读写分离顾名思义,就是将读操作和写操作分离开来,形成一种主备的结构,主机负责写操作,从机负责读操作。openGauss数据库组装成集群并使用JDBC连接时,支持一主多备情况下的读写分离,当URL中配置服务器地址时,可以通过URL中的属性标示来区分JDBC返回的连接是否是区分主机和备机。
读写分离一定程度上依赖主机的识别,这里会介绍openGauss数据库的自动寻主机制。openGauss数据库应用场景下,典型配置为一主两备。当主机宕机后,备机会升主,这时和旧主机相连的连接都会失效,所以为了能够让业务以最快的速度恢复使用,我们在驱动层设计一种“自动寻主”的机制,该机制可以找到主备切换后的主机,并且整个寻主过程对于上层应用来说是透明的,上层应用的开发人员不需要自动寻主的具体细节,只需做上一定适配即可实现业务的高可用。
对比PostgreSQL 的读写分离,PostgreSQL 在数据库资源占用超过85%时,查询数据库情况语句会出现失效,针对这一问题我们做了优化。
查询语句修改为
select local_role, db_state from pg_stat_get_stream_replications();
有效的避免了PostgreSQL 在读写分离方面出现的问题。
hostRecheckSeconds参数,Integer类型,因为JDBC尝试连接主机后会保存主机状态:连接成功或连接失败,所以这个参数就是用于设置在主机状态发生更改时再次检查主机状态的时间段,默认的时间是10秒。
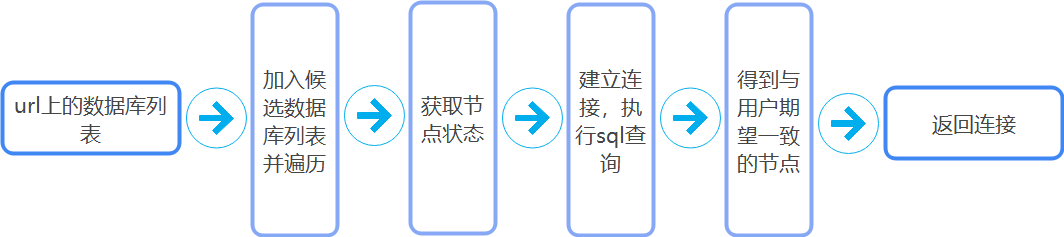
第一步,设置参数开启targetServerType=master。
第二步,判断输入的主机列表是否已经加入了候选主机列表中,如果不存在hostStatusMap中并且更新时间间隔超过10s同时HostStatus状态也和现在一致,这时直接加入候选主机列表。
第三步,对列表进行遍历查找对应的节点信息,如果找到了,通过konwnStatus查看状态是否一致,一致就执行sql查询语句,之后更新全局变量hostStatusMap及局部变量konwnStatus中存储。
第四步,当前操作的节点状态如果与用户选择的节点状态一致则返回主机连接,之后用户可以根据连接进行读或者写操作。
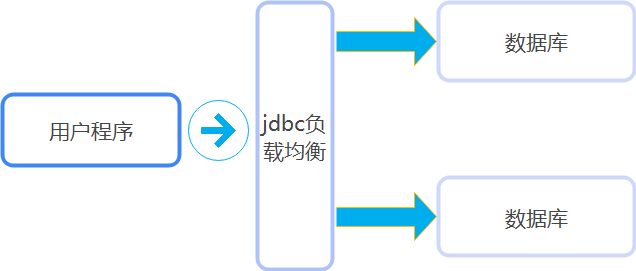
jdbc负载均衡简单来说就是将所有的连接均衡的分摊到多个数据库上面,借此达到减轻单个数据库的数据处理压力从而提高整体的性能的一种方式。但是要注意一点,openGauss的负载均衡是能进行读操作使用,所以在只读时开启时是没有问题的,但如果有写操作的话,因为负载均衡不会考虑主备的区别,所以会让从机进行读操作,这时会报错。
负载均衡是现在很常用的均衡每个服务器性能的处理手段,像我们常见的Nginx的负载均衡,很少会有人在驱动上面直接进行负载均衡。从实际的效果的来看,在开启负载均衡后整体的性能并没有下降,但是因为连接打到了多个不同的数据库上面,整体的处理效率得到了显著的提升。虽然看上去和传统的负载均衡达到的效果差不多,但是对比传统的通过额外的一台机器做负载均衡比起来,我们有着独特的优势。首先我可以通过配置参数开启负载均衡并设置 我们想要的主机列表,这一点上面操作就会比较简单。其次节约了成本,不在需要另外一个机器专门进行负载均衡。并且还具备故障隔离,当某个数据库故障后,负载均衡可以感知到故障,并自动停止向故障数据库节点转发请求。
loadBalanceHosts:在默认模式下(禁用),顺序连接URL中指定的多个数据库。如果启用,则使用洗牌算法从候选主机列表中随机选择一个主机建立连接。
这里使用了collections类中自带的shuffle方法来实现随机的建立连接,名称叫做洗牌算法,所以它就和洗牌一样会把原有的数据库列表顺序打乱,就像洗牌一样。方法的实现大概就是从前往后遍历列表重复的随机选择一个元素交换到当前遍历到的位置。等遍历一遍结束后,我们就会得到一个乱序的数据库列表。
优点:调用现有的Java接口,实现简单并且效果显著。
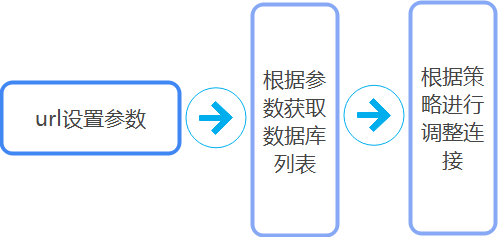
第一步,设置参数,在url后面拼接loadBalanceHosts参数,其为true时会开启负载均衡,默认是不开启的。
第二步,JDBC连接数据库,通过解析url获取可连接的数据库列表
第三步,根据洗牌算法获得的数据库列表来,用来调整接下来要连接的数据库。
openGauss开源社区官方网站:
https://opengauss.org
openGauss组织仓库:
https://gitee.com/opengauss
openGauss镜像仓库:
https://github.com/opengauss-mirror
微信公众号|openGauss
微信社群小助手|openGauss-bot
本文分享自微信公众号 - openGauss(openGauss)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。