

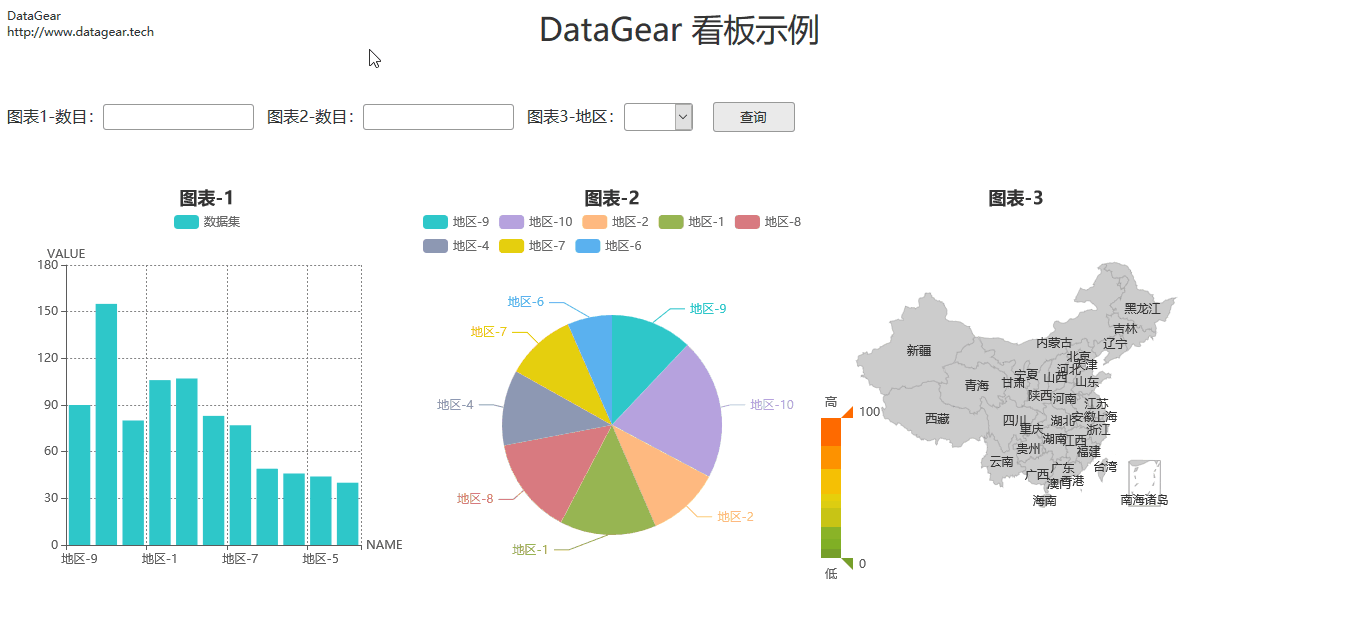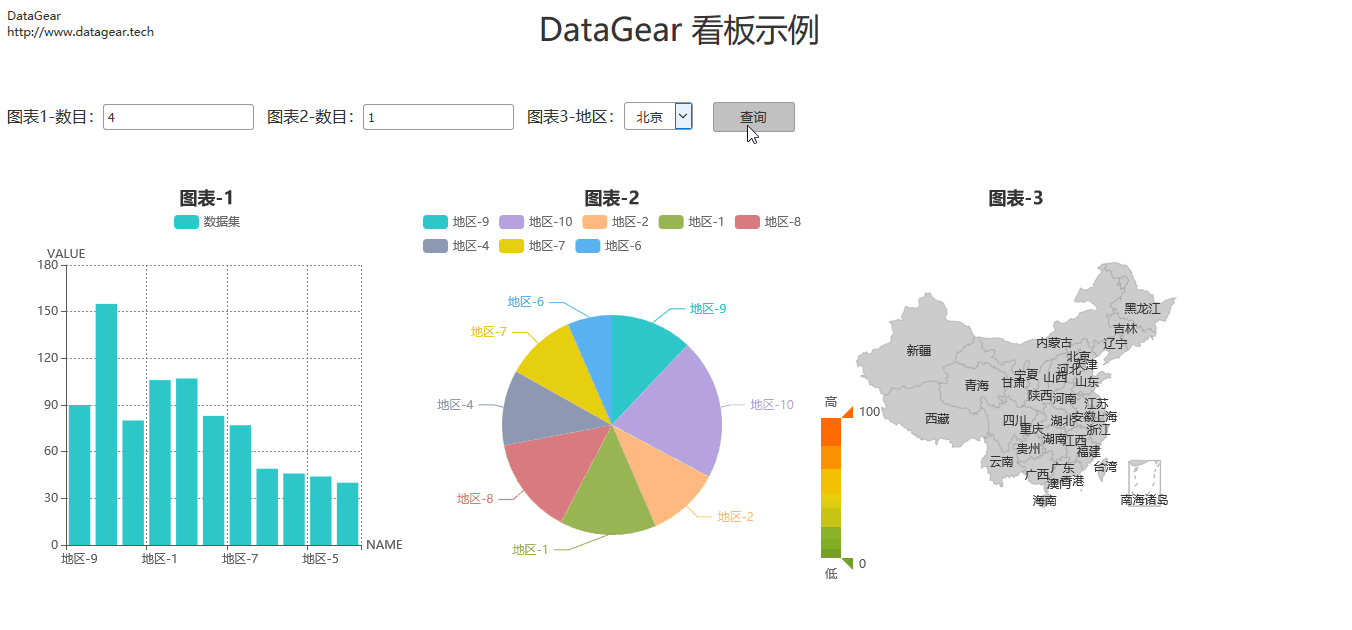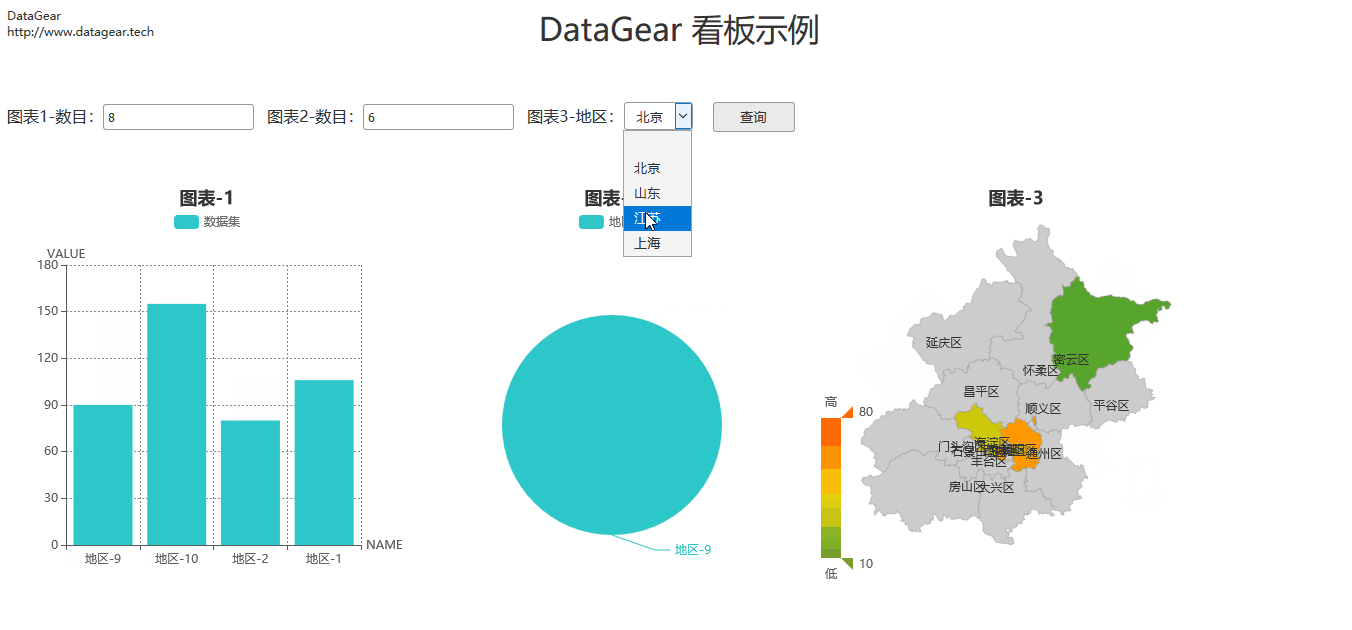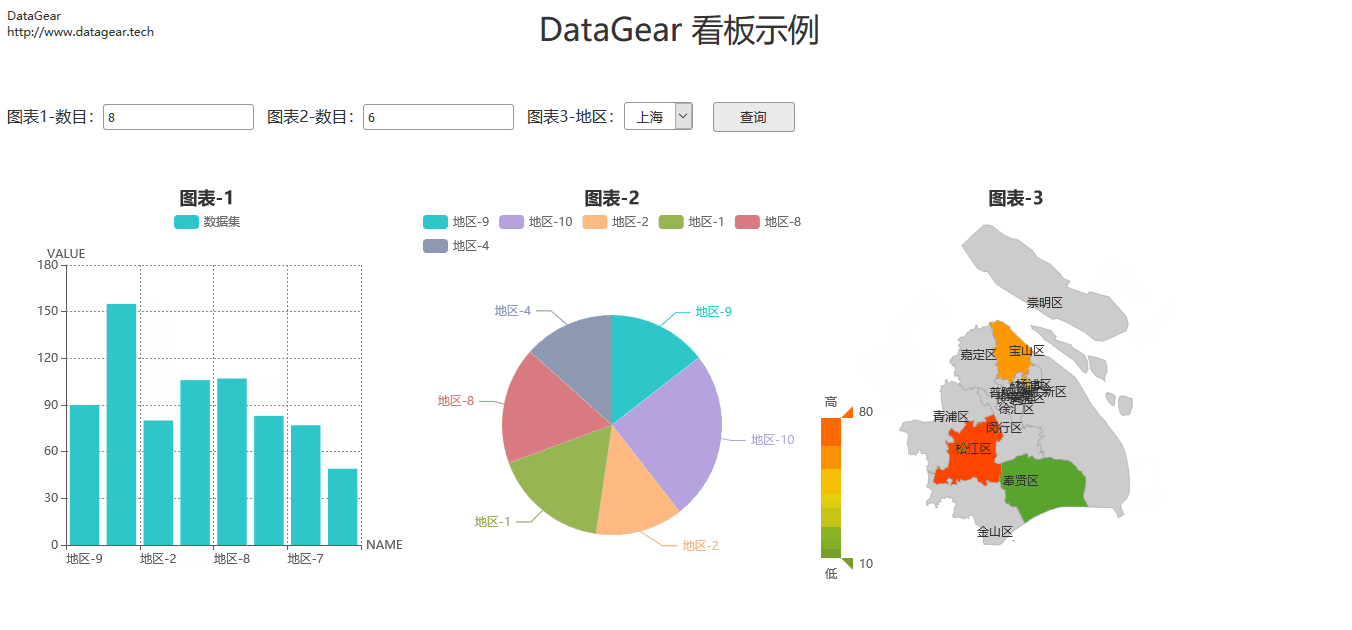

自然语言处理——文本向量化(二)
一.摘要 本次分享内容是基于上篇文本向量方法的继续,上次内容中,主要分享了文本向量化的两种方法:词袋模型表示方法和基于深度学习词向量方法。词袋模型虽然能够很简单的将词表示为向量,但会造成维度灾难,并且不能够利用到文本中词顺序等信息。NNLM模型的目标是构建一个语言概率模型,但是在nnlm模型求解的过程中,从隐藏层到输出层的权重计算是非常费时的一步。下面我们将了解下C&W模型、CBOW模型和Skip-gram模型。 二.C&W模型 C&W模型是一个以生成词向量为目标的模型。在之前的NNLM模型中我们了解到了他那难于计算的权重是一个非常大的障碍。这里的C&W模型没有采用语言模型的方式去求解词语上下文的条件概率,而是直接对n元短语打分。采用的是一种更为快速高效的获取词向量的方式。C&W模型的核心思想是:如果n元短语在语料库中出现过,那么模型就会给该短语打出较高的分数;对于在语料库中未出现过或出现次数很少的短语则会得到较低的分数。C&W模型结构图如下: 图1:C&W模型结构图 相对于整个语料库来说,C&W模型需要优化的目标函数为:...