前言
随着AI、大数据技术在IT运维领域的落地,AIOps成为传统运维厂商、新兴APM/NPM厂商和云服务商追捧的焦点,越来越多的用户开始了解、尝试和应用AIOps。但是,由于不同厂商的AIOps发展路径和自身产品技术实力的不同,对于AIOps的定义和宣传有很大的差异,而用户面对嘈杂的市场声音往往就像雾里看花,显得无所适从。
美国著名IT研究机构Enterprise Management Associates(EMA)副总裁Dennis Drogseth在《AIOps and IT Analytics at the Crossroads》网络研讨会上,同样被欧美用户多次问及AIOps和传统监控工具之间界限的问题,特别是AIOps和APM产品的功能差异,如:它们到底有何不同?如果已经有了APM,还需要AIOps吗?企业为什么要同时购买APM和AIOps产品?
![]()
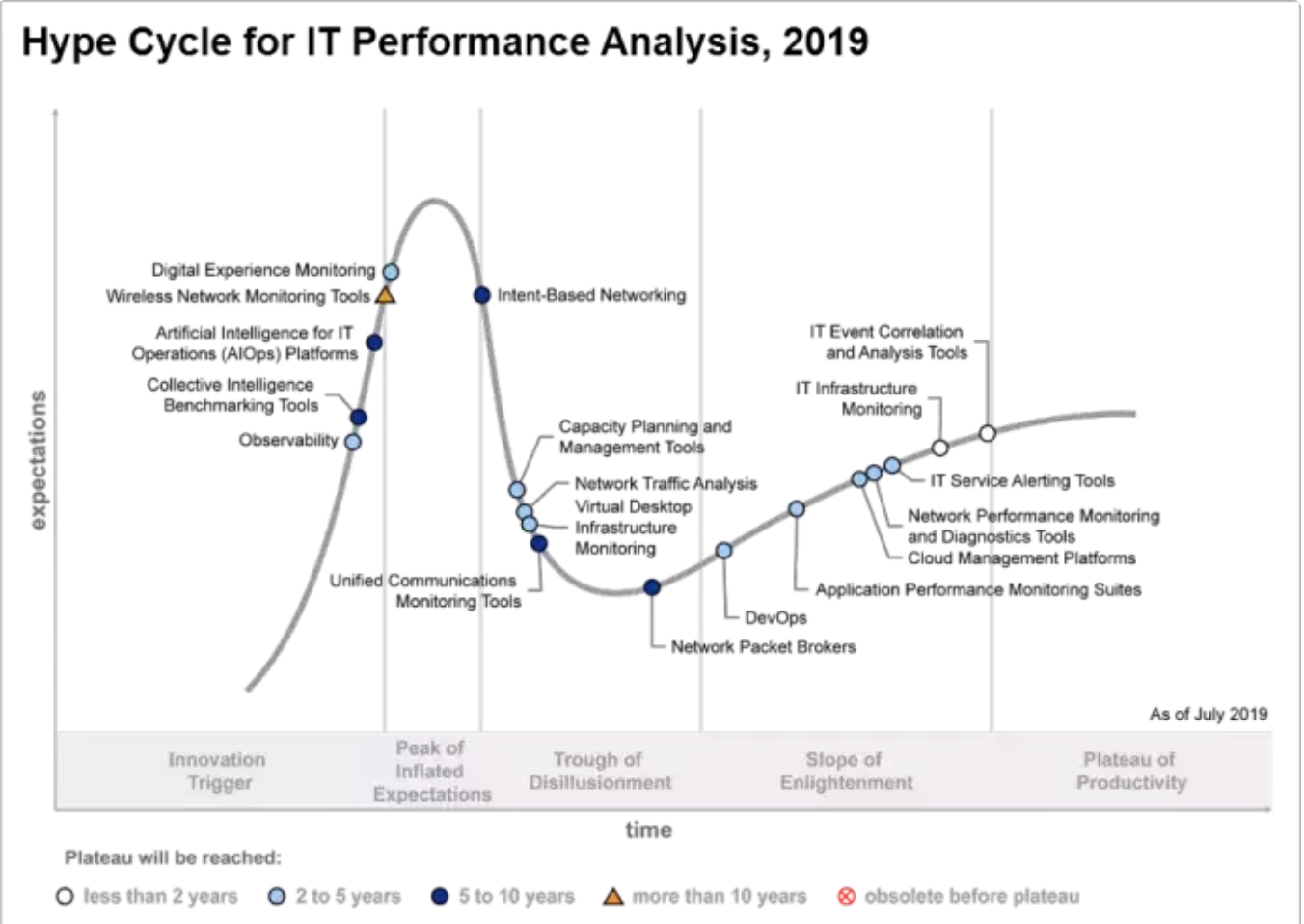
根据Gartner在2019年7月发布的IT性能分析技术成熟度曲线显示,AIOps正在从科技诞生的促动期 (Technology Trigger)进入过高期望的峰值(Peak of Inflated Expectations),而APM/NPM等技术已经进入稳步爬升的光明期 (Slope of Enlightenment),为什么还会出现AIOps和APM/NPM概念混淆?这里既有两种产品相互交叉造成的误解的因素,也有市场炒作和竞争的原因。Dennis Drogseth将在本文中为我们理清AIOps和APM的异同。
APM和AIOps的本质区别
APM的本质是监控工具。顾名思义,Application Performance Monitoring(Gartner对APM的定义)主要关注应用程序的性能,包括一些应用程序/基础架构的相互依赖性(应用拓扑)。诚然,随着APM逐渐向智能化发展,越来越多的APM产品开始在某种程度上提供故障预测能力,让APM和AIOps的边界变得有些模糊,但在更广泛的IT运维管理与分析场景中,APM的重点仍是监控,同时也是AIOps平台的最重要数据来源。
AIOps是覆盖全部7层IT技术栈的平台解决方案。AIOps作为一种运维策略,可以与企业现有的ITOM工具、基础设施监控(ITIM)、网络性能监控(NPM)、应用性能监控(APM)和数字性能监控(DPM)工具进行整合,同时AIOps的数据源还包括了IoT、配置数据、日志文件,甚至电子表格等文档信息。
此外,从大数据分析到故障预测,AIOps解决方案可利用超过13种不同的分析探索方法,用于规范和if / then风格的机器学习。EMA研究表明,目前市场上流行的AIOps平台,有超过50%能接入23种以上不同监测系统和ITOM工具。最重要的是,AIOps解决方案能够支持变更管理、容量预测、安全及SecOps、成本优化、云迁移以及DevOps和终端用户体验分析,这些是远远超出APM能力范围的。
![]()
因此,我们能够得出一个基本结论:AIOps是一种涵盖了APM、网络管理、系统管理、数据库管理和多云管理的统一管控技术,能够关联整合和主动分析来自不同数据源的数据。AIOps比APM在范围、用例和价值上更广泛,本质上与EMA定义的高级自动化分析(AIA)的目标是一致的。
APM和AIOps的相似之处
但是,如果我们把AIOps看做可以替换APM/NPM/DPM的监控工具,同样有失偏颇。事实上,APM的应用为AIOps能力的完善提供了巨大帮助。
Dennis Drogseth总结出以下四个方面:
APM通过基础设施依赖性进行应用程序管理的价值越来越高,因此APM也就成为自上而下评估服务管理和服务交付有效性的重要依据。
APM的核心能力之一是发现应用/基础架构拓扑,而应用发现和依赖关系映射(ADTD)提供了更多动态功能,这些功能同样是AIOps解决方案的基础,可以直接集成或借助APM的发现功能进行实现。
APM越来越关注终端用户体验管理(DEM),这也是追求与业务价值保持一致的AIOps解决方案不断增强的能力之一。
业务绩效指标是选择APM解决方案的重要依据,这同样是用户选择AIOps解决方案的关键参数。当然AIOps平台拥有更全面的基础指标数据,可以更加全面的评估业务价值,分析容量、成本、安全/合规性问题和其他指标。
AIOps如何实现IT统一管控
AIOps作为一种覆盖全部技术栈的统一管控技术,能够帮助企业内部所有与IT相关部门进行变革,而不仅局限于运维部门。EMA连续两年的研究显示,AIOps能够在所有造成数据孤岛的IT工具整合中发挥巨大价值。此外,AIOps与IT服务管理(ITSM)的集成也至关重要,因为这样才能帮助开发、安全团队和运营部门更有效地协同工作。
但是,企业内部应该正确认知AIOps并就目标和价值达成共识,才能实现IT的统一管控。而要发挥统一平台的最大价值,需要把AIOps的领导力、创造力和灵活性应用在IT思维和工作方式中。与CMDB/CMS计划并行,AIOps计划需要各部门主动共享数据,探索新的流程效率水平,同时提高自动化水平。此外,AIOps需要更具凝聚力和更积极主动的心态,去探索遇到的新问题。当然,最佳实践仍然适用于AIOps,与数字化转型计划保持一致,这些计划为IT转型提供了额外的砝码和价值。
虽然我们常常在市场上听到关于AIOps的错误概念,或从字面上把AIOps误解为Ops专用的运维工具平台,但希望大家通过本文清楚认识到:AIOps是激发所有IT系统价值的基础。由于AIOps在产品设计和价值输出是非常多样化的,所以它不仅是一个市场概念,更是一个创新的IT环境。因此,我们需要根据现阶段的IT成熟度和业务需求,按照优先级选择适合的场景、用例,逐步推进AIOps的落地。
开源福利
云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
点击下方地址链接,欢迎大家给 FlyFish 点赞送 Star。参与组件开发,更有万元现金等你来拿。
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址:https://gitee.com/CloudWise/fly-fish
超级体验官活动: http://bbs.aiops.cloudwise.com/d/712-flyfish
万元现金活动: http://bbs.aiops.cloudwise.com/t/Activity
微信扫描识别下方二维码,备注【飞鱼】加入AIOps社区飞鱼开发者交流群,与 FlyFish 项目 PMC 面对面交流~
![]()
作者:Dennis Drogseth
出处:https://www.apmdigest.com/apm-and-aiops-acronyms-in-conflict-or-are-they