想要应用 AI 技术进行产业智能化升级,又担心缺乏计算机、数学等理论基础?
AI 算法训练完成,优化部署上线又是一个趟不过去的大坑?
别担心,今天就教大家应用一个开源项目——飞桨全流程开发工具 PaddleX,快速开发 AI 算法并快速部署实现业务上线, 搭上人工智能的产业浪潮!
这个开源项目三次登上 GitHub Daily 全球趋势榜,2.7k 星标;不需要数学基础,不需要编程大牛,只要下载就可以快速开发 AI 算法模型并投产应用;还有工业制造、安防巡检、能源电力、卫星遥感、智能交通等行业海量的示例项目!所有代码全公开,让你可以一键利用云资源就可以运行,换数据就可以进行任务迁移,超低代码实现多环境、多硬件部署,实在是业界良心,“飘香四溢”啊~
![]()
小遍赶紧识趣的送上传送门,建议小伙伴们 Star 收藏后再慢慢研究:
https://github.com/PaddlePaddle/PaddleX
那这个项目到底有什么过人之处,又具体能做些什么呢?下面就展开来给大家详细介绍一下。
01. 能做什么?
图像分类、目标检测、语义分割、实例分割任务全覆盖!还提供工业制造、安防巡检、能源电力、卫星遥感、智能交通等十多个行业的实际场景详细的示例工程!
![]()
![]()
-
工业制造:瑕疵检测、目标定位、智能抓取、自动分拣、产品计数;
-
安防巡检:输电线路及基站本体异物检测,表计等设备检测及读数,异常喷洒、火情检测;
-
智慧城市:车辆、行人、交通标志检测,卫星遥感图像识别,建筑物、农作物、道路等检测、分割及变化检测及面积计算;
-
智慧零售:商品检测、商标检测及计数;
-
智慧医疗领域:CT 影像分割、肺炎筛查、眼底病变筛查。
02. 怎么用?
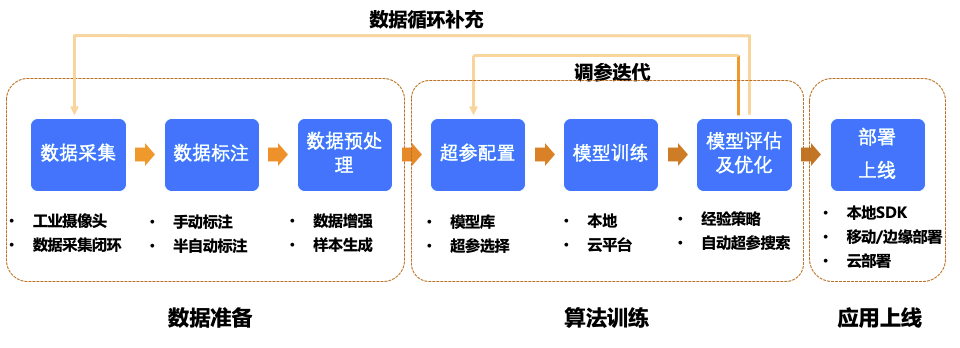
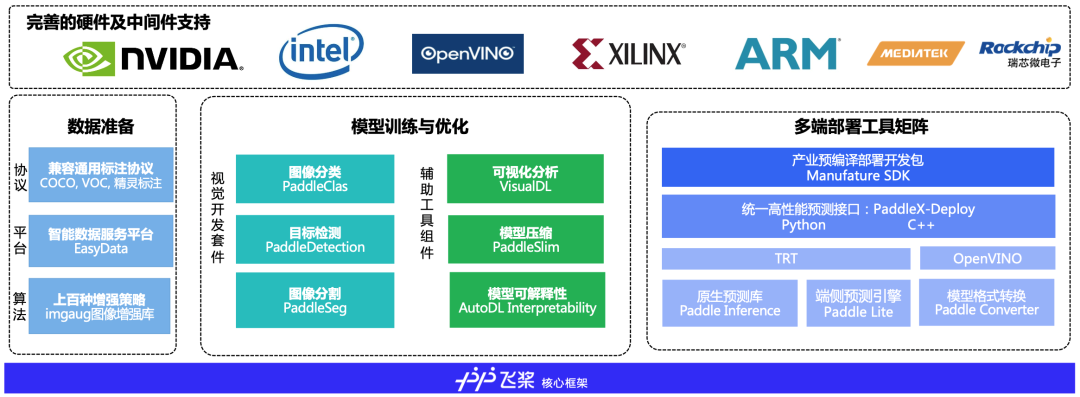
PaddleX 提供了从数据预处理、超参配置、模型训练与评估、模型多端部署等深度学习产业项目开发全流程全面覆盖。
![]()
数据准备
PaddleX 适配产业标准数据标注格式,支持常用标注工具,如:Labelme、精灵标注、EasyData 等。原生匹配数据格式转化方法。同时提供多种数据增强的策略,适配了 imgaug 图像增强库,支持上百种数据增强操作,有效缓解小样本训练难题。
模型训练
为了满足用户的多种需求,PaddleX 提供多种开发方式。
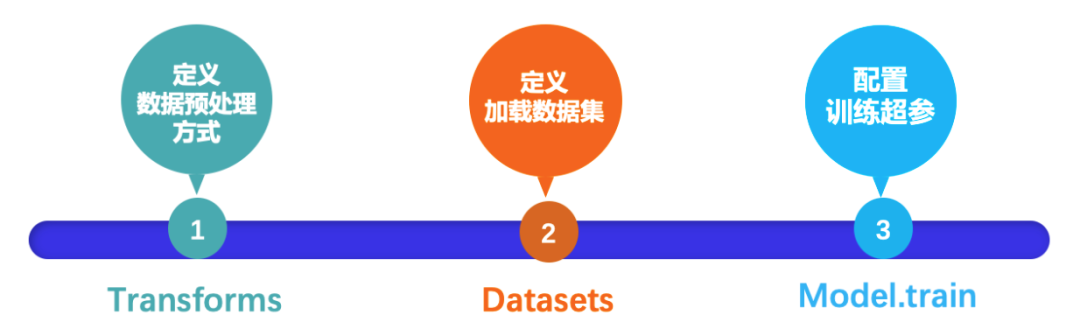
>> 本地 API:
pip install 一键安装, 3个 API 即可完成深度学习算法训练!与【图形化开发界面】开发流程相同,提供极简的 API,功能更丰富、开发更灵活、开源易集成。
![]()
![]()
>> RESTful API:
不论你将训练框架部署在哪里, 只需要启动 RESTful API 服务,即可在本地调起开发界面调动远程服务器的资源进行训练。
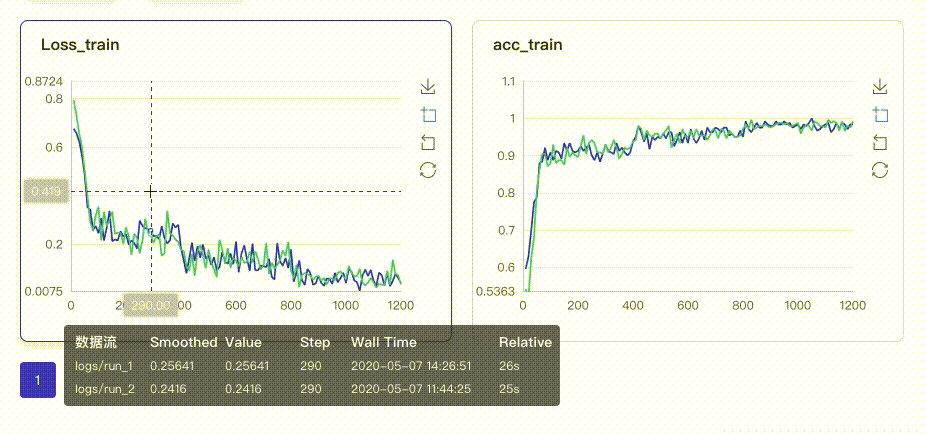
>> 训练过程可视化分析:
集成可视化分析工具 VisualDL 的能力,直观的将准确率、loss、PR 曲线、数据样本分布情况等用图表的方式呈现,使你清晰了解算法训练过程,加速调参。
![]()
>> 一键完成模型量化、裁剪:
通过极简的方式即可快速进行算法的裁剪、量化,有效对算法进行体积、参数量的减小,速度、精度的提升。
模型部署
为了满足工业级别的部署,PaddleX 更是提供了全方位的部署服务:支持 Python、C++、C#等多语言部署;提供本地预测、服务化预测、边缘预测部署等多种解决方案;适配业界常用的 CPU、GPU(包括 NVIDIA Jetson)、树莓派等硬件。
>> 多硬件、多环境快速部署上线:
PaddleX Deploy 模块:适配业界常用的 CPU、GPU(包括 NVIDIA Jetson)、树莓派等硬件;支持 PaddleClas PaddleDetection PaddleSeg 三个套件的模型的部署;支持用户采用 OpenVINO 或 TensorRT 进行推理加速;完备支持工业最常使用的 Windows 系统,且提供 C#语言进行部署的方式!
![]()
![]()
>> 独特的 PaddleX Manufacture SDK:
编译预测库太复杂?需要多个算法串联?PaddleX Manufacture SDK 提供工业级多端多平台部署加速的预编译飞桨部署开发套件(SDK),通过修改业务逻辑配置文件,就可以快速完成推理部署。覆盖单个算法以及多个算法串联形式。极低代码,极高效率。再也不用在不同环境下分别打包!
![]()
PaddleX 图形化产品即将正式发布
PaddleX 图形化产品将集成数据标注与模型部署功能,为用户提供高效便捷的可视化操作界面,完成本地化一站式模型开发。产品名称为飞桨 EasyDL - 桌面版,邀测链接如下:
ai.baidu.com/easydl/paddle
应用教程
>> 亲妈级示例工程及文档:
针对产业落地每一细节,提供详细的完善的操作指南,以及基于产业真实场景的示例工程。覆盖从数据标注、数据预处理、单模型训练调优、多模型串联,到多端部署、推理加速、可视化结果呈现等全流程!
![]()
![]()
不论你是 AI 算法开发者、软件系统工程师、硬件工程师还是学生;不管你对什么视觉领域任务有需求,都可以应用 PaddleX 提供的深度学习算法快速进行模型开发,并在实际的硬件、系统上部署上线。
还不 Star 等什么?这么优秀的项目不值得支持一下嘛?
项目链接:
https://github.com/PaddlePaddle/PaddleX