本文作者:耿云涛
本文作者:葛大力
大数据技术日新月异,数据湖、数据中台、逻辑数据湖、数据编织、数据编排等数据建设理念不断出现、深化,究其根本依然是如何能够将数据规整起来,以统一的规范对数据的脉络进行梳理,形成统一的视图、统一的标准,实现业务层面的数据治理目标。
对于任何一种数据建设理念,数据安全都是绕不开的话题,数据安全的保障也是一个数据平台能否真正交付使用的准入门槛。
数据安全大体从4个维度展开:认证、授权、审计、加密。通过认证确保了用户的身份,严格的授权可以保护数据的访问隐私,审计数据的访问记录,发现可能的非法访问,通过加密确保数据存储持久化与数据传输链路的基础安全。
数据安全的每个维度都是很广泛的主题,本篇文章主要从审计的维度,分享一些Alluxio审计的实操做法以及一些注意事项。
Alluxio作为云原生数据编排平台,可以在面向异构基础设施环境(本地、混合云、公有云)的时候实现高效的数据统一管理编排,服务大数据与AI应用,Alluxio已经被广泛的应用在数据湖、数据中台、逻辑数据湖、数据编织等数据平台的建设架构中,在协助企业/组织解决技术变迁导致的多平台混合架构和数据碎片化、平台适配复杂性等问题上提供了很好地助力。
Alluxio往往会在新的数据平台架构上作为数据的统一访问接口服务层存在,依赖Alluxio的编排能力,实现底层散落在不同地域、不同技术的数据存储平台对上层计算/应用的接口统一、元数据统一,同时,基于Alluxio,可以进一步进行数据的统一治理能力的建设,有效的解决了数据碎片化的问题,以确保数据在应用视角的统一视图、统一标准。
作为数据平台的统一访问接口服务层,Alluxio会承载数据的所有读取和写入行为,那么作为数据访问门户性质的存在,Alluxio记录用户的数据访问行为,并支撑后续对这些用户行为的审计就变得尤为重要。
在开始Alluxio审计日志分析系统的构建阐述之前,首先我们来问两个问题,看看大家是否可以立刻给予答复:
1. 现在数据湖里的3PB数据,都是经常访问的吗? 过去一周时间内,这些数据访问频率有什么变化吗?
2. 这些数据有哪些用户在使用呢?这些使用都是合法的吗?如果要变更数据内容、格式、持久化周期,又会影响谁呢?
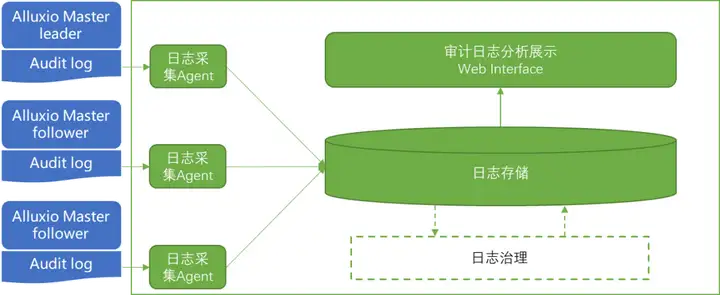
上述两个问题的答案就隐含在审计日志里面,审计日志可以完美的记录每个用户每次请求的信息,这些信息是已经发生的事实,是对管理配置的有效验证和补充。有了审计日志,要真正回答上面的两个问题,还需要一套分析系统,利用分析系统对上述问题中隐藏的各项指标进行分析和展示,审计日志分析系统的整体架构图如下:
1. Alluxio 审计日志
Alluxio的审计日志在整个系统中是数据源性质的存在。Alluxio 支持审计日志功能,Leader Master 通过 audit log 的方式记录用户的行为,从而满足审计、问题回溯分析、用户行为分析以及冷热数据分析等需求。虽然audit log只在Leader Master才真正有记录,但是因为Alluxio Master存在切换的可能,所以,任何一个Master都有可能会生成audit log,都需要收集、分析。
2. 审计日志分析系统
审计日志分析系统主要包含日志采集、日志存储、日志分析展示以及可能的日志治理几个模块。其中日志采集需要适配数据源,Alluxio的audit log是日志文件,因此一般采用贴着Alluxio Master部署采集Agent的方式实现;日志存储模块可以有多种技术实现方式,不过都要满足日志的明细查看、日志统计分析的存储和计算需要;日志的分析展示模块则负责提供可视化能力,可以基于用户的需要触发数据的查询和展示;日志治理模块主要负责通过数据清洗、转换等方式解决可能存在的数据质量问题,如果日志不存在质量问题,则可以省略此模块。
审计日志分析系统的技术方案可以有多种技术选型,常用的主要是两种:
- Flume+Hive/HDFS+Impala/Presto +自定义分析展示系统
Flume 负责实现日志采集Agent,采集 audit log 到 HDFS;Hive/HDFS+Impala/Presto负责日志的存储和查询计算;自定义分析展示系统则按需实现日志的各种分析、展示的需要。
此方案的优势在于更加灵活、开放,Hive/HDFS的存储,可以承载更加定制化的数据结构、存储格式,也可以承载更加灵活的数据治理、数据计算/分析的需要。
因为要写入Hive/HDFS,以及需要相应的数据转换等,此方案的时效性相对较差,一般用在定时批量模式下,比如小时级的分析等。
- ELK(Elasticsearch+Logstash+Kibana)
ELK是一套使用比较广的开源日志管理方案,Logstash 负责实现日志采集Agent,采集 audit log 到Elasticsearch;Elasticsearch作为非常优秀的搜索引擎,可以实现写入日志的搜索以及分析等查询计算需求;Kibana则提供日志的可视化分析能力,调用ES的相关接口实现日志的搜索以及DashBoard展示。
ELK方案的优势在于各组件都是开源的,不需要系统层面的额外开发,只需要针对日志的格式以及分析需要,进行相关的配置即可。并且,ELK的时效性更好,因为Elasticsearch同时也是一个非常好的OLAP引擎,数据写入后,即可以实现数据的各种分析需要。
同时,ELK方案也受限于固定的组件选型,Elasticsearch可以支撑很好地搜索和OLAP分析的需要,但无法支持进行一些批量分析、算法分析等,同时,如果想进行数据结构的变更,重建索引,实现也比较麻烦。
综上,两种方案有利有弊,如何选择审计日志分析系统的技术方案,一般都会结合已有平台的建设现状以及审计日志分析场景的需要,建议遵循以下几个原则:
- 充分利用已有的技术组件,尽量少引入新的技术组件。新组件的引入,会带来从资源到运维的一系列新工作量,毕竟从部署到运维监控有很多工作需要做,尽量复用现有技术体系,可以有效降低资源消耗以及运维的复杂度。
- 将审计日志的存储、分析和数据平台的整体建设融合在一起。审计日志也是一个企业/组织的非常重要的数据,特别是审计日志的分析并不仅仅是为了日志的归档和回放,而是拥有丰富分析价值的数据资产,因此,建议和数据平台的整体建设融合在一起,作为一个企业/组织的数据湖、数据仓库建设的一部分。
部署详情
- Alluxio 开启 audit log 功能
alluxio.master.audit.logging.enabled=true
2. 日志文件格式
###日志路径
alluxio_home/logs/master_audit.log
2022-09-21 06:24:11,736 INFO AUDIT_LOG - succeeded=true allowed=true ugi=root,root (AUTH=SIMPLE) ip=/172.31.19.156:54274 cmd=getFileInfo src=/default_tests_files/BASIC_NON_BYTE_BUFFER_CACHE_ASYNC_THROUGHd
st=null perm=root:root:rw-r--r-- executionTimeUs=90
2022-09-21 06:24:11,737 INFO AUDIT_LOG - succeeded=true allowed=true ugi=root,root (AUTH=SIMPLE) ip=/172.31.19.156:54274 cmd=getFileInfo src=/default_tests_files/BASIC_CACHE_ASYNC_THROUGH dst=null p
erm=root:root:rw-r--r-- executionTimeUs=82
3. 下载并配置 flume
pro.sources = s1
pro.channels = c1
pro.sinks = k1
pro.sources.s1.type = exec
pro.sources.s1.command = tail -F -c +0 /mnt/alluxio/log/master_audit.log
pro.sources.s1.interceptors = i1
pro.sources.s1.interceptors.i1.type = search_replace
#多个空格替换成 | 统一数据分割符
pro.sources.s1.interceptors.i1.searchPattern = \\s+
pro.sources.s1.interceptors.i1.replaceString = |
pro.sources.s1.interceptors.i1.charset = UTF-8
pro.channels.c1.type = memory
pro.channels.c1.capacity = 1000
pro.channels.c1.transactionCapacity = 100
pro.sinks.k1.hdfs.useLocalTimeStamp = true
pro.sinks.k1.type = hdfs
pro.sinks.k1.hdfs.path = hdfs://ip-172-31-25-105.us-west-2.compute.internal:8020/flume/daytime=%Y-%m-%d
pro.sinks.k1.hdfs.filePrefix = events-
pro.sinks.k1.hdfs.fileType = DataStream
pro.sinks.k1.hdfs.round = true
pro.sinks.k1.hdfs.roundValue = 10
pro.sinks.k1.hdfs.minBlockReplicas=1
pro.sinks.k1.hdfs.roundUnit = minute
pro.sources.s1.channels = c1
pro.sinks.k1.channel = c1
4. Hive 创建外部分区表
CREATE EXTERNAL TABLE IF NOT EXISTS auditlogs(
day string,
time string,
loglevel string,
logtype string,
reserved string,
succeeded string,
allowed string,
ugi string,
ugitype string,
ip string,
cmd string,
src string,
dst string,
perm string,
exetime string
)PARTITIONED BY (daytime string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE;
5. 将数据拷贝到hive外部表中
hdfs dfs -cp /flume/daytime=2022-09-21 /user/hive/warehouse/logsdb.db/auditlogs
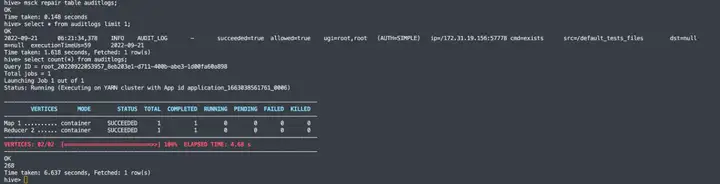
6. Hive 查询结果
注意事项:
Alluxio 审计日志格式 key=value 的形式,并且数据分割符不统一(包含一个空格符和多个空格符),需要 flume 通过自定义的 interceptors 对审计日志加工处理,去掉冗余字段,统一分割符。测试案例只用 flume 内置的 search_replace 拦截器。
延伸阅读:
Alluxio 审计日志格式: https://docs.alluxio.io/os/user/stable/cn/operation/Security.html
Flume HDFS Sink: https://flume.apache.org/FlumeUserGuide.html#hdfs-sink
Flime Interceptors: https://flume.apache.org/FlumeUserGuide.html#flume-interceptors
想要了解更多关于Alluxio的干货文章、热门活动、专家分享,可点击进入【Alluxio智库】: