初次邂逅
之前有一天,我偶然发现了 motherduck.com,朴素得过分的网站。
![]()
但背后是一支全明星队伍。
![]()
看他们的标语 "Data Infrastructure and Analytics"(数据基础设施和分析)和团队背景,似乎是要挑战 Snowflake / Databricks?但是如果又再来个声称「有性能 / 价格优势」的云原生数仓听起来就有点无聊了。另外,MotherDuck 这个名字很不寻常,为什么要选这个名字? 读了他们 4750 万美元 A 轮融资的消息,然后看了下新的官网后,我悟了。
命名
MotherDuck 名字来源 DuckDB,像 SQLite 架构一样的分析型数据库。MotherDuck 把开源的 DuckDB 商业化了,这也是现在 infra 创业公司的标准套路。
宣言
![]()
开始,我对 Serverless 感到困惑。 虽然 Serverless(无服务器)是一个被滥用的词,但大多数人还是会把它和云计算联系起来。 MotherDuck 把自己包装成为 Serverless,却叫大家别等云了 (Why wait for the cloud?),但是他们最终可能仍会提供云服务(还有谁不会呢? )。 从常识上讲,Serverless 意味着云服务提供商掩盖了服务器的存在。服务器还在,只是用户不需要关心它们了。但是,MotherDuck 的 Serverless 则是另一回事:他们根本就没有服务器,因为底层的 DuckDB 只是一个可嵌入的库,而不是一个独立服务器。所以这里更准确的说法应该是 No Server。
数据民主化
Snowflake 引入了新的想法,把计算和存储分离,这种在架构上的创新赋予了他们巨大的竞争优势。虽然从产品的角度来看,他们仍然是紧密耦合的,因为数据被锁定在 Snowflake 平台上了。 MotherDuck 则不同。假设你有一个单一的数据文件:无论是 Parquet,CSV,SQLite,还是其他格式,该文件储存在你的本地磁盘, S3, GitHub,或任何地方。然后你用 MotherDuck 从计算环境中挂载该文件,你就有了一个强大的工具可以分析该文件了。因为 MotherDuck 的零依赖性(感谢受 SQLite 启发的 DuckDB),它只需要几秒钟就能获得 MotherDuck 二进制文件(甚至在预编译的发行版中包含它之后,这一步也省去了)。
![]()
Snowflake 分离了计算和存储,而 MotherDuck 将计算接入存储。有了 MotherDuck,只要你能访问数据文件,你就有了分析能力,在此之上,你还可以建立数据解决方案。
举个例子:OSS Insight,一个实时获取 GitHub 相关事件并提供洞察的网站。虽然它的技术栈已经通过采用 TiDB 而被简化了,但未来 MotherDuck 可以用更简单的技术栈做到类似的。
![]()
因为有了 MotherDuck,你所有应用程序的运行时依赖的制品都可以保存在一个文件中。
当然这不是一个新想法。传奇的 Hypercard 最早引入了这个做法,将一个独立的应用程序和数据存储到一个文件中。
![]()
还有历史悠久的 FileMaker Pro,整个应用程序和数据都存储在一个单一的 `.fmp12` 文件中。
![]()
但是,MotherDuck 可以把这个想法带到一个新的高度,因为他们能够高效处理 TB 级的数据,以及在数据集 / MotherDuck 引擎 / MotherDuck 平台之间定义开放协议,与 GitHub 集成来促进协作等等。
![]()
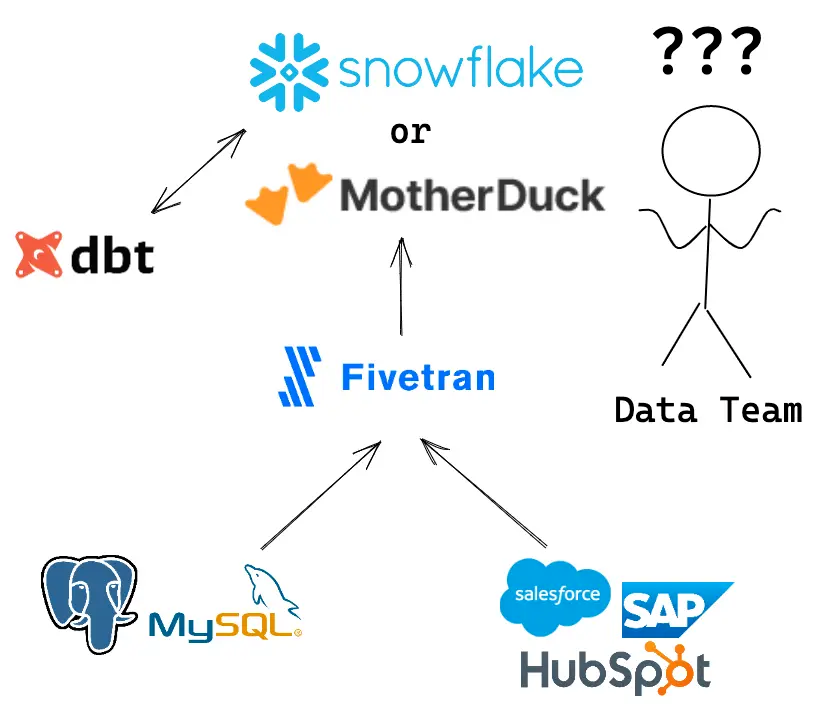
MotherDuck 一上来就要开始与 Snowflake 在各个方面的竞争。数据团队仍然需要 Fivetran 来移动数据;dbt 来转换数据;甚至 meltano 来组装数据平台;但对于分析任务,他们将不得不决定从哪里运行:是 Snowflake Cloud 还是装着 MotherDuck 的任意计算环境?
而当把目光放到更远的地方,一切都还未被开垦。MotherDuck 可以释放出一系列全新的数据解决方案。Only sky is the limit。
![]()
MotherDuck 的想法很新奇,时机也很完美。 数据分析领域正在静候下一个范式的转变。 从业者门有一个更好的 Snowflake 就很开心了,而有远见的人会要求更多。 MotherDuck 明智地选择了一个不同的战场,而不是在性能 / 成本上互卷。
写在最后
之前大家为了获得处理数据的能力,只能把数据交给 Snowflake(或类似厂家)。 而有了 MotherDuck 后,大家也都具备了类似的处理能力,同时还可以自己掌控数据: 可以把数据保存在任何他们想要存放的地方,只与他们愿意分享的人分享,并在需要的时候随时能使用它。
Docker 作为一个运行时和标准,使得应用程序广泛普及,MotherDuck 也可以成为一个运行时和标准使得数据使用可以广泛普及。
而且这次,MotherDuck 必然比 Docker, Inc 准备得更好,得以在愿景实现时获得最大的份额。
祝 MotherDuck 团队好运。好奇叫 Ducker 这个名字是不是更好一点 :)