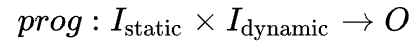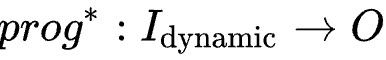1 云原生时代Java语言的困境
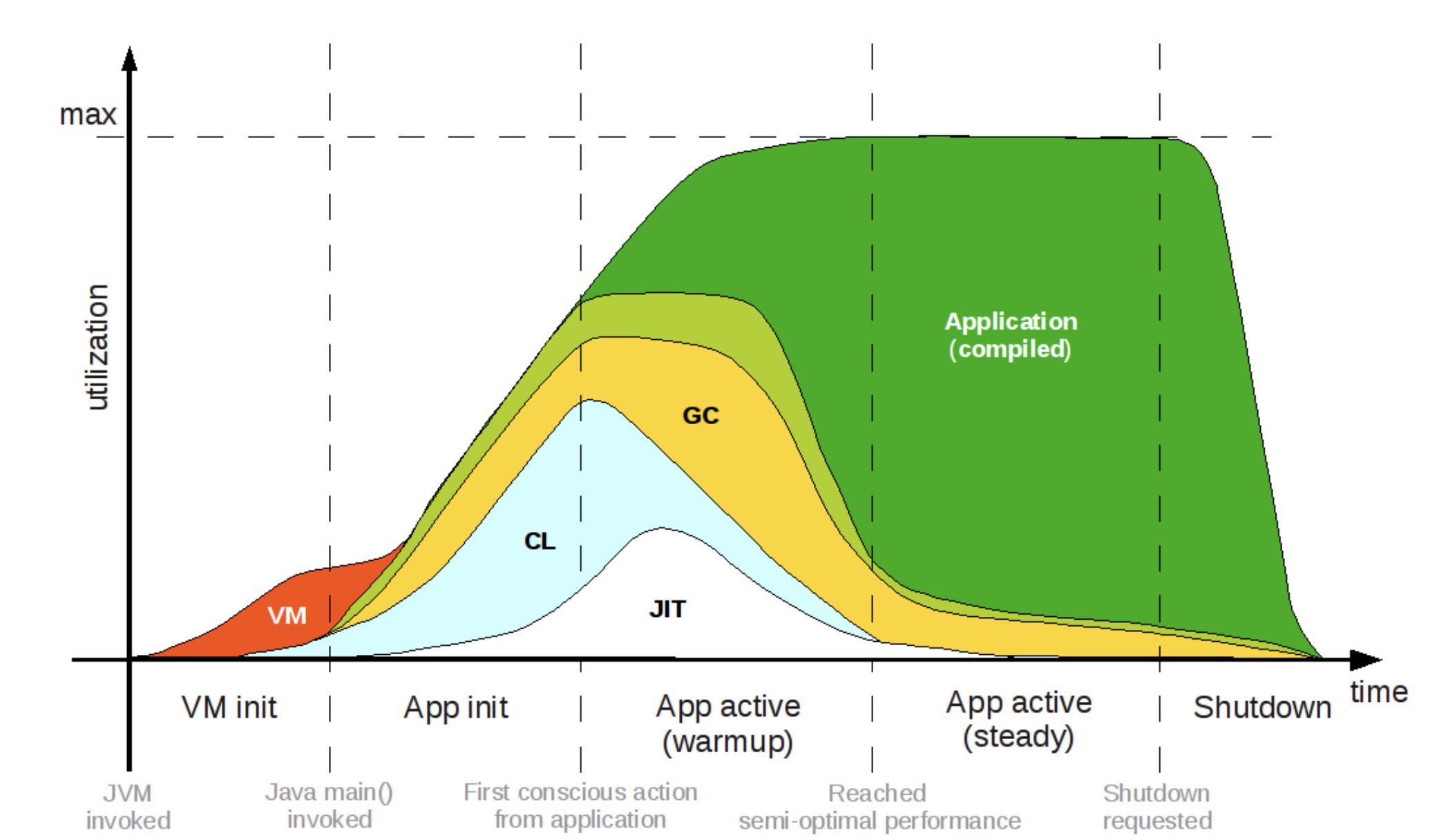
经过多年的演进,Java语言的功能和性能都在不断的发展和提高,诸如即时编译器、垃圾回收器等系统都能体现Java语言的优秀,但是想要享受这些功能带来的提升都需要一段时间的运行来达到最佳性能,总的来说Java是面向大规模、长时间使用的服务端应用而设计的。
云原生时代,Java语言一次编译到处运行的优势不复存在,理论上使用容器化技术,所有语言都能部署上云,而无法脱离JVM的Java应用往往要面对JDK内存占用比应用本身还大的窘境;Java动态加载、卸载的特性也使得构建的应用镜像中有一半以上的无用代码和依赖这些都使得Java应用占用内存相当多。而启动时间长,性能达到峰值的时间长使得在Serverless等场景下无法与Go、Node.js等快速语言竞争。
![]()
Java应用程序的运行生命周期示意图
2 GraalVM
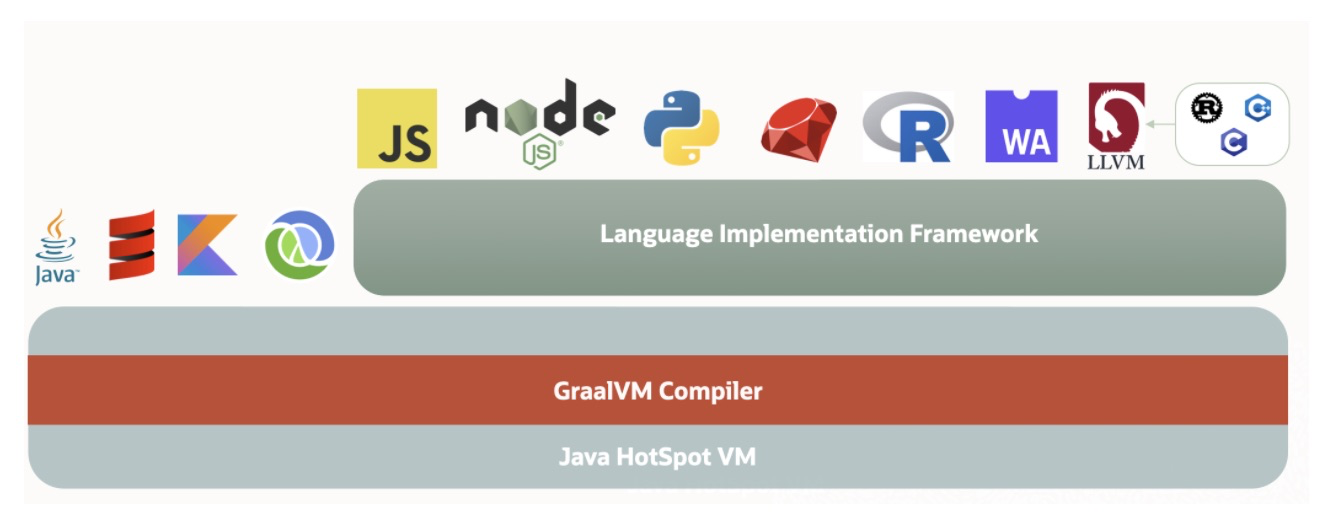
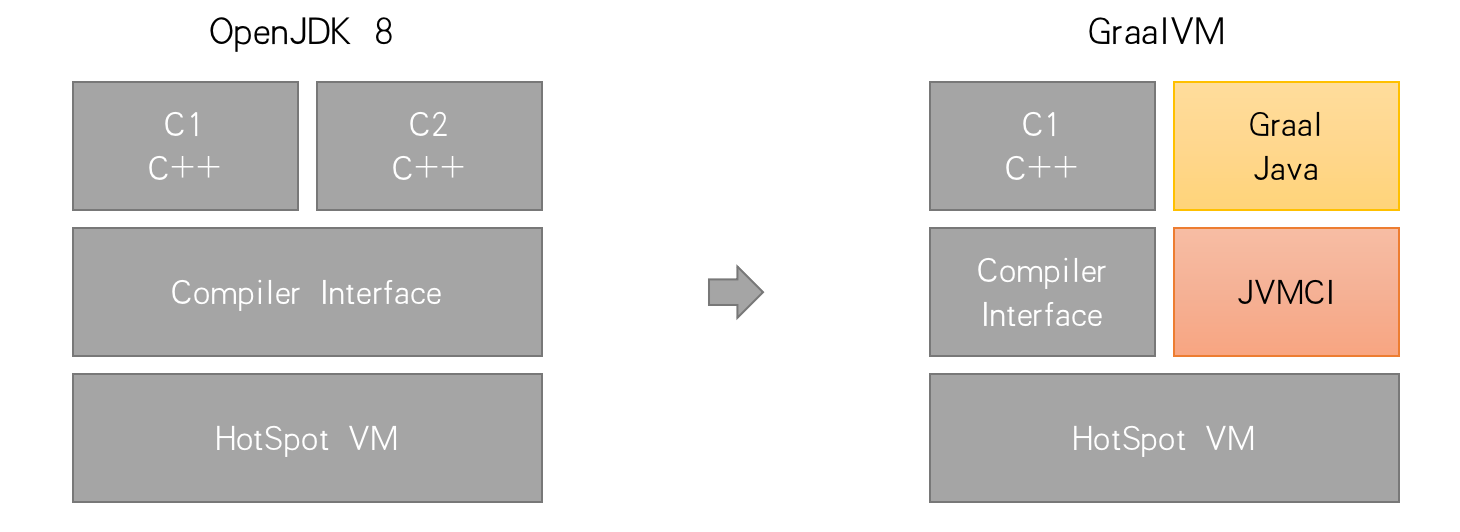
面对云原生时代Java的不适,GraalVM或许是最好的解药。GraalVM是Oracle实验室推出的基于Java开发的开源高性能多语言运行时平台,它既可以在传统的 OpenJDK 上运行,也可以通过 AOT(Ahead-Of-Time)编译成可执行文件单独运行,甚至可以集成至数据库中运行。除此之外,它还移除了编程语言之间的边界,并且支持通过即时编译技术,将混杂了不同的编程语言的代码编译到同一段二进制码之中,从而实现不同语言之间的无缝切换。
![]()
本文主要简单从三个方面介绍GraalVM可以为我们带来的改变:
1)基于Java的Graal Compiler的出现对学习和研究虚拟机代码编译技术有着不可估量的价值,相比C++编写的复杂无比的服务端编译器,不管是对编译器的优化还是学习的成本都大大的降低。
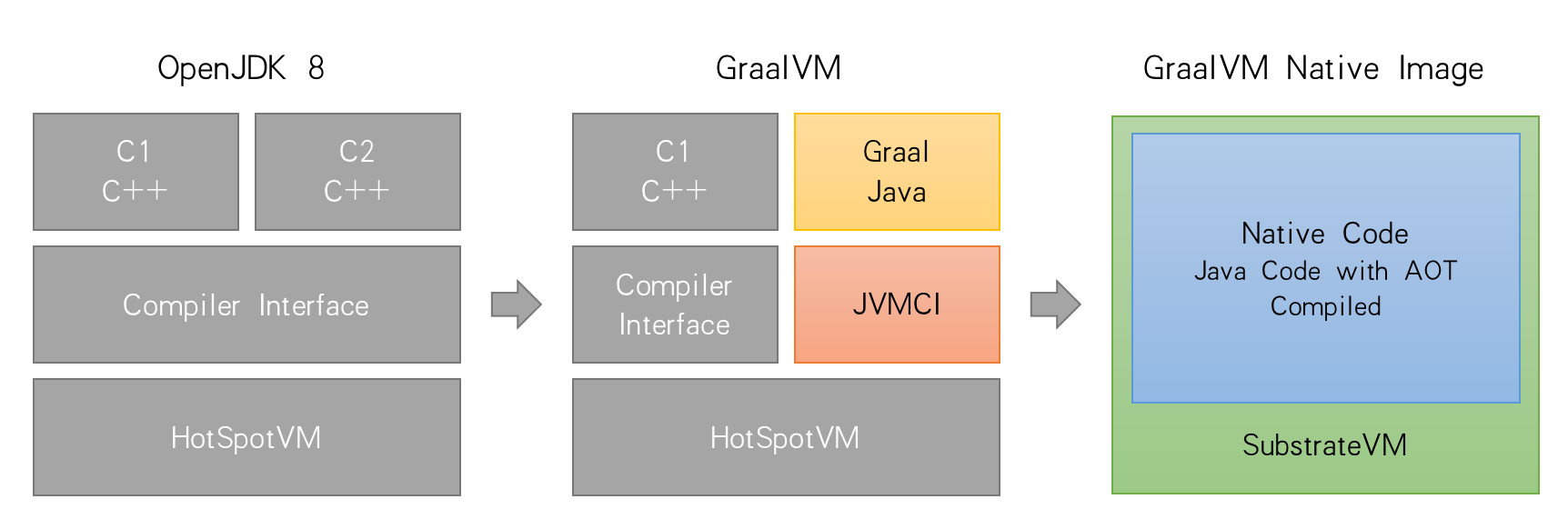
2)静态编译框架Substrate VM框架,为Java在云原生时代提供了与其他语言竞争的可能,大大的减少了Java应用占用内存,并且可以加快启动速度几十倍。
![]()
3)以Truffle和Sulong为代表的中间语言解释器,开发者可以使用Truffle提供的API快速用Java实现一种语言的解释器,从而实现了在JVM平台上运行其他语言的效果,为Java世界带来了更多更有想象力的可能性。
![]()
GraalVM多语言支持
3 GraalVM整体结构
graal
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── SECURITY.md
├── THIRD_PARTY_LICENSE.txt
├── bench-common.libsonnet
├── ci-resources.libsonnet
├── ci.hocon
├── ci.jsonnet
├── ci_includes
├── common-utils.libsonnet
├── common.hocon
├── common.json
├── common.jsonnet
├── compiler
├── docs
├── espresso
├── graal-common.json
├── java-benchmarks
├── regex
├── repo-configuration.libsonnet
├── sdk
├── substratevm
├── sulong
├── tools
├── truffle
├── vm
└── wasm
3.1 Compiler
Compiler子项目全称GraalVM编译器,是用Java语言编写的Java编译器。高编译效率、高输出质量、同时支持提前编译(AOT)和即时编译(JIT)、同时支持应用于包括HotSpot在内的不同虚拟机的编译器。
与C2采用一样的中间表示形式(Sea of Nodes IR),后端优化上直接继承了大量来自于HotSpot的服务端编译器的高质量优化技术,是现在高校、研究院和企业编译研究实践的主要平台。
Graal Compiler是GraalVM与HotSpotVM(从JDK10起)共同拥有的服务端即时编译器,是C2编译器未来的替代者。为了让 Java 虚拟机与编译器解耦,ORACLE引入了Java-Level JVM Compiler Interface(JVMCI)Jep 243 :把编译器从虚拟机中抽离出来,并且可以通过接口与虚拟机交流(https://openjdk.java.net/jeps/243)
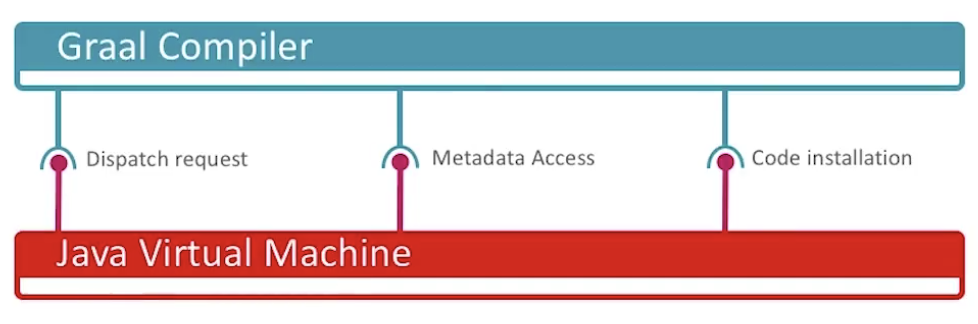
![]()
具体来说,即时编译器与 Java 虚拟机的交互可以分为如下三个方面。
- 响应编译请求;
- 获取编译所需的元数据(如类、方法、字段)和反映程序执行状态的 profile;
- 将生成的二进制码部署至代码缓存(code cache)里。
![]()
![]()
![]()
oracle提供的编译时间差异示例
3.2 Substrate VM
Substrate VM提供了将Java程序静态编译为本地代码的编译工具链,包括了编译框架、静态分析工具、C++支持框架及运行时支持等。在程序运行前便将字节码转换为机器码
优点:
- 从指定的编译入口开始静态可达性分析,有效的控制了编译范围,解决了代码膨胀的问题;
- 实现了多种运行时优化例如:传统的java类是在第一次被用到时初始化的,之后每次调用时还要再检查是否初始化过,GraalVM将其优化为在编译时初始化;
- 无需在运行过程中耗费CPU资源来进行即时编译,而程序也能在启动一开始就达到理想的性能;
缺点:
- 静态分析是资源密集型计算,需要消耗大量CPU、内存和时间;
- 静态分析对反射、JNI、动态代理的分析能力非常有限,目前GraalVM只能通过额外配置的方式加以解决;
- Java序列化也有多项违反封闭性假设的动态特性:反射,JNI,动态类载入,目前GraalVM也需要通过额外配置解决,且不能处理所有序列化,例如Lambda对象的序列化,而且性能是JDK的一半;
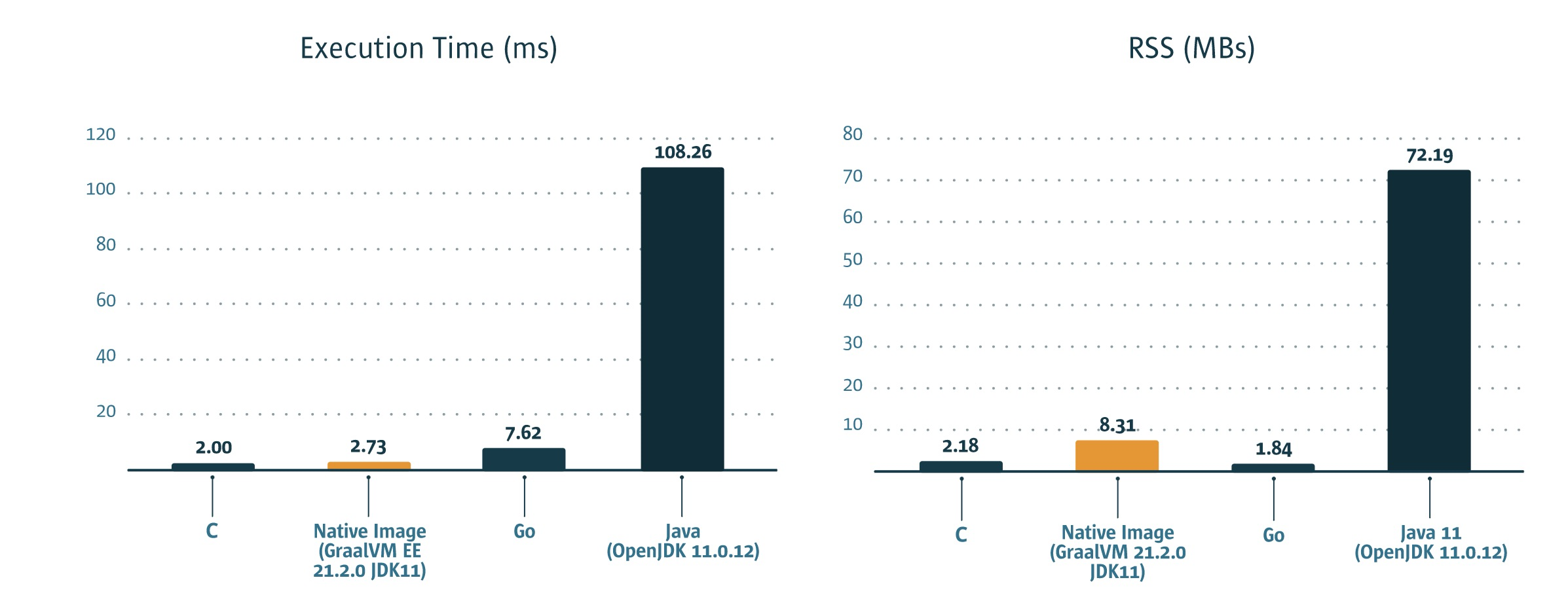
![]()
![]()
启动时长对比
![]()
占用内存对比
3.3 Truffle
我们知道一般编译器分为前端和后端,前端负责词法分析、语法分析、类型检查和中间代码生成,后端负责编译优化和目标代码生成。一种比较取巧的做法是将新语言编译成某种已知语言,如Scala、Kotlin可以编译成Java字节码,这样就可以直接享用JVM的JIT、GC等各项优化,这种做法都是针对的编译型语言。与之相对的,如JavaScript、Ruby、R、Python等解释型语言,它们依赖于解释执行器进行解析并执行,为了让这类解释型语言能够更高效的执行,开发人员通常需要开发虚拟机,并实现垃圾回收,即时编译等组件,让该语言在虚拟机中执行,如Google的V8引擎。如果能让这些语言也可以在JVM上运行并复用JVM的各种优化方案,将会减少许多重复造轮子的消耗。这也是Truffle项目的目标。
Truffle是一个用Java编写的解释器实现框架。它提供了解释器的开发框架接口,可以帮助开发人员用Java为自己感兴趣的语言快速开发处语言解释器,目前已经实现并维护了JavaScript、Ruby、R、Python等语言。
只需基于Truffle实现相关语言的词法分析器、语法分析器及针对语法分析所生成的抽象语法树(AST)的解释执行器,便可以运行在任何Java虚拟机上,享用JVM提供的各项运行时优化。
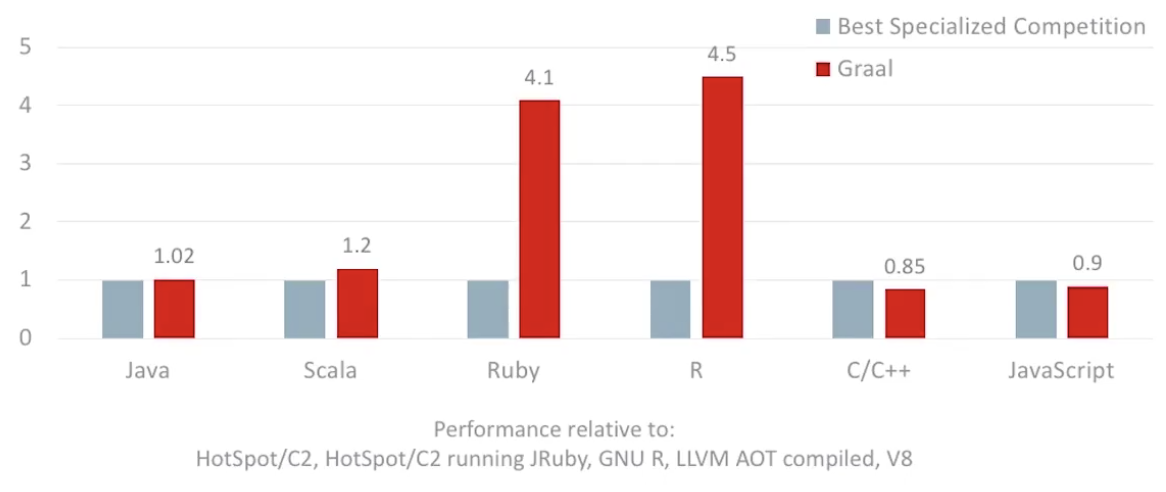
![]()
GraalVM多语言运行时性能加速比
3.3.1 Partial Evaluation
Truffle的实现原理基于Partial Evaluation这一概念:假设程序prog为将输入转为输出
![]()
其中Istatic为静态数据,在编译时已知常量,Idynamic为编译时未知数据,则可以将程序等价为:
![]()
新程序prog为prog的特化,他应该会比原程序更高效的执行,这个从prog转换到prog的过程便称为Partial Evaluation。我们可以将Truffle预压的解释执行器当成prog,将某段由Truffle语言写的程序当做Istatic,并通过Partial Evaluation将prog转换到prog*。
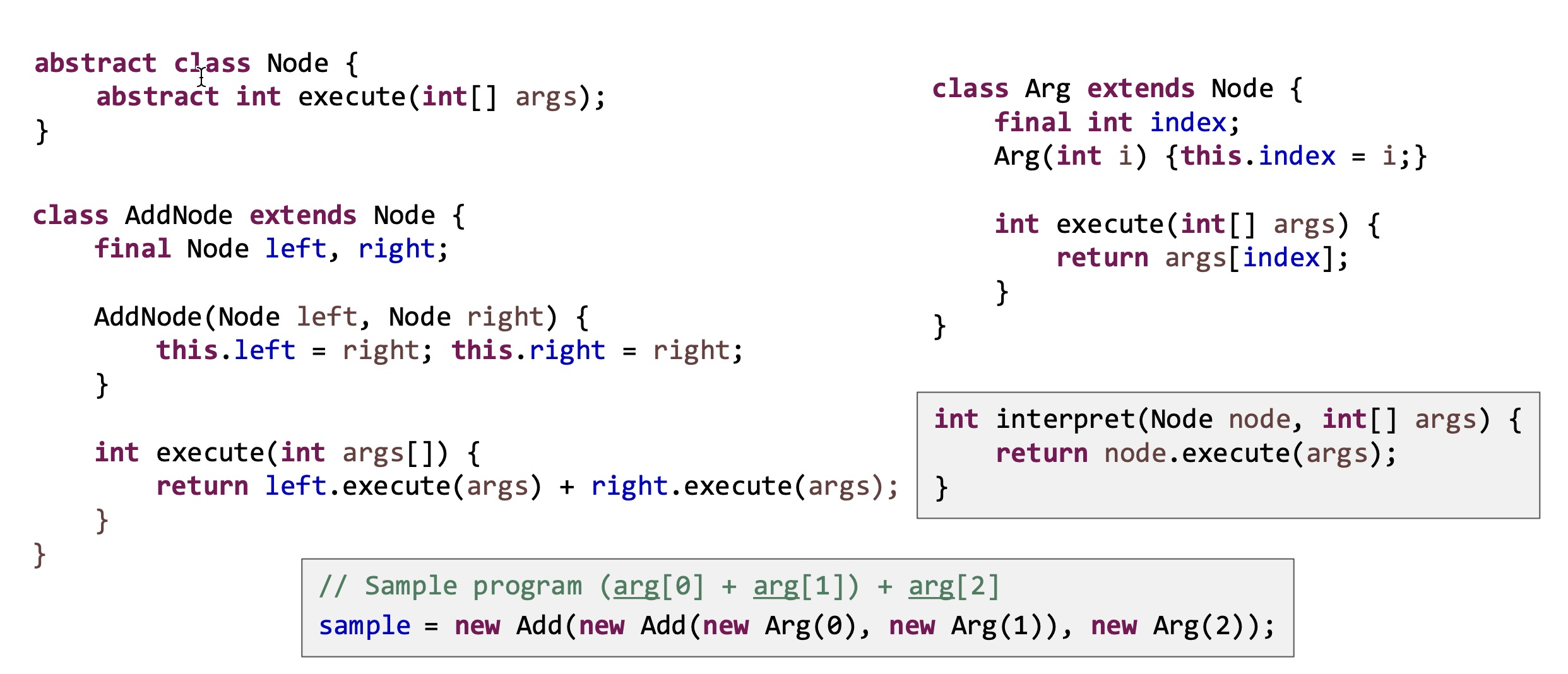
下面引用一个Oracle官方的例子来讲解,以下程序实现了读取参数以及参数相加的操作,需要实现读取三个参数相加:
![]()
这段程序解析生成的AST为
sample = new Add(new Add(new Arg(0), new Arg(1)), new Arg(2));
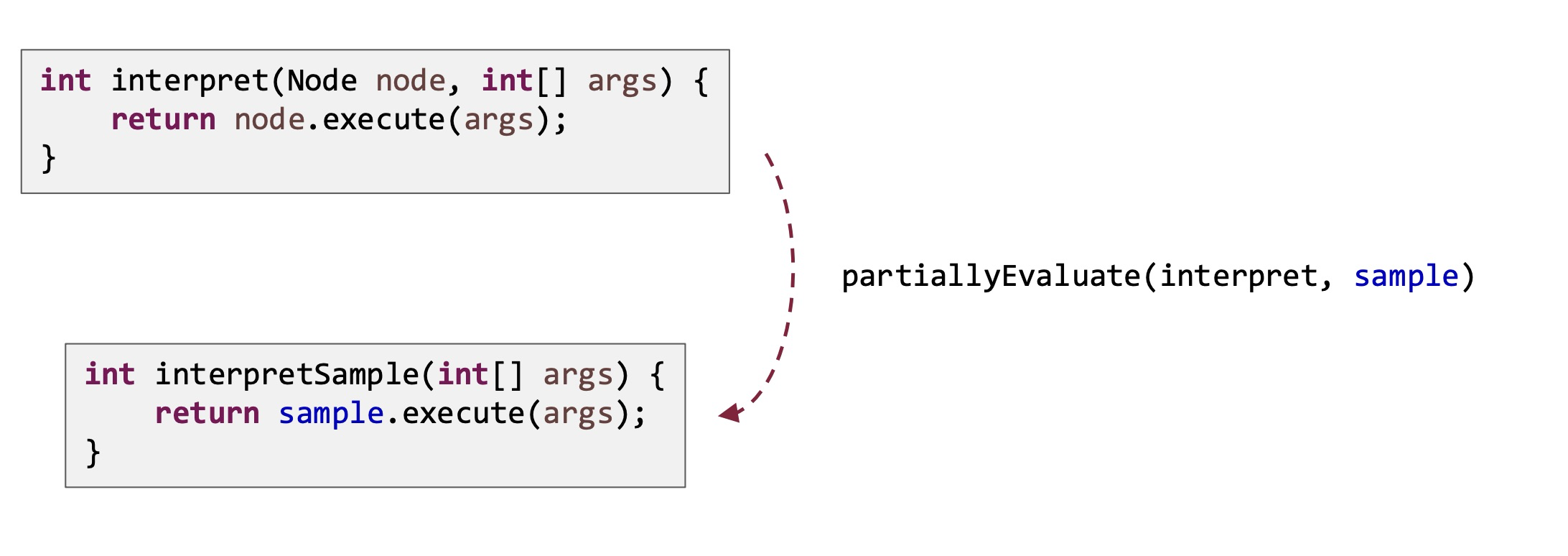
![]()
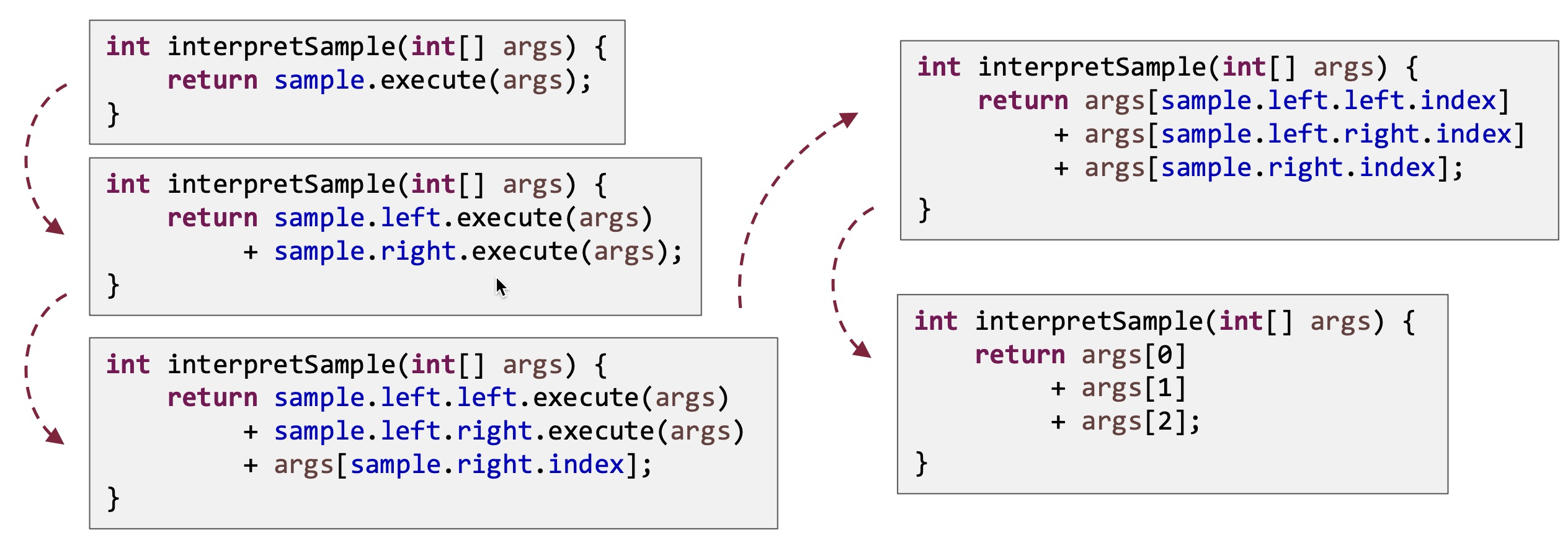
经过Partial Evaluator 的不断进行方法内联最终会变成下述代码:
![]()
3.3.2 节点重写
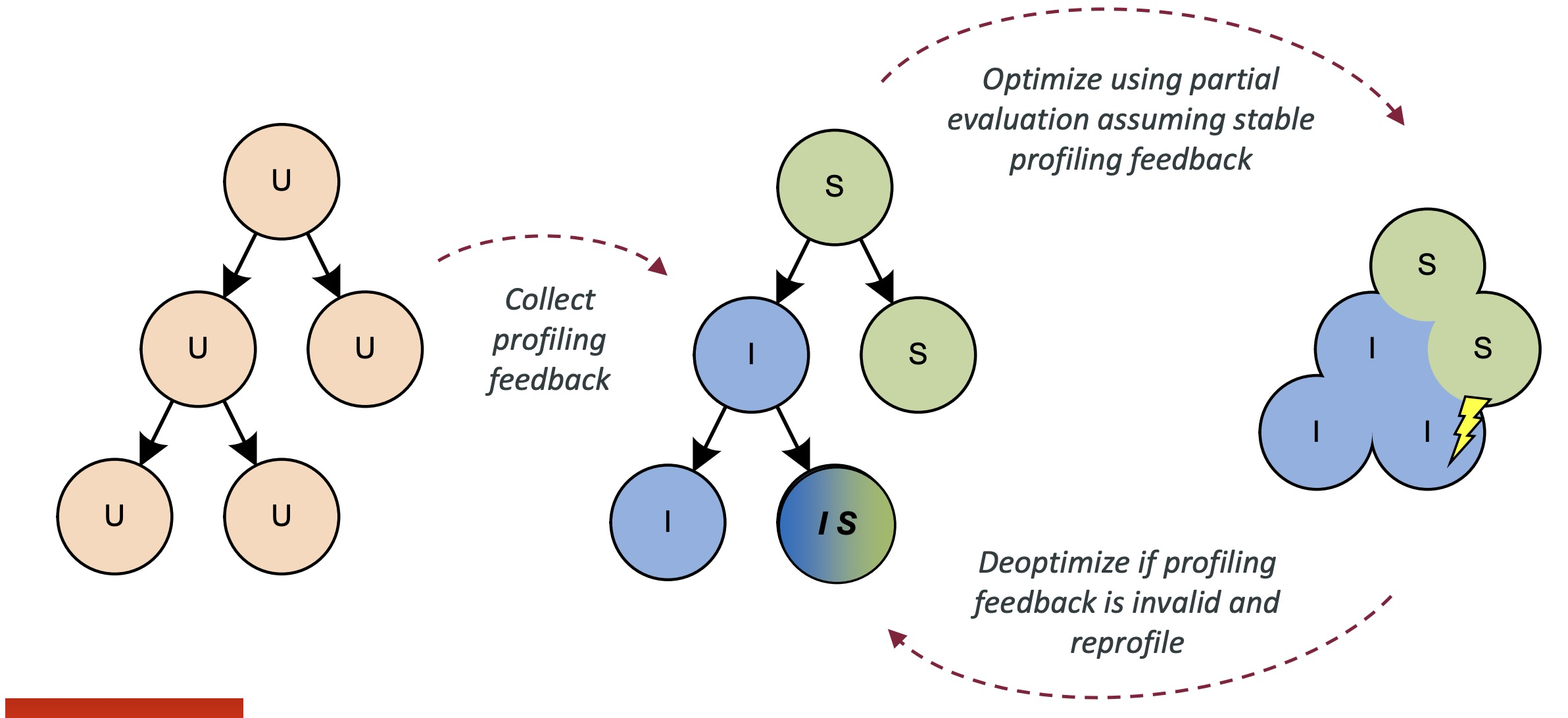
节点重写是Truffle的另一项关键优化。
在动态语言中许多变量的类型是在运行时才能确定的,以“加法”举例,符号+即可以表示整型相加也可以表示浮点型相加。Truffle的语言解释器会收集每个AST节点所代表的操作类型(profile),并且在编译时做出针对所收集到的profile进行优化,如:若收集到的profile显示这是一个整型加法操作,Truffle会在即时编译时将AST进行变形,将“+”视为整型加法。
当然,这种优化也会有错误的时候,比如上述加法操作既有可能是整数加法也可能是字符串加法,此时若AST树已变形,那么我们只好丢弃编译后的机器代码,回退到AST解释执行。这种基于类型 profile 的优化,背后的核心就是基于假设的投机性优化,以及在假设失败时的去优化。
![]()
在即时编译过后,如果运行过程中发现 AST 节点的实际类型和所假设的类型不同,Truffle 会主动调用 Graal 编译器提供的去优化 API,返回至解释执行 AST 节点的状态,并且重新收集 AST 节点的类型信息。之后,Truffle 会再次利用 Graal 编译器进行新一轮的即时编译。
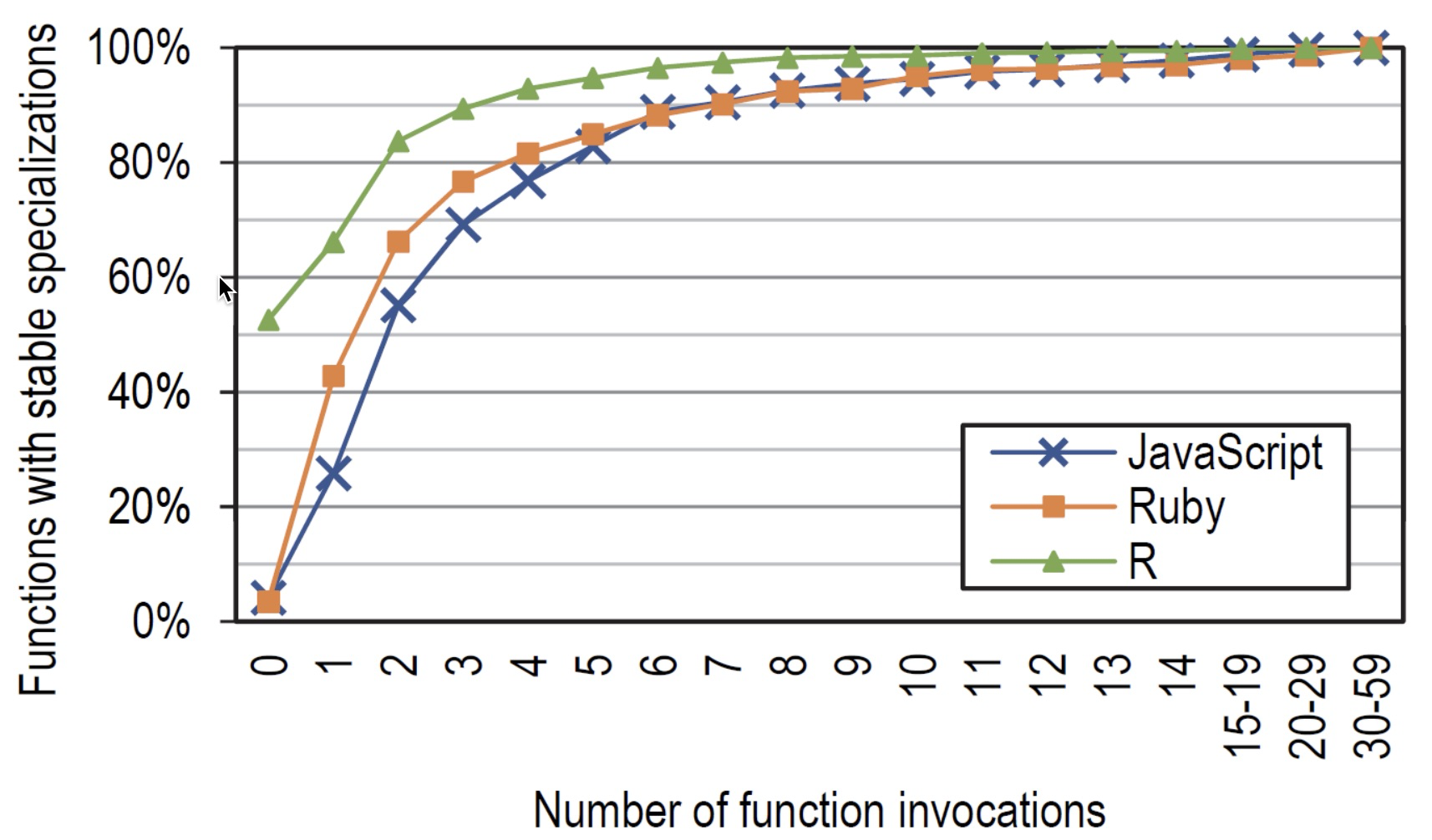
据统计,在 JavaScript 方法和 Ruby 方法中,80% 会在 5 次方法调用后稳定下来,90% 会在 7 次调用后稳定下来,99%会在 19 次方法调用之后稳定下来。
![]()
3.4 Sulong
Sulong子项目是GraalVM为LLVM的中间语言bitcode提供的高新更运行时工具,是基于Truffle框架实现的bitcode解释器。Sulong为所有可以编译到LLVM bitcode的语言(如C,C++等)提供了在JVM中执行的解决方案。
![]()
4 参考
- 林子熠 《GraalVM与静态编译》;
- 周志明《深入理解Java虚拟机》;
- Java Developer’s Introduction to GraalVM:-郑雨迪
- Truffle/Graal:From Interpreters toOptimizing Compilers via Partial Evaluation:-Carnegie Mellon University
作者:王子豪