Redis实现了不定长压缩前缀的radix tree,用在集群模式下存储slot对应的的所有key信息。本文将详述在Redis中如何实现radix tree。
核心数据结构
raxNode是radix tree的核心数据结构,其结构体如下代码所示:
typedef struct raxNode {
uint32_t iskey:1;
uint32_t isnull:1;
uint32_t iscompr:1;
uint32_t size:29;
unsigned char data[];
} raxNode;
-
iskey:表示这个节点是否包含key
- 0:没有key
- 1:表示从头部到其父节点的路径完整的存储了key,查找的时候按子节点iskey=1来判断key是否存在
- isnull:是否有存储value值,比如存储元数据就只有key,没有value值。value值也是存储在data中
- iscompr:是否有前缀压缩,决定了data存储的数据结构
- size:该节点存储的字符个数
-
data:存储子节点的信息
-
- iscompr=0:非压缩模式下,数据格式是:
[header strlen=0][abc][a-ptr][b-ptr][c-ptr](value-ptr?),有size个字符,紧跟着是size个指针,指向每个字符对应的下一个节点。size个字符之间互相没有路径联系。
- iscompr=1:压缩模式下,数据格式是:
[header strlen=3][xyz][z-ptr](value-ptr?),只有一个指针,指向下一个节点。size个字符是压缩字符片段
Rax Insert
以下用几个示例来详解rax tree插入的流程。假设j是遍历已有节点的游标,i是遍历新增节点的游标。
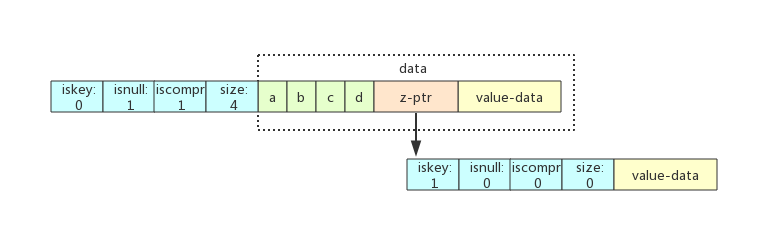
场景一:只插入abcd
z-ptr指向的叶子节点iskey=1,使用了压缩前缀。
![]()
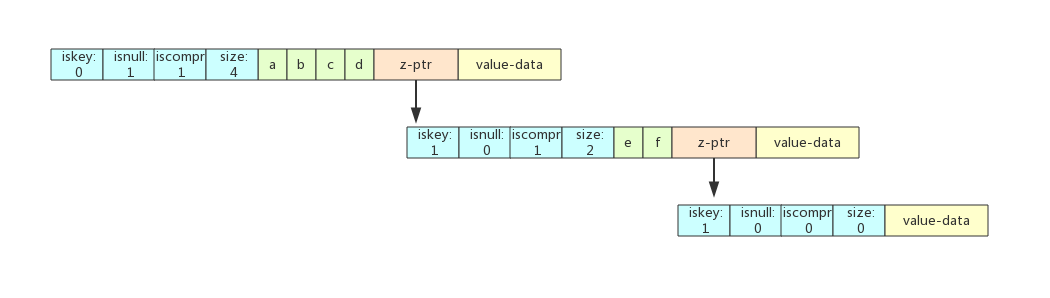
场景二:在abcd之后插入abcdef
从abcd父节点的每个压缩前缀字符比较,遍历完所有abcd节点后指向了其空子节点,j = 0, i < len(abcded)。
查找到abcd的空子节点,直接将ef赋值到子节点上,成为abcd的子节点。ef节点被标记为iskey=1,用来标识abcd这个key。ef节点下再创建一个空子节点,iskey=1来表示abcdef这个key。
![]()
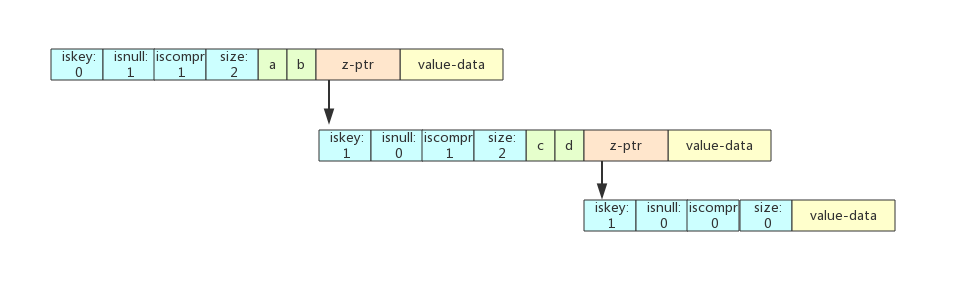
场景三:在abcd之后插入ab
ab在abcd能找到前两位的前缀,也就是i=len(ab),j < len(abcd)。
将abcd分割成ab和cd两个子节点,cd也是一个压缩前缀节点,cd同时被标记为iskey=1,来表示ab这个key。
cd下挂着一个空子节点,来标记abcd这个key。
![]()
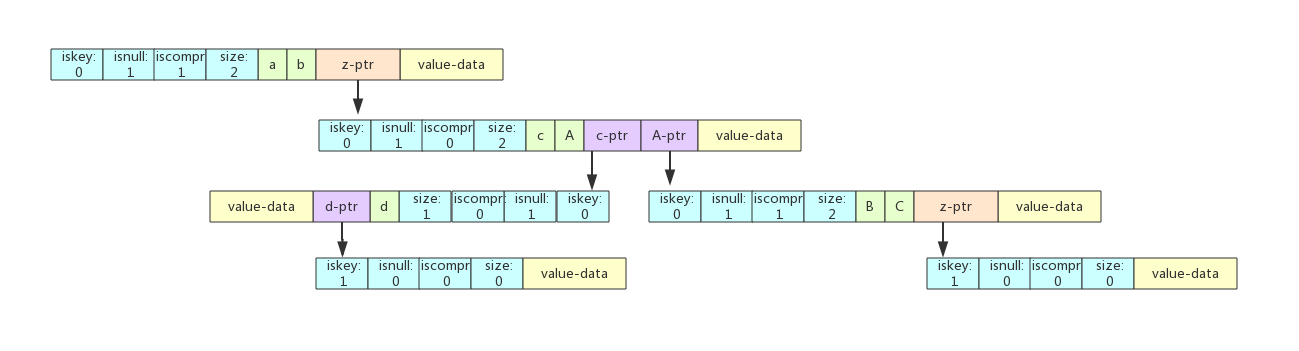
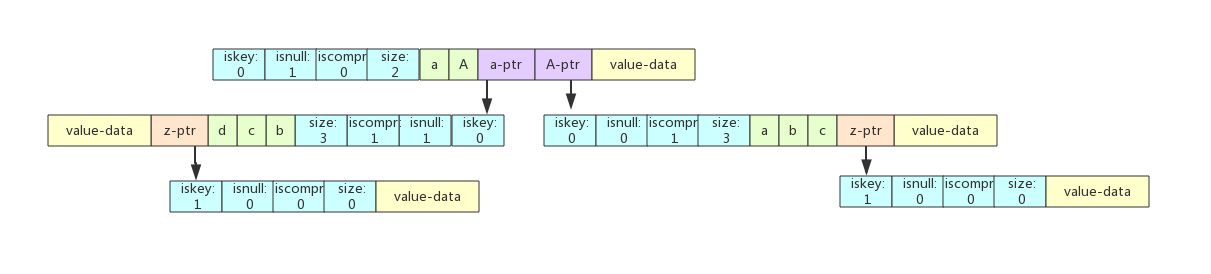
场景四:在abcd之后插入abABC
abcABC在abcd中只找到了ab这个前缀,即i < len(abcABC),j < len(abcd)。这个步骤有点复杂,分解一下:
- step 1:将abcd从ab之后拆分,拆分成ab、c、d 三个节点。
- step 2:c节点是一个非压缩的节点,c挂在ab子节点上。
- step 3:d节点只有一个字符,所以也是一个非压缩节点,挂在c子节点上。
- step 4:将ABC 拆分成了A和BC, A挂在ab子节点上,和c节点属于同一个节点,这样A就和c同属于父节点ab。
- step 5:将BC作为一个压缩前缀的节点,挂在A子节点下。
- step 6:d节点和BC节点都挂一个空子节点分别标识abcd和abcABC这两个key。
![]()
场景五:在abcd之后插入Aabc
abcd和Aabc没有前缀匹配,i = 0,j = 0。
将abcd拆分成a、bcd两个节点,a节点是一个非压缩前缀节点。
将Aabc拆分成A、abc两个节点,A节点也是一个非压缩前缀节点。
将A节点挂在和a相同的父节点上。
同上,在bcd和abc这两个节点下挂空子节点来分别表示两个key。
![]()
Rax Remove
删除
删除一个key的流程比较简单,找到iskey的节点后,向上遍历父节点删除非iskey的节点。如果是非压缩的父节点并且size > 1,表示还有其他非相关的路径存在,则需要按删除子节点的模式去处理这个父节点,主要是做memove和realloc。
合并
删除一个key之后需要尝试做一些合并,以收敛树的高度。
合并的条件是:
- iskey=1的节点不能合并
- 子节点只有一个字符
- 父节点只有一个子节点(如果父节点是压缩前缀的节点,那么只有一个子节点,满足条件。如果父节点是非压缩前缀的节点,那么只能有一个字符路径才能满足条件)
结束语
云数据库Redis版(ApsaraDB for Redis)是一种稳定可靠、性能卓越、可弹性伸缩的数据库服务。基于飞天分布式系统和全SSD盘高性能存储,支持主备版和集群版两套高可用架构。提供了全套的容灾切换、故障迁移、在线扩容、性能优化的数据库解决方案。欢迎各位购买使用:云数据库 Redis 版
作者:羽洵
原文链接
本文为云栖社区原创内容,未经允许不得转载。