【GaintPandaCV导语】 最近动态卷积开始有人进行了研究,也有不少的论文发表(动态卷积论文合集https://github.com/kaijieshi7/awesome-dynamic-convolution),但是动态卷积具体的实现代码却很少有文章给出。本文以微软发表在CVPR2020上面的文章为例,详细的讲解了动态卷积实现的难点以及如何动分组卷积巧妙的解决。希望能给大家以启发。
![]()
这篇文章也同步到知乎平台,链接为:https://zhuanlan.zhihu.com/p/208519425
论文的题目为《Dynamic Convolution: Attention over Convolution Kernels》
paper的地址arxiv.org/pdf/1912.0345
代码实现地址,其中包含一维,二维,三维的动态卷积;分别可以用于实现eeg的处理,正常图像的处理,医疗图像中三维脑部的处理等等(水漫金山)。github.com/kaijieshi7/D,大家觉得有帮助的话,可以点个星星。
一句话描述下文的内容:将 ![]() 的大小视为分组卷积里面的组的大小进行动态卷积。如
的大小视为分组卷积里面的组的大小进行动态卷积。如 ![]() ,那么就转化成
,那么就转化成 ![]() ,
, ![]() 的分组卷积。
的分组卷积。
简单回顾
这篇文章主要是改进传统卷积,让每层的卷积参数在推理的时候也是随着输入可变的,而不是传统卷积中对任何输入都是固定不变的参数。(由于本文主要说明的是代码如何实现,所以推荐给大家一个讲解论文的连接:Happy:动态滤波器卷积|DynamicConv)
![]() 推理的时候:红色框住的参数是固定的,黄色框住的参数是随着输入的数据不断变化的。
推理的时候:红色框住的参数是固定的,黄色框住的参数是随着输入的数据不断变化的。
对于卷积过程中生成的一个特征图 ![]() ,先对特征图做几次运算,生成
,先对特征图做几次运算,生成 ![]() 个和为
个和为 ![]() 的参数
的参数 ![]() ,然后对
,然后对 ![]() 个卷积核参数进行线性求和,这样推理的时候卷积核是随着输入的变化而变化的。(可以看看其他的讲解文章,本文主要理解怎么写代码)
个卷积核参数进行线性求和,这样推理的时候卷积核是随着输入的变化而变化的。(可以看看其他的讲解文章,本文主要理解怎么写代码)
下面是attention代码的简易版本,输出的是[ ![]() ,
, ![]() ]大小的加权参数。
]大小的加权参数。 ![]() 对应着要被求和的卷积核数量。
对应着要被求和的卷积核数量。
class attention2d(nn.Module):
def __init__(self, in_planes, K,):
super(attention2d, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_planes, K, 1,)
self.fc2 = nn.Conv2d(K, K, 1,)
def forward(self, x):
x = self.avgpool(x)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x).view(x.size(0), -1)
return F.softmax(x, 1)
下面是文章中 ![]() 个卷积核求和的公式。
个卷积核求和的公式。
![]()
其中 ![]() 是输入,
是输入, ![]() 是输出;可以看到
是输出;可以看到 ![]() 进行了两次运算,一次用于求注意力的参数(用于生成动态的卷积核),一次用于被卷积。
进行了两次运算,一次用于求注意力的参数(用于生成动态的卷积核),一次用于被卷积。
但是,写代码的时候如果直接将 ![]() 个卷积核求和,会出现问题。接下来我们先回顾一下Pytorch里面的卷积参数,然后描述一下可能会出现的问题,再讲解如何通过分组卷积去解决问题。
个卷积核求和,会出现问题。接下来我们先回顾一下Pytorch里面的卷积参数,然后描述一下可能会出现的问题,再讲解如何通过分组卷积去解决问题。
Pytorch卷积的实现
我会从维度的视角回顾一下Pytorch里面的卷积的实现(大家也可以手写一下,几个重点:输入维度、输出维度、正常卷积核参数维度、分组卷积维度、动态卷积维度、attention模块输出维度)。
输入:输入数据维度大小为[![]() ,
, ![]() ,
, ![]() ,
, ![]() ]。
]。
输出:输出维度为[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ]。
]。
卷积核:正常卷积核参数维度为[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ]。(在Pytorch中,2d卷积核参数应该是固定这种维度的)
]。(在Pytorch中,2d卷积核参数应该是固定这种维度的)
这里我们可以注意到,正常卷积核参数的维度是不存在 ![]() 的。因为对于正常的卷积来说,不同的输入数据,使用的是相同的卷积核,卷积核的数量与一次前向运算所输入的
的。因为对于正常的卷积来说,不同的输入数据,使用的是相同的卷积核,卷积核的数量与一次前向运算所输入的 ![]() 大小无关(相同层的卷积核参数只需要一份)。
大小无关(相同层的卷积核参数只需要一份)。
可能会出现的问题
这里描述一下实现动态卷积代码的过程中可能因为 ![]() 大于1而出现的问题。
大于1而出现的问题。
对于图中attention模块最后softmax输出的 ![]() 个数,他们的维度为[
个数,他们的维度为[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],可以直接.view成[
],可以直接.view成[ ![]() ,
, ![]() ],紧接着
],紧接着 ![]() 作用于
作用于 ![]() 卷积核参数上(形成动态卷积)。
卷积核参数上(形成动态卷积)。
问题所在:正常卷积,一次输入多个数据,他们的卷积核参数是一样的,所以只需要一份网络参数即可;但是对于动态卷积而言,每个输入数据用的都是不同的卷积核,所以需要 ![]() 份网络参数,不符合Pytorch里面的卷积参数格式,会出错。
份网络参数,不符合Pytorch里面的卷积参数格式,会出错。
看下维度运算[ ![]() ,
, ![]() ]*[
]*[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],生成的动态卷积核是[
],生成的动态卷积核是[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],不符合Pytorch里面的规定,不能直接参与运算(大家可以按照这个思路写个代码看看,体会一下,光看可能感觉不出来问题),最简单的解决办法就是
],不符合Pytorch里面的规定,不能直接参与运算(大家可以按照这个思路写个代码看看,体会一下,光看可能感觉不出来问题),最简单的解决办法就是 ![]() 等于1,不会出现错误,但是慢啊!!!
等于1,不会出现错误,但是慢啊!!!
总之, ![]() 大于1会导致中间卷积核参数不符合规定。
大于1会导致中间卷积核参数不符合规定。
分组卷积以及如何通过分组卷积实现 ![]() 大于1的动态卷积
大于1的动态卷积
一句话描述分组卷积:对于多通道的输入,将他们分成几部分各自进行卷积,结果concate。
组卷积过程用废话描述:对于输入的数据[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],假设
],假设 ![]() 为
为 ![]() ,那么分组卷积就是将他分为两个
,那么分组卷积就是将他分为两个 ![]() 为
为 ![]() 的数据(也可以用其他方法分),那么维度就是[
的数据(也可以用其他方法分),那么维度就是[ ![]() , 5x2 ,
, 5x2 , ![]() ,
, ![]() ],换个维度换下视角,[
],换个维度换下视角,[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],那么
],那么 ![]() 为2的组卷积可以看成
为2的组卷积可以看成 ![]() 的正常卷积。(如果还是有点不了解分组卷积,可以阅读其他文章仔细了解一下。)
的正常卷积。(如果还是有点不了解分组卷积,可以阅读其他文章仔细了解一下。)
巧妙的转换:上面将 ![]() 翻倍即可将分组卷积转化成正常卷积,那么反向思考一下,将
翻倍即可将分组卷积转化成正常卷积,那么反向思考一下,将 ![]() 变为1,是不是可以将正常卷积变成分组卷积?
变为1,是不是可以将正常卷积变成分组卷积?
我们将 ![]() 大小看成分组卷积中
大小看成分组卷积中 ![]() 的数量,令
的数量,令 ![]() 所在维度直接变为
所在维度直接变为 ![]() !!!直接将输入数据从[
!!!直接将输入数据从[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ]变成[1,
]变成[1, ![]() ,
, ![]() ,
, ![]() ],就可以用分组卷积解决问题了!!!
],就可以用分组卷积解决问题了!!!
详细描述实现过程:将输入数据的维度看成[1, ![]() ,
, ![]() ,
, ![]() ](分组卷积的节奏);卷积权重参数初始化为[
](分组卷积的节奏);卷积权重参数初始化为[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],attention模块生成的维度为[
],attention模块生成的维度为[ ![]() ,
, ![]() ],直接进行正常的矩阵乘法[
],直接进行正常的矩阵乘法[ ![]() ,
, ![]() ]*[
]*[ ![]() ,
, ![]() *
*![]() *
* ![]() *
* ![]() ]生成动态卷积的参数,生成的动态卷积权重维度为[
]生成动态卷积的参数,生成的动态卷积权重维度为[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],将其看成分组卷积的权重[
],将其看成分组卷积的权重[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ](过程中包含reshape)。这样的处理就完成了,输入数据[
](过程中包含reshape)。这样的处理就完成了,输入数据[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],动态卷积核[
],动态卷积核[ ![]() ,
, ![]() ,
, ![]() ,
, ![]() ],直接是
],直接是 ![]() 的分组卷积,问题解决。
的分组卷积,问题解决。
具体代码如下:
class Dynamic_conv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, K=4,):
super(Dynamic_conv2d, self).__init__()
assert in_planes%groups==0
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.groups = groups
self.bias = bias
self.K = K
self.attention = attention2d(in_planes, K, )
self.weight = nn.Parameter(torch.Tensor(K, out_planes, in_planes//groups, kernel_size, kernel_size), requires_grad=True)
if bias:
self.bias = nn.Parameter(torch.Tensor(K, out_planes))
else:
self.bias = None
def forward(self, x):#将batch视作维度变量,进行组卷积,因为组卷积的权重是不同的,动态卷积的权重也是不同的
softmax_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x.view(1, -1, height, width)# 变化成一个维度进行组卷积
weight = self.weight.view(self.K, -1)
# 动态卷积的权重的生成, 生成的是batch_size个卷积参数(每个参数不同)
aggregate_weight = torch.mm(softmax_attention, weight).view(-1, self.in_planes, self.kernel_size, self.kernel_size)
if self.bias is not None:
aggregate_bias = torch.mm(softmax_attention, self.bias).view(-1)
output = F.conv2d(x, weight=aggregate_weight, bias=aggregate_bias, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups*batch_size)
else:
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
return output
完整的代码在github.com/kaijieshi7/D,大家觉得有帮助的话,求点个星星。
纸上得来终觉浅,绝知此事要躬行。试下代码,方能体会其中妙处。
对文章有疑问或者想加入交流群,欢迎添加BBuf微信
![]()
为了方便各位获取公众号获取资料,可以加入QQ群获取资源,更欢迎分享资源
![]()

 的大小视为分组卷积里面的组的大小进行动态卷积。
的大小视为分组卷积里面的组的大小进行动态卷积。 ,那么就转化成
,那么就转化成  ,
,  的分组卷积。
的分组卷积。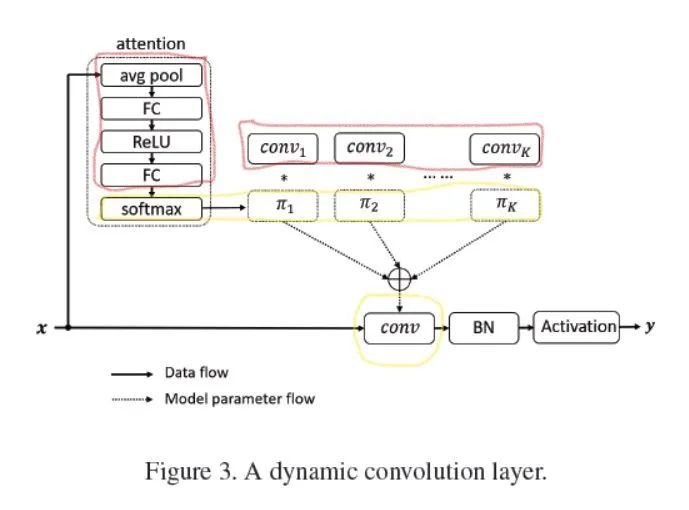
 ,先对特征图做几次运算,生成
,先对特征图做几次运算,生成  个和为
个和为  的参数
的参数  ,然后对
,然后对 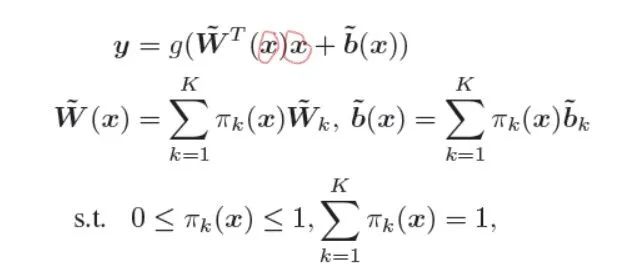
 是输出;可以看到
是输出;可以看到  ,
,  ,
,  ]。
]。 ,
,  ,
,  ,那么分组卷积就是将他分为两个
,那么分组卷积就是将他分为两个  的数据(也可以用其他方法分),那么维度就是[
的数据(也可以用其他方法分),那么维度就是[  ,
,  为2的组卷积可以看成
为2的组卷积可以看成  ,
,  ,
,  ,
,  ,
,  ,
,  的分组卷积,问题解决。
的分组卷积,问题解决。

