1、线程模型
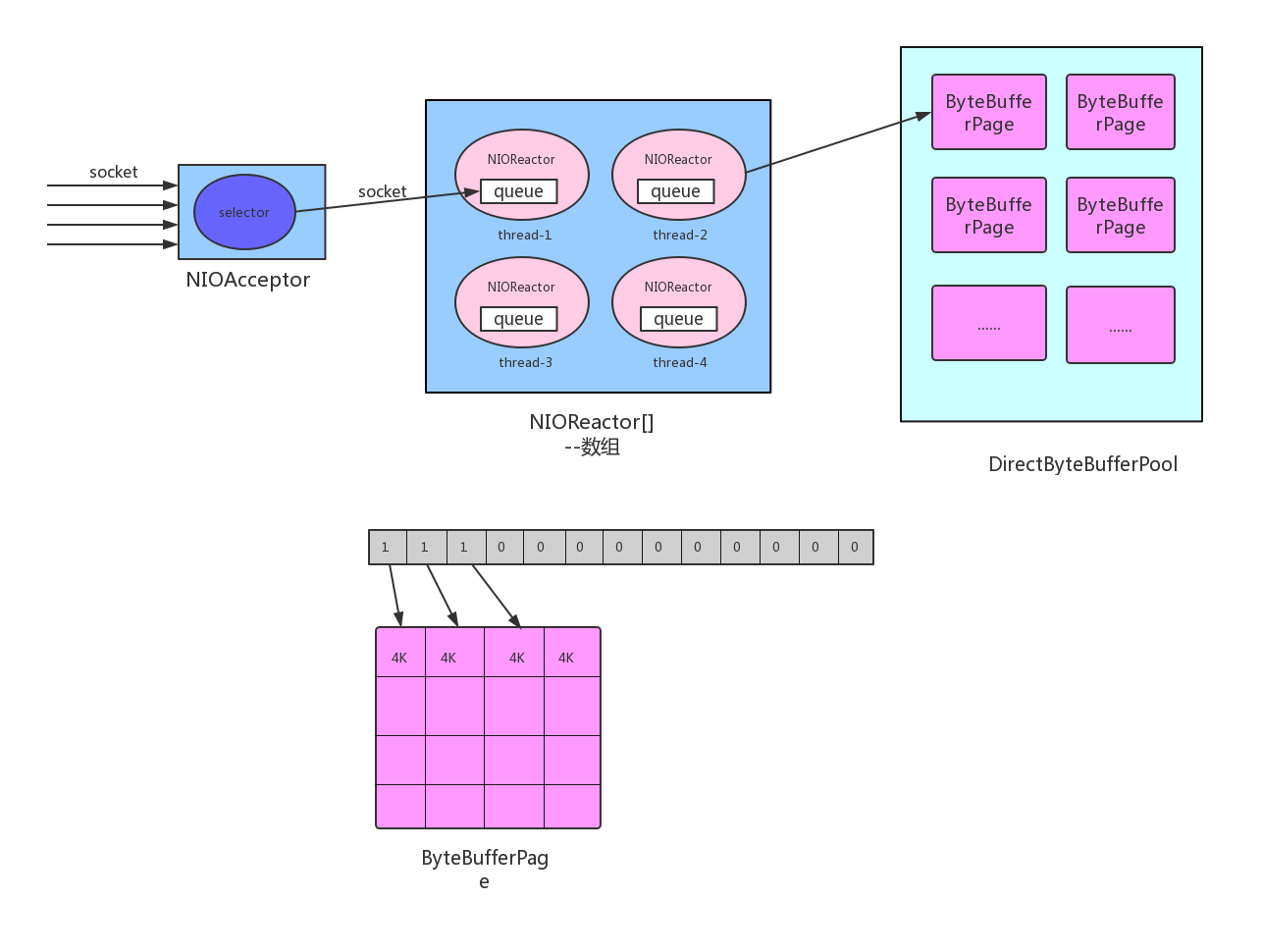
1.1、Reactor多线程
![]()
1.2、处理流程
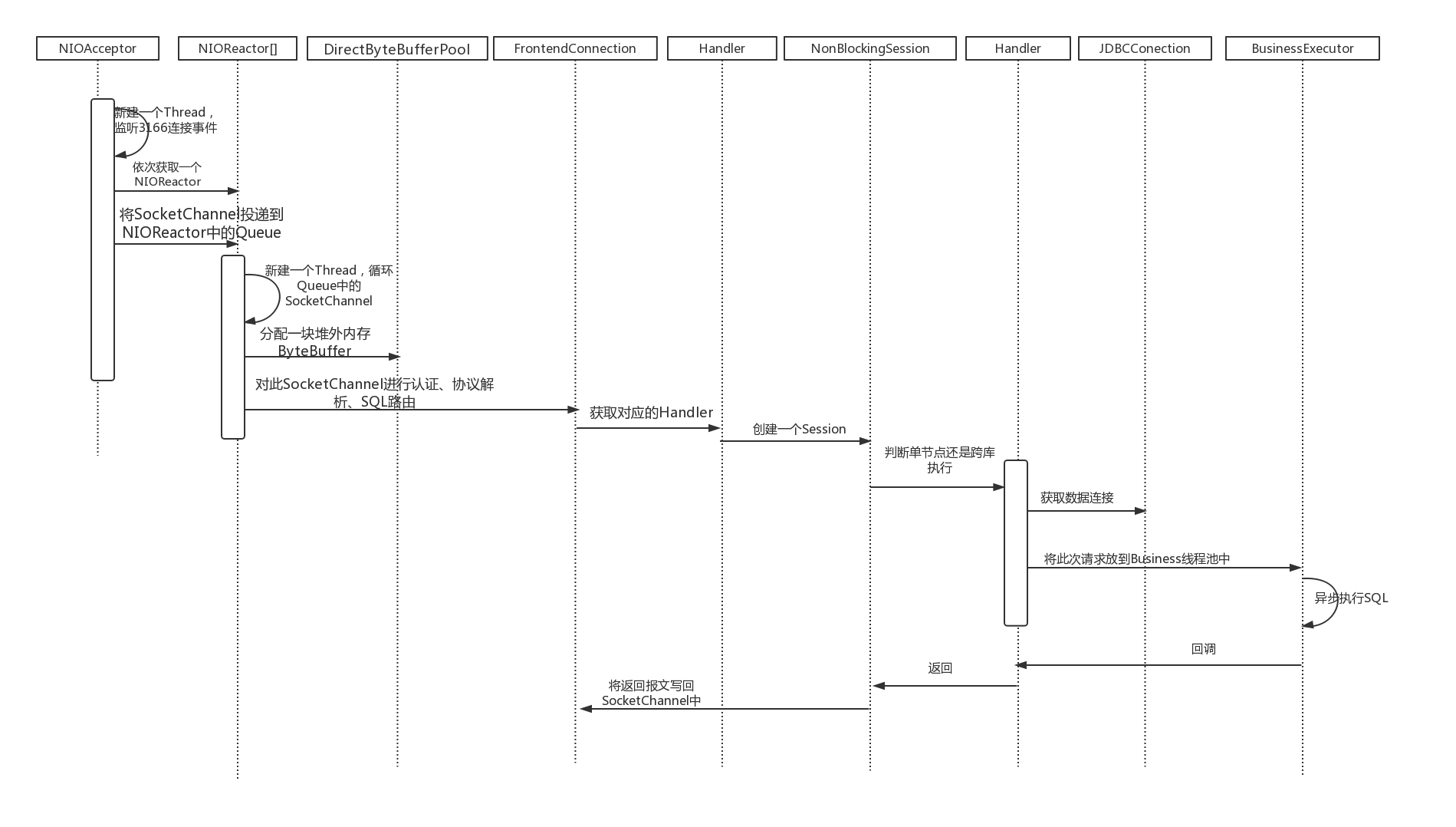
1) NIOAccetpor中的Selector只接收SocketChannel的accept事件;
2) 从NIOReactor[]数组中依次获取一个NIOReactor;
3) 将此SocketChannel放到对应NIOReactor中的Queue中;
4) 由NIOReactor新建的Thread,不断循环将Queue中的SocketChannel取出并注册到当前NIOReactor关联的Selector上面;
5) 不断循环Selector返回的SelectionKey进行数据读取;
6) 从DirectByteBufferPoll中先分配一块内存(trunk=4k);
7) 读取SocketChannel中的数据,如果一个trunk可以读完数据则进行认证、mysql协议解析,encode、并调用对应的handler处理。否则计算报文的长度根据size分配足够的内存,并将之前读取的数据copy进来,继续读取直至读完。
1.3、流程图
![]()
1.4、优点
1) 一个NIOAcceptor(聚合了一个Selector,一个线程)可以处理成百上千的客户端连接,每当有一个新的客户端连接时,就从NIOReactor[]数组中顺序获取一个NIOReactor,当达到数组上限时重新返回0,基本保障了NIOReactor间的负载均衡。
2) 通过NIOReactor[]线程组实现了串行化线程水平并行执行,线程之间没有交集,充分利用多核提升并行处理能力。
3) NIOReactor[]线程组互不影响,起到故障隔离作用。
4) 报文的读取、解析、编码、以及后续Handler的执行,始终都在一个NIOReactor 的IO线程上面操作,避免了线程上下文切换和并发修复的风险。
1.5、缺点
1) 维护性差:IO线程和handler业务线程为同一个线程,一旦handler处理(认证、解析、PS渲染、SQL解析、SQL路由)出现延迟,这些延迟毛刺定位难度很大。
1.6、思考
1、为什么不使用主从Reactor?
2、为什么或怎么可以把IO线程和业务Handler分开?
2、内存管理
DirectByteBufferPool启动时向系统申请固定数量(PROCESSORS * 20),大小(512 * 4096)一样的连续内存空间用于创建ByteBufferPage,ByteBufferPage被切分为固定大小的trunk(4096)块。通过BitSet位图进行内存的分配和回收,1代表已使用,0代表未使用,在每个ByteBufferPage上面通过AtomicBoolean实现并发控制。
2.1、分配流程
1) 根据size计算需要的trunk数量,整块连续分配,size<4K则分配一个trunk;
2) 根据上次分配的Page+1,依次从ByteBufferPage[]中取出一个进行分配,报错分配分配相对均衡,同时一定程度上缓解了线程间的竞争。
3) 分配时先对ByteBufferPage通过AtomicBoolean进行加锁,找到符合数量(BitSet为0)的连续空间,通过ByteBuffer的limit()和position()以及slice()进行分配,同时将对应的BitSet位图置为1,如果找不到则去下个Page中分配;
4) 如果都没有空间,则再分配异常,再没有则使用HeapByteBuffer。
2.2、优点
1) DirectByteBuffer的分配和释放比堆内慢10-20倍,进行池化可以快速分配内存;
2) 池化技术可以使对象复用,降低GC频率。
3) trunk块大小相同,BitSet位图内存分配和回收简单;
4) 做为全局数据,通过设置ByteBufferPage[]数量,缓解多线程环境下的锁竞争;
2.3、缺点
1) 一次性申请完成之后,不能动态扩展;
2) 固定大小内存,管理的粒度很粗,碎片较大;
2.4、Netty内存管理
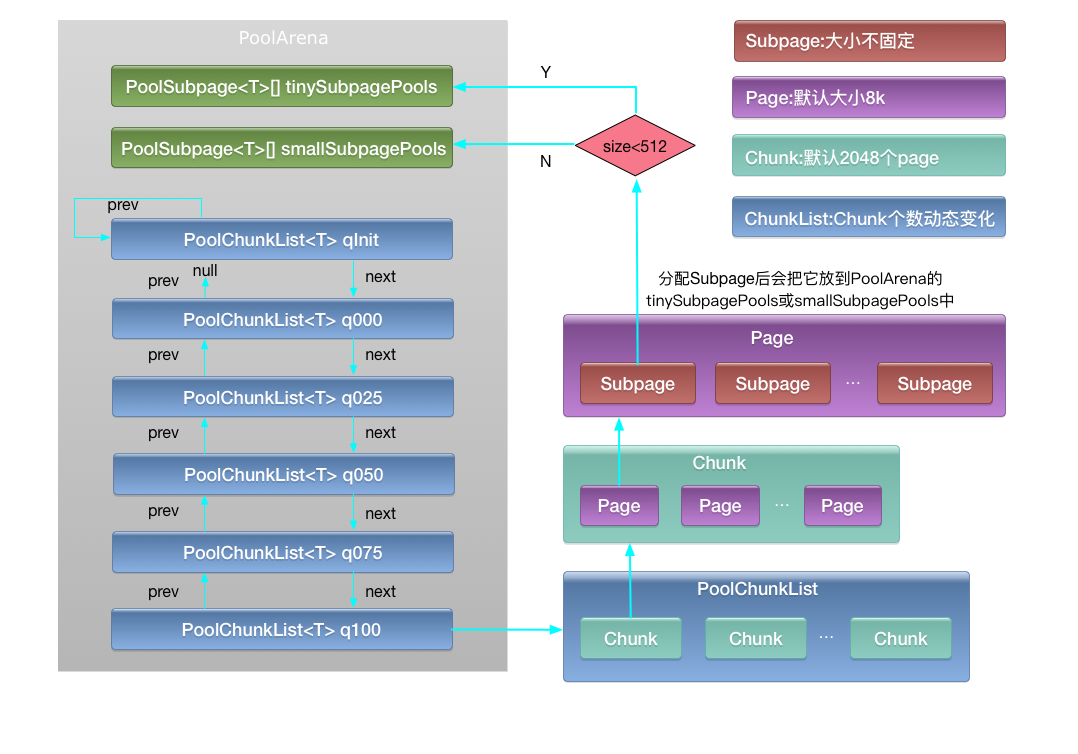
Netty内存池的层级结构主要分为,Arena,ChunkList、Chunk、Page、SubPage
Arena:代表一个内存区域,内存池由Arena[]数组组成,分配时每个线程按照轮训策略选择一个Arena分配。一个Arena由两个PoolSubPage和ChunkList双向链表组成。
ChunkList:由多个Chunk组成的双向链表,可动态变化。
Chunk:每个Chunk由默认由2048个Page组成。
Page:大小固定,默认8K,通过完全二叉树管理Page的分配和释放。
SubPage:大小不固定,又分为tinySubPage,区间[16,512)和smallSubPage,区间[512,4096),通过位图分配和释放。
![]()
![]()
3、Druid SQL Parser
代码结构:
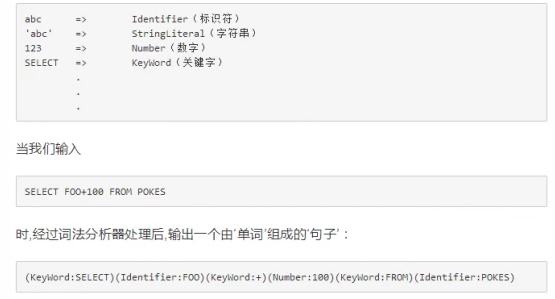
1、Parser:将SQL转换成AST(抽象语法树),包括Parser(语法解析)和Lexer(词法解析)
2、AST(Abstract Syntax Tree)
3、Visitor:遍历AST的工具
4、执行流程:词法解析(SQL词库) -> 语法解析(校验是否符合语法逻辑,如from 后面要跟表名) -> 输出AST
![]()
![]()
4、连接池
4.1、定时任务
1) 后端连接检测:SQL执行超时(300s)检查、Idle检查;
2) 前端连接检测:Idle检查(默认30min);
3) 后端连接健康心跳检测:连接是否正常(被对端关闭,网络断开重连等),维持最小连接;
4) 数据节点DataHost心跳检测:检测datasource是否可用;
5) 全局表一致性检测:数据量是否一致;
5、优化和未来
5.1、优化
1) 聚焦而不是膨胀,核心功能和业务需求之前的平滑;
2) 提升统一内存池管理效率,缓解多线程分配时的锁竞争,减少内存碎片;
3) 杂乱的ScheduledExecutorService定时任务(10个)打乱了NIOReactor串行化设计思想,造成了没有必要的线程上下文切换,可统一管理这些定时任务,参考Netty中的时间轮定时任务;
5.2、未来
1、多维度、立体化、全方位监控体系;
2、便捷、易用的管控运维平台;
3、分布式数据库(动态扩容、Percolator分布式事务);
Ref:
https://blog.csdn.net/zhousenshan/article/details/82432805
https://www.jianshu.com/p/8d894e42b6e6
https://www.jianshu.com/p/2652686a43eb