', 'top10'](func=lambda res: [x.id for i, x in enumerate(res "'top10_raw_res', 'top10'") if i < 10]) )
我们分别返回 top 1 个、top 5 个和 top 10 个预测结果,并查看分别对应的评估结果:
MSR-VTT (Microsoft Research Video to Text): https://www.microsoft.com/en-us/research/publication/msr-vtt-a-large-video-description-dataset-for-bridging-video-and-language/
Zilliz 是向量数据库系统领域的开拓者和全球领先者,研发面向 AI 生产系统的向量数据库系统。Zilliz 以发掘非结构化数据价值为使命,致力于打造面向 AI 应用的新一代数据库技术,帮助企业便捷地开发 AI 应用。Zilliz 的产品能显著降低管理 AI 数据基础设施的成本,帮助 AI 技术赋能更多的企业、组织和个人。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
 与「图像描述」、「以文搜图」等跨模态任务的原理类似,基于内容理解的「视频检索」通过选取视频剪辑中的关键帧,将其转换成能表达该视频的特征向量。为了节省资源和方便观察,我们先可以选择将视频转换为 GIF 动图:
与「图像描述」、「以文搜图」等跨模态任务的原理类似,基于内容理解的「视频检索」通过选取视频剪辑中的关键帧,将其转换成能表达该视频的特征向量。为了节省资源和方便观察,我们先可以选择将视频转换为 GIF 动图:

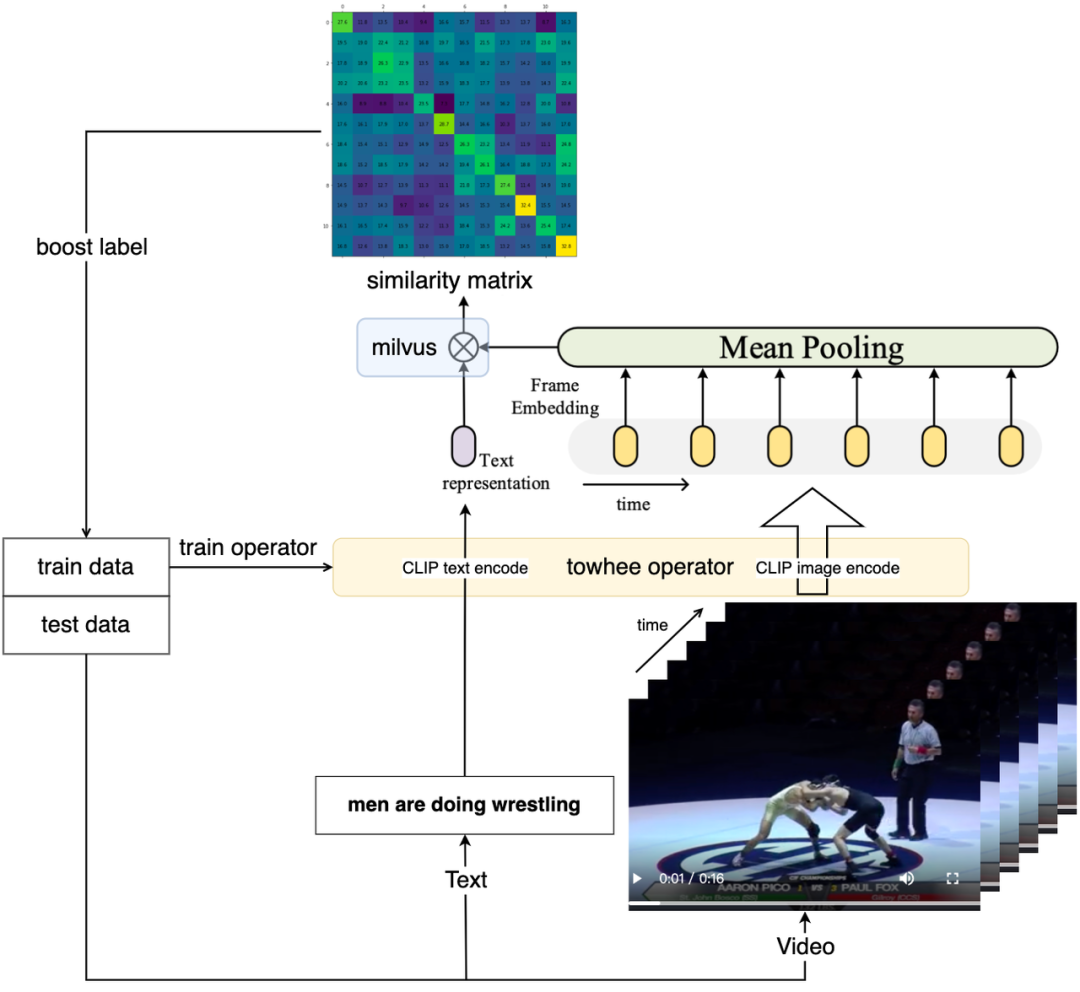 为了将视频与文本转换成向量,我们需要一个视频-文本跨模态的神经网络模型用于提取特征。Towhee 提供了
为了将视频与文本转换成向量,我们需要一个视频-文本跨模态的神经网络模型用于提取特征。Towhee 提供了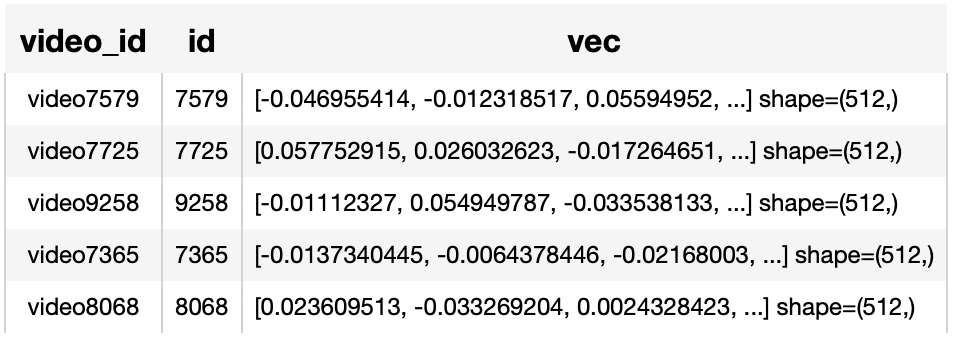 我们在这里对上面的代码做一些接口说明:
我们在这里对上面的代码做一些接口说明:
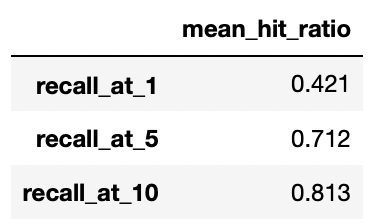 这些评估结果与
这些评估结果与 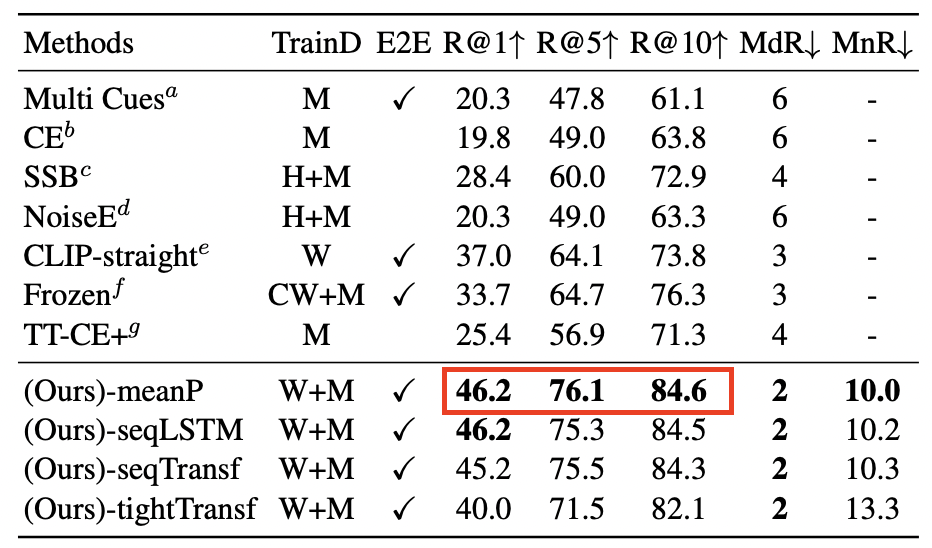
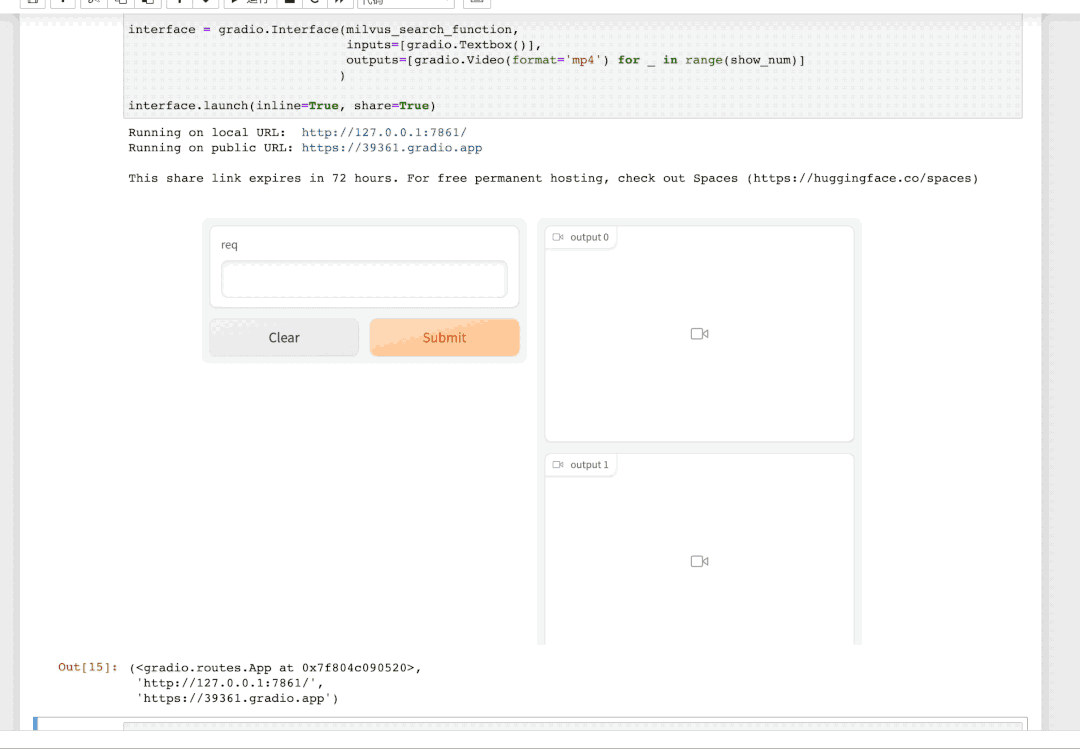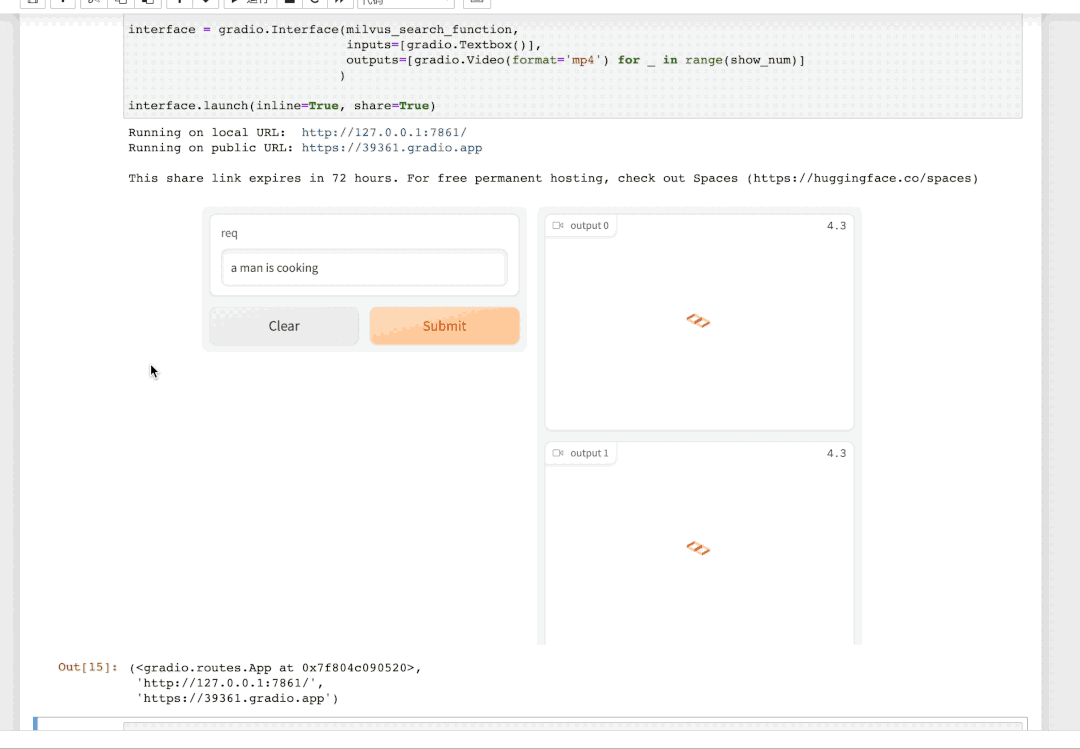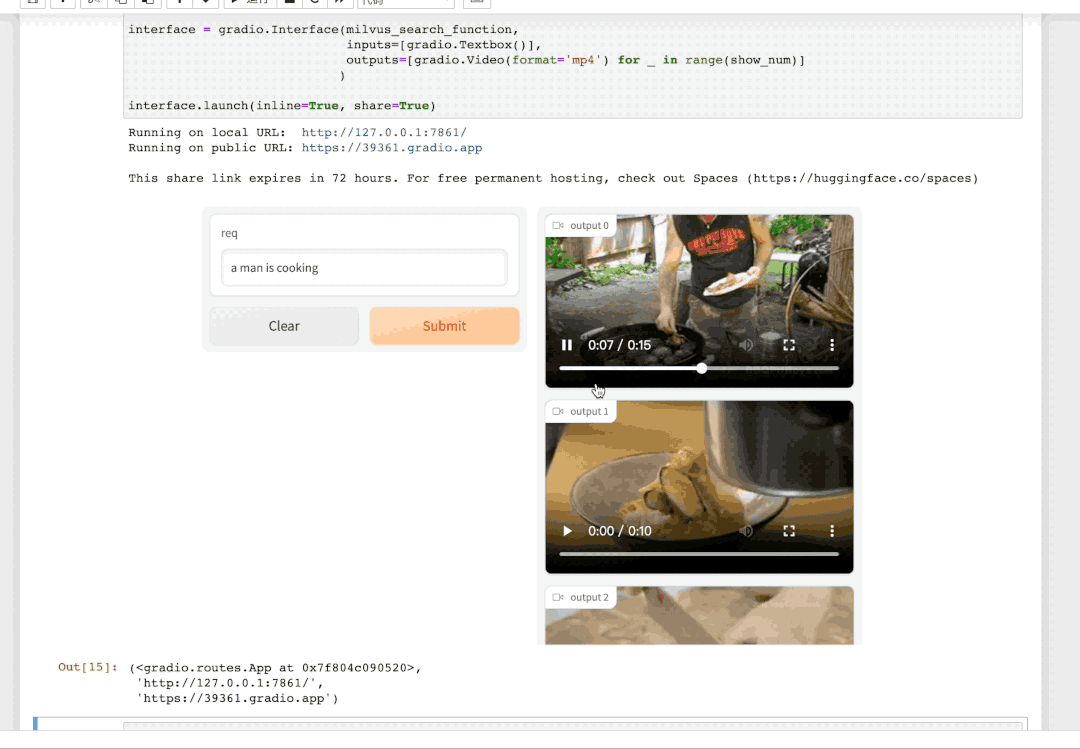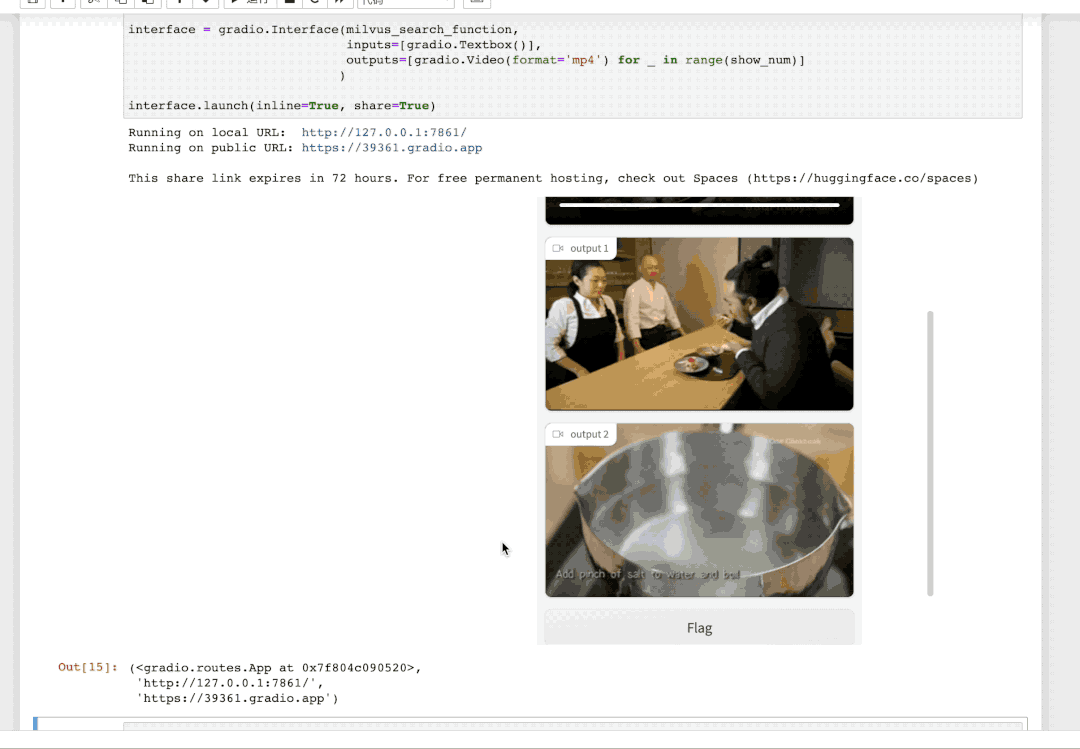
 点击这个 URL 链接,就会跳转到「视频检索」服务的交互界面。输入你想要搜索的文本描述,即找到视频库中最符合该描述的视频。例如,我们输入 "a man is cooking" (一个男人正在做饭) 即可得到:
点击这个 URL 链接,就会跳转到「视频检索」服务的交互界面。输入你想要搜索的文本描述,即找到视频库中最符合该描述的视频。例如,我们输入 "a man is cooking" (一个男人正在做饭) 即可得到:
