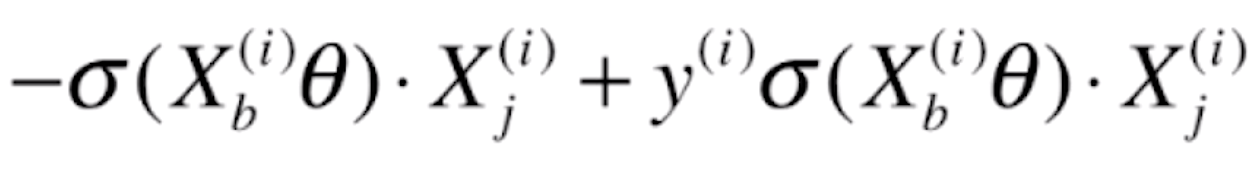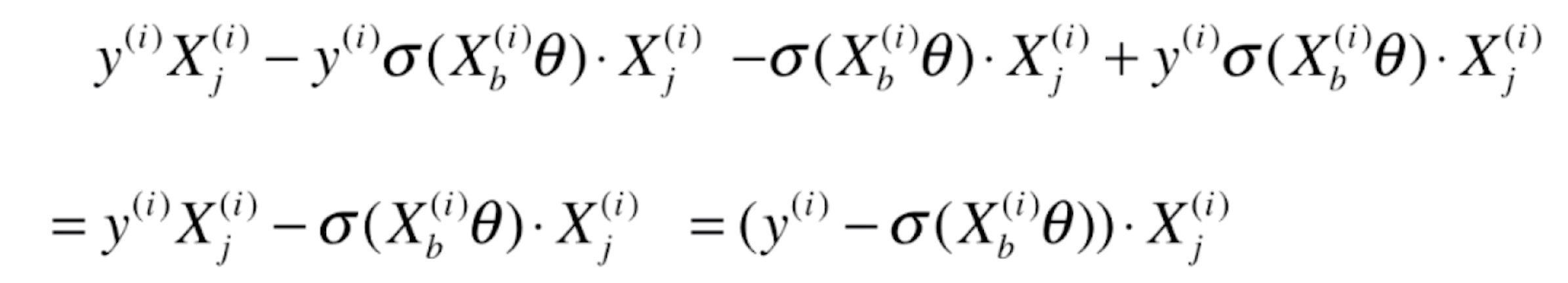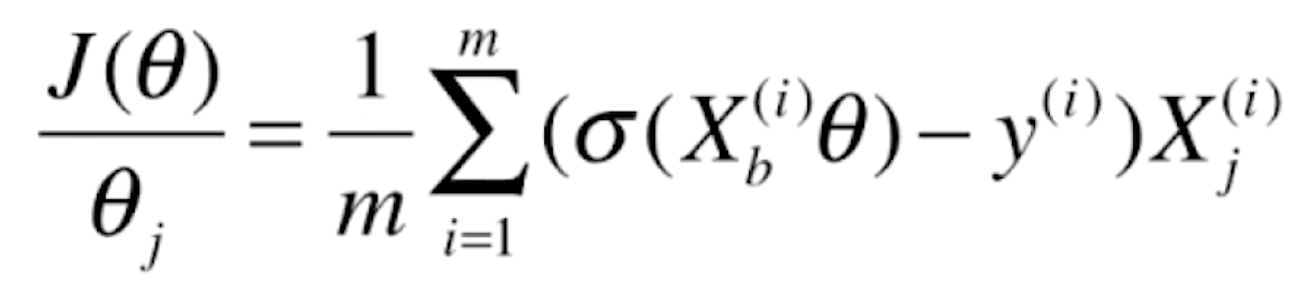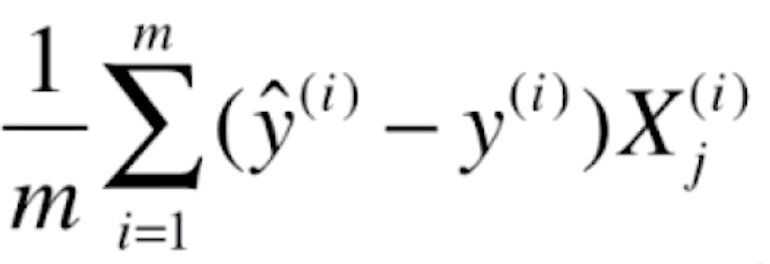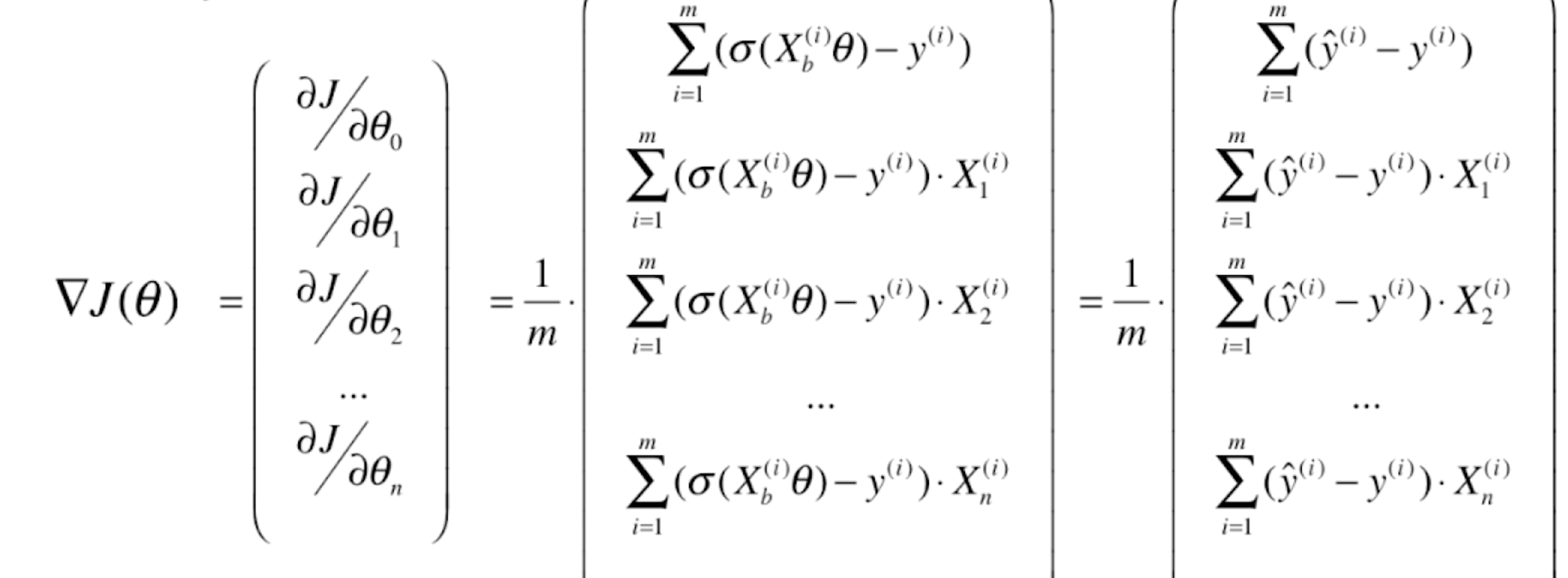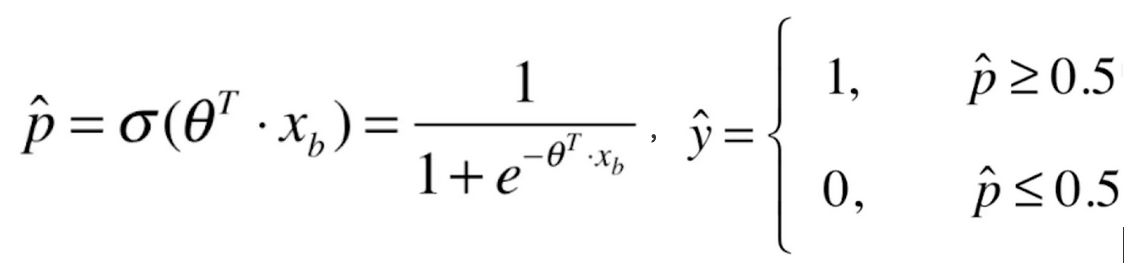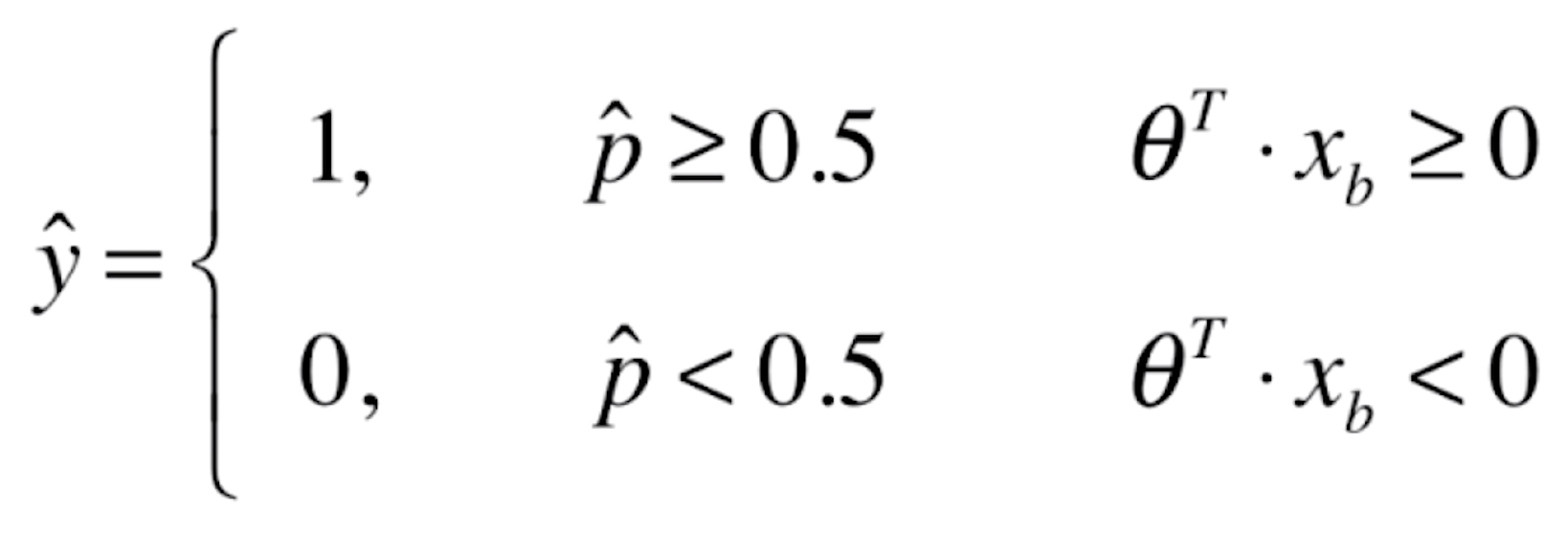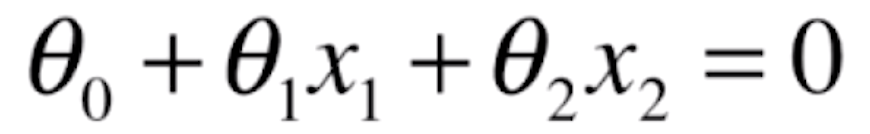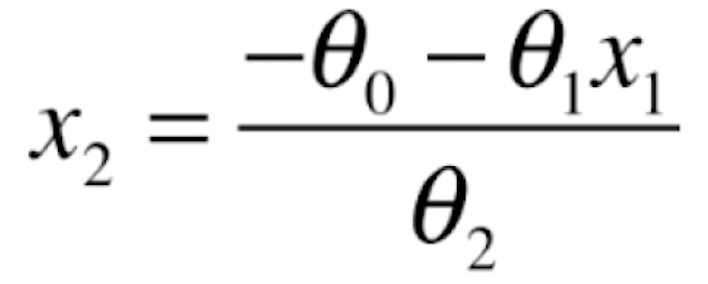接机器学习算法整理(二)
逻辑回归
什么是逻辑回归(Logistic Regression)
逻辑回归是解决分类问题的,那回归问题怎么解决分类问题呢?将样本的特征和样本发生的概率联系起来,概率是一个数。
对于机器学习的本质就是![]() ,进来一个x,经过f(x)的运算,就得到一个预测值
,进来一个x,经过f(x)的运算,就得到一个预测值![]() ,对于之前无论是线性回归也好,多项式回归也好,看我们要预测的是什么,如果我们要预测的是房价,那么
,对于之前无论是线性回归也好,多项式回归也好,看我们要预测的是什么,如果我们要预测的是房价,那么![]() 的值就是房价。如果我们要预测成绩,那么
的值就是房价。如果我们要预测成绩,那么![]() 的值就是成绩。但是在逻辑回归中,这个
的值就是成绩。但是在逻辑回归中,这个![]() 的值是一个概率值。
的值是一个概率值。
![]() ,进来一个x,经过f(x)的运算,会得到一个概率值
,进来一个x,经过f(x)的运算,会得到一个概率值![]() 。之后我们根据这个概率值
。之后我们根据这个概率值![]() 来进行分类
来进行分类
![]()
如果![]() 有50%以上的概率,我们就让
有50%以上的概率,我们就让![]() 的值为1;如果
的值为1;如果![]() 在50%以下概率的话,我们就让
在50%以下概率的话,我们就让![]() 的值为0。这里的1和0在实际的场景中可能代表不同的意思,比如说1代表恶性的肿瘤患者,0代表良性的肿瘤患者;或者说1代表银行发给某人信用卡有一定的风险,0代表没有风险等等。
的值为0。这里的1和0在实际的场景中可能代表不同的意思,比如说1代表恶性的肿瘤患者,0代表良性的肿瘤患者;或者说1代表银行发给某人信用卡有一定的风险,0代表没有风险等等。
逻辑回归既可以看作是回归算法,也可以看作是分类算法。如果我们不进行最后的一步根据![]() 的值进行分类的操作,那么它就是一个回归算法。我们计算的是根据样本的特征来拟合计算出一个事件发生的概率。比如给我一个病人的信息,我计算出他患有恶性肿瘤的概率。给我一个客户的信息,我计算出发给他信用卡产生风险的概率。我们根据这个概率进一步就可以进行分类。不过通常我们使用逻辑回归还是当作分类算法用,只可以解决二分类问题。如果对于多分类问题,逻辑回归本身是不支持的。当然我们可以使用一些其他的技巧进行改进,使得我们用逻辑回归的方法,也可以解决多分类的问题。但是对于KNN算法来说,它天生就可以支持多分类的问题。
的值进行分类的操作,那么它就是一个回归算法。我们计算的是根据样本的特征来拟合计算出一个事件发生的概率。比如给我一个病人的信息,我计算出他患有恶性肿瘤的概率。给我一个客户的信息,我计算出发给他信用卡产生风险的概率。我们根据这个概率进一步就可以进行分类。不过通常我们使用逻辑回归还是当作分类算法用,只可以解决二分类问题。如果对于多分类问题,逻辑回归本身是不支持的。当然我们可以使用一些其他的技巧进行改进,使得我们用逻辑回归的方法,也可以解决多分类的问题。但是对于KNN算法来说,它天生就可以支持多分类的问题。
逻辑回归使用一种什么方式可以得到一个事件概率的值?对于线性回归来说,![]() 它的
它的![]() 值域是(-∞,+∞)的。对于线性回归来说它可以求得一个任意的值。但是对于概率来说,它的值域只能是[0,1],所以我们直接使用线性回归的方式,没办法在这个值域内。为此,我们的解决方案就是将线性回归的预测值,放入一个函数内
值域是(-∞,+∞)的。对于线性回归来说它可以求得一个任意的值。但是对于概率来说,它的值域只能是[0,1],所以我们直接使用线性回归的方式,没办法在这个值域内。为此,我们的解决方案就是将线性回归的预测值,放入一个函数内![]() ,使得其值域在[0,1]之间,这样就获得了我们需要的概率
,使得其值域在[0,1]之间,这样就获得了我们需要的概率![]() 。
。
那么我们的![]() 函数是什么呢?
函数是什么呢?
![]()
现在我们用代码来看一下这个函数的图像
import numpy as np
import matplotlib.pyplot as plt
if __name__ == "__main__":
def sigmoid(t):
return 1 / (1 + np.exp(-t))
x = np.linspace(-10, 10, 500)
y = sigmoid(x)
plt.plot(x, y)
plt.show()
运行结果
![]()
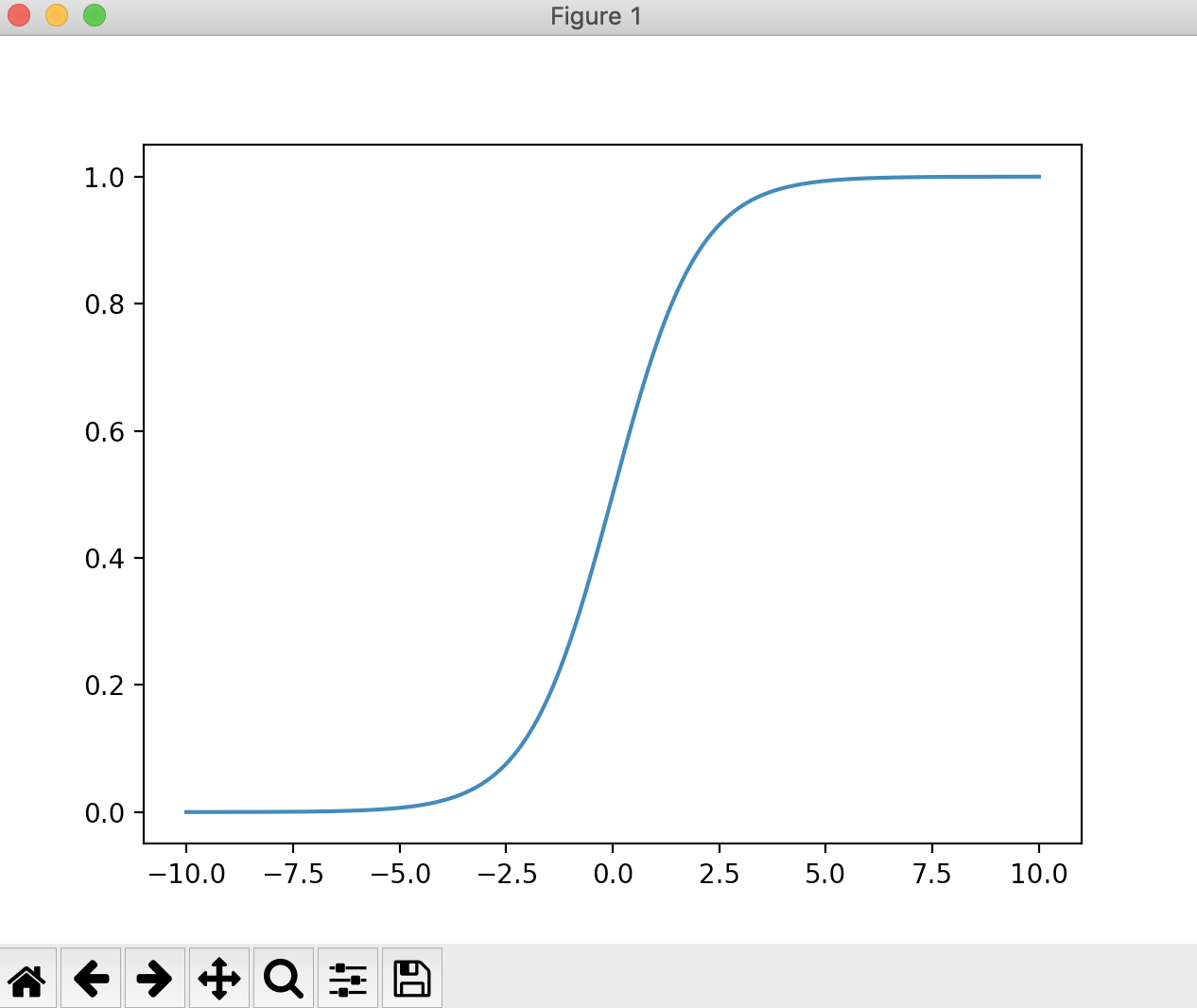
根据这根曲线,我们可以看到它的最左端趋近于0,但是达不到0,最右端趋近于1,但是达不到1。说明这根曲线的值域是(0,1),这是因为![]() =0,
=0,![]() =1。当我们画上纵轴
=1。当我们画上纵轴
![]()
我们可以看到,当t>0时,p>0.5;t<0时,p<0.5。
那么将我们线性回归的预测值代入该函数后就变成了
![]() ,
,![]()
现在我们已经知道了逻辑回归的基本原理,现在的问题就是:对于给定的样本数据集X,y,我们如何找到参数θ,使得用这样的方式,可以最大程度获得样本数据集X,对应分类出y?
逻辑回归的损失函数
我们先来看一下线性回归的损失函数![]() ,而
,而![]() ,
,![]() 是真值。我们只需要找到让这个损失函数最小的θ值就好了。对于逻辑回归来说,它的预测值
是真值。我们只需要找到让这个损失函数最小的θ值就好了。对于逻辑回归来说,它的预测值![]() 要么是1,要么是0,而我们是根据估计出来的
要么是1,要么是0,而我们是根据估计出来的![]() ,它代表一个概率,来决定
,它代表一个概率,来决定![]() 到底是1还是0,它分成了两类,相应的逻辑回归的损失函数也相应的分成了两类。如果真值y=1,那么p越小,我们估计出来的
到底是1还是0,它分成了两类,相应的逻辑回归的损失函数也相应的分成了两类。如果真值y=1,那么p越小,我们估计出来的![]() 就越有可能是0,那么我们的损失(cost)就越大;如果真值y=0,那么p越大,我们估计出来的
就越有可能是0,那么我们的损失(cost)就越大;如果真值y=0,那么p越大,我们估计出来的![]() 就越有可能是1,那么我们的损失(cost)就越大。那么损失的趋势为
就越有可能是1,那么我们的损失(cost)就越大。那么损失的趋势为
![]()
对于这种趋势,我们可以使用这样的函数来表示
![]()
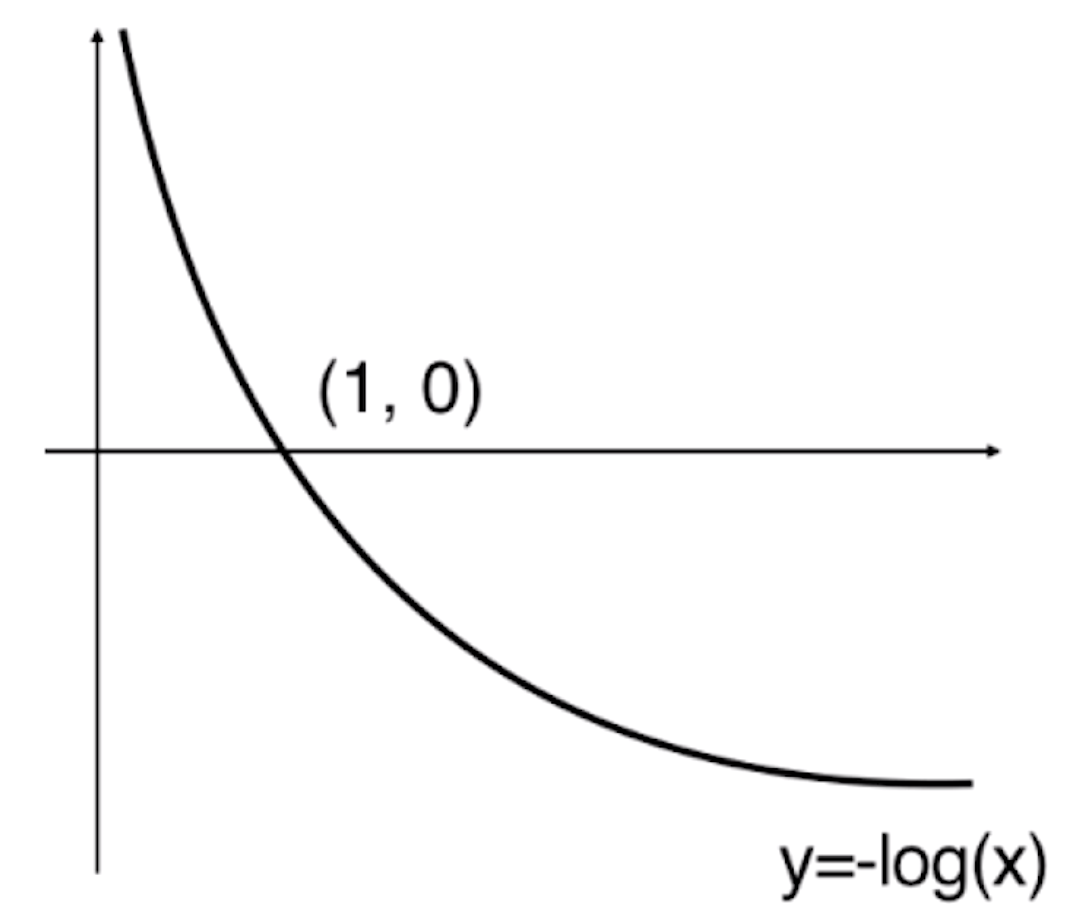
我们把损失函数定义成这两种情况,我们先来看一下y=log(x)的函数图像
![]()
而我们的第一个式子中是一个-log(x),那么-log(x)的图像就为
![]()
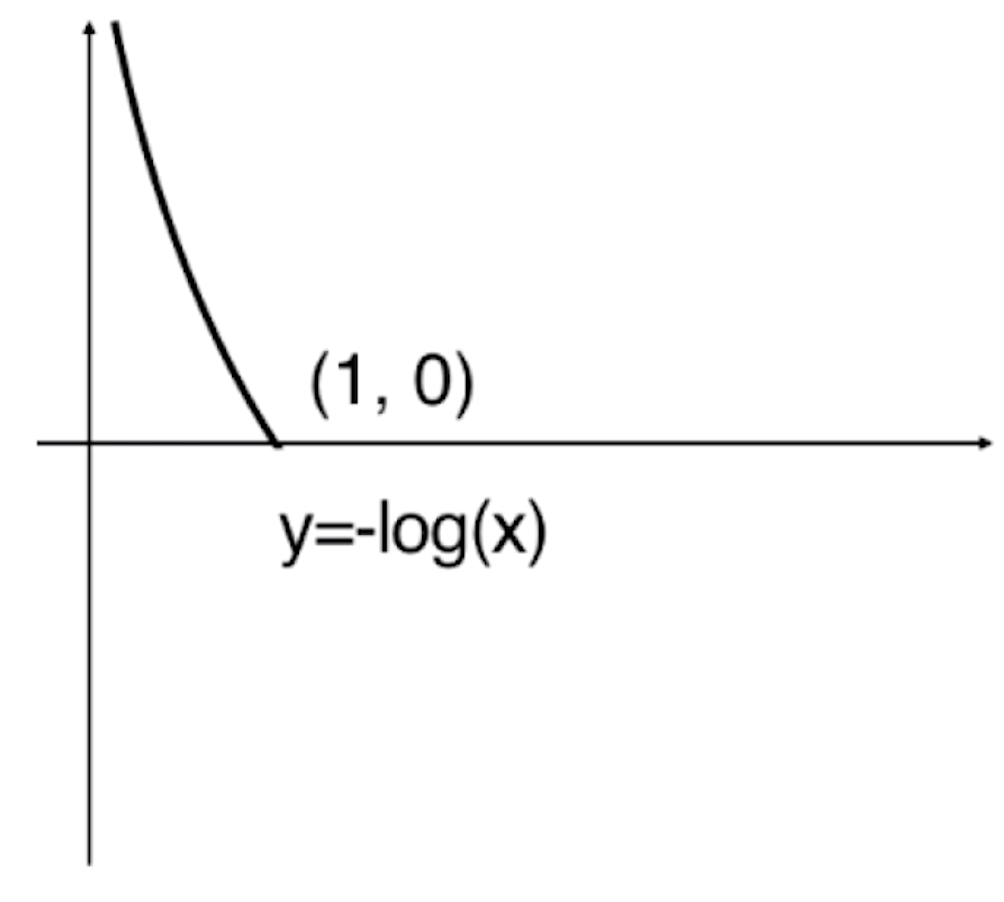
由于估计值![]() 的值域为[0,1],所以上面这个图像超过1的部分都是没有意义的。
的值域为[0,1],所以上面这个图像超过1的部分都是没有意义的。
![]()
通过这个图,我们可以发现当![]() 取0的时候,-log(
取0的时候,-log(![]() )趋近于+∞。按照我们之前分类的方式,当
)趋近于+∞。按照我们之前分类的方式,当![]() =0的时候,预测值
=0的时候,预测值![]() 应该为0,但样本真实值y实际是1,显然我们分错了,此时我们对其进行惩罚,这个惩罚是+∞的。随着
应该为0,但样本真实值y实际是1,显然我们分错了,此时我们对其进行惩罚,这个惩罚是+∞的。随着![]() 逐渐的增大,我们的损失越来越小,当
逐渐的增大,我们的损失越来越小,当![]() 到达1的时候,根据分类标准,预测值
到达1的时候,根据分类标准,预测值![]() 为1,此时它跟样本真值y是一致的。此时-log(
为1,此时它跟样本真值y是一致的。此时-log(![]() )为0,也就是没有任何损失。这样一根曲线就描述了如果我们给了一个样本,这个样本真实的标记输出是1的时候,相应用我们的方法估计出了
)为0,也就是没有任何损失。这样一根曲线就描述了如果我们给了一个样本,这个样本真实的标记输出是1的时候,相应用我们的方法估计出了![]() 以后,代入-log(
以后,代入-log(![]() )得到的损失函数。
)得到的损失函数。
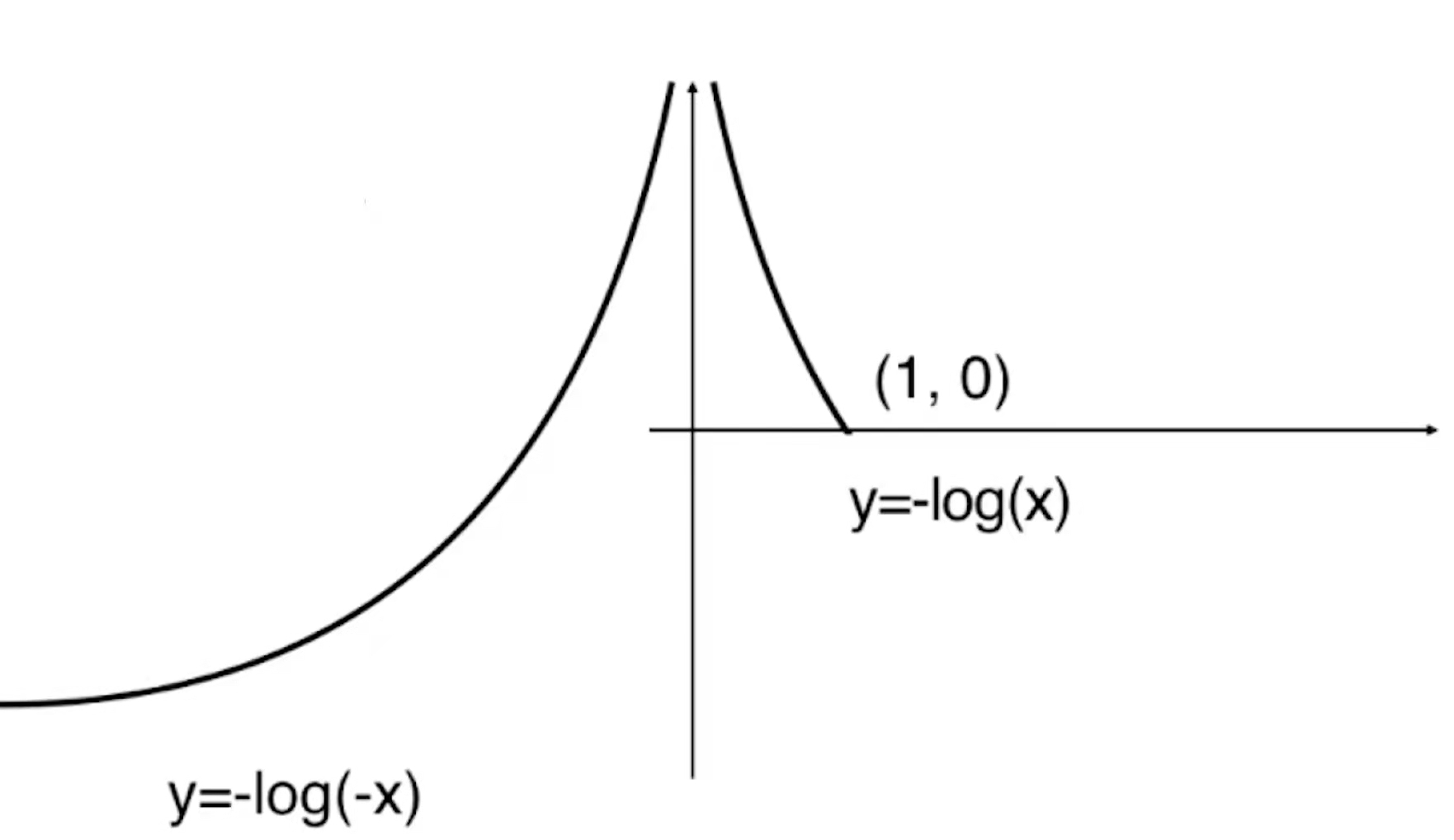
由于y=-log(x)是上图的样子,那么y=-log(-x)就是根据y轴对称的样子
![]()
那么对于-log(1-x)就是将-log(-x)的曲线向右平移一个单位。
![]()
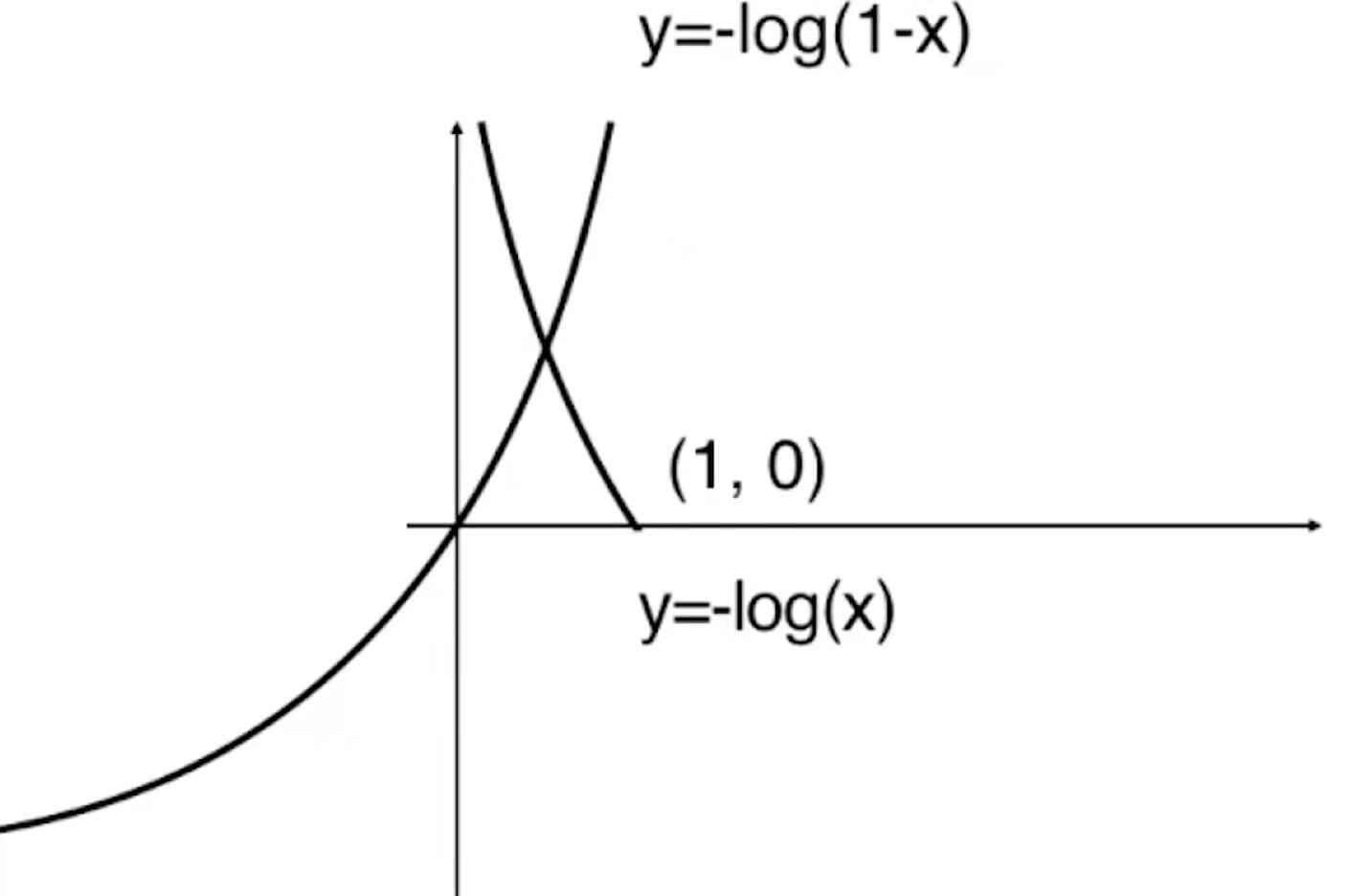
由于![]() 的值域为[0,1],所以y=-log(1-x)小于0的部分是没有意义的。
的值域为[0,1],所以y=-log(1-x)小于0的部分是没有意义的。
![]()
在这根曲线上,如果给定的![]() =1的话,那么此时
=1的话,那么此时![]() 是趋近于+∞的。当
是趋近于+∞的。当![]() =1的时候,预测值
=1的时候,预测值![]() =1,但是y的真值为0,我们完全分错了,所以我们给它一个+∞的惩罚,随着
=1,但是y的真值为0,我们完全分错了,所以我们给它一个+∞的惩罚,随着![]() 的逐渐减小,这个惩罚值会越来越低,直到当
的逐渐减小,这个惩罚值会越来越低,直到当![]() =0的时候,
=0的时候,![]() =0,而y的真值为0,所以此时分类正确,在这种情况下一点惩罚都没有。所以我们用这两根曲线来作为我们的损失函数。
=0,而y的真值为0,所以此时分类正确,在这种情况下一点惩罚都没有。所以我们用这两根曲线来作为我们的损失函数。
由于![]() 这样写非常不方便,所以我们把它合并成一个函数
这样写非常不方便,所以我们把它合并成一个函数
![]() ,这个函数和上面的分类函数是等价的,原因也很简单,当y=1的时候,该式就等于
,这个函数和上面的分类函数是等价的,原因也很简单,当y=1的时候,该式就等于![]() ,当y=0的时候,该式就等于
,当y=0的时候,该式就等于![]() 。
。
当我们面对一个样本X的时候,相应的我们也知道这个样本对应的真实的分类y。现在我们使用逻辑回归的方式就可以估计出来对于这个样本X,它相应的概率![]() 是多少,于是我们就用这个式子得到了它相应的损失是多少。我们会来m个样本,相应的我们只需要将这些损失加在一起就可以了。
是多少,于是我们就用这个式子得到了它相应的损失是多少。我们会来m个样本,相应的我们只需要将这些损失加在一起就可以了。
![]()
这就是我们逻辑回归相应的损失函数。
由于![]()
所以最终我们的损失函数就为
![]()
这里我们要给定样本相应的特征,用![]() 表示,以及对应的输出标记,用
表示,以及对应的输出标记,用![]() 表示,这些都是已知的。我们真正要求的是里面的θ。之后我们要做的事情就是找到一组θ,使得我们的J(θ)达到一个最小值。对于这个式子,它不能像线性回归使用最小二乘法一样推导出一个正规方程解,它是没有数学的解析解的。但是它可以使用梯度下降法来求解。这个损失函数是一个凸函数,它是没有局部最优解的,只存在唯一的一个全局最优解。
表示,这些都是已知的。我们真正要求的是里面的θ。之后我们要做的事情就是找到一组θ,使得我们的J(θ)达到一个最小值。对于这个式子,它不能像线性回归使用最小二乘法一样推导出一个正规方程解,它是没有数学的解析解的。但是它可以使用梯度下降法来求解。这个损失函数是一个凸函数,它是没有局部最优解的,只存在唯一的一个全局最优解。
逻辑回归损失函数的梯度
对于这个损失函数![]()
要求它的梯度,其实就是对每一个θ求偏导数
![]()
我们先来对![]() 函数
函数![]() 求导
求导
这是一个复合函数,根据复合函数求导法则![]() ,令a=-t,b=e^-t,c=
,令a=-t,b=e^-t,c=![]() ,则a'=-1,b'=e^-t,c'=
,则a'=-1,b'=e^-t,c'=![]()
所以![]()
我们再来看一下![]() 的导数。这也是一个复合函数。log'x=1/x,则
的导数。这也是一个复合函数。log'x=1/x,则
![]()
那么对于损失函数前半部分![]() 的导数就为(这里同样也是复合函数求导,
的导数就为(这里同样也是复合函数求导,![]() 跟随的特征就是
跟随的特征就是![]() )
)
![]()
对于后半部分![]() ,我们先看一下
,我们先看一下![]() 的导数,它同样是一个复合函数,a=logx,b=1-x,c=
的导数,它同样是一个复合函数,a=logx,b=1-x,c=![]() ,则a'=1/x,b'=-1,则
,则a'=1/x,b'=-1,则
![]()
由于![]() ,代入上式,可得
,代入上式,可得
![]()
则![]() 的导数就为(这里同样也是复合函数求导,
的导数就为(这里同样也是复合函数求导,![]() 跟随的特征就是
跟随的特征就是![]() )
)
![]()
由于前半部分的导数![]() =
=![]()
后半部分的导数![]() =
=![]()
合并后就为
![]()
最终J(θ)对某一个θ求偏导的话就为(前面的负号放到了括号中)
![]()
而![]() 就是我们逻辑回归的预测值
就是我们逻辑回归的预测值![]() ,所以上式可以写为
,所以上式可以写为
![]()
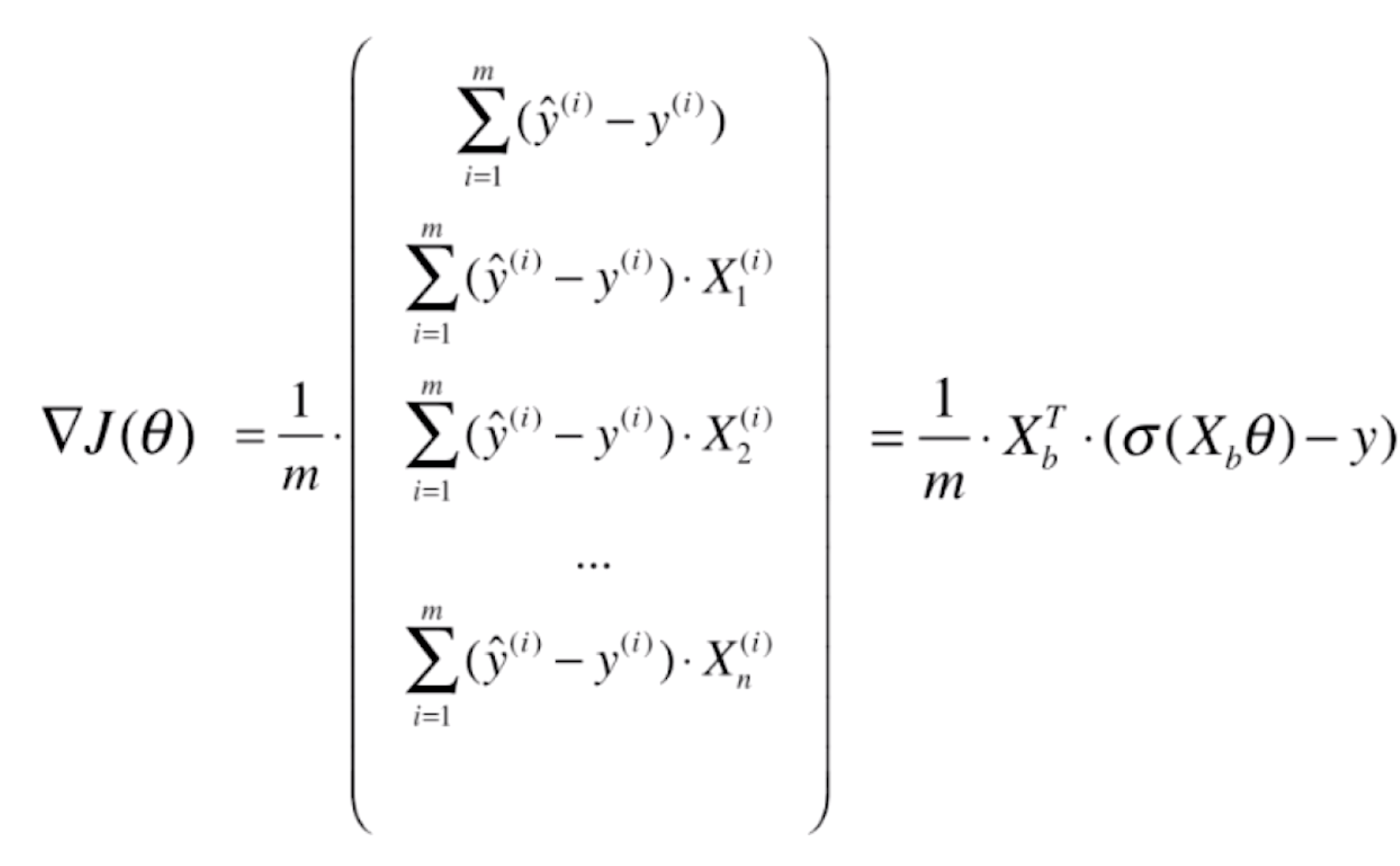
则J(θ)的梯度就为
![]()
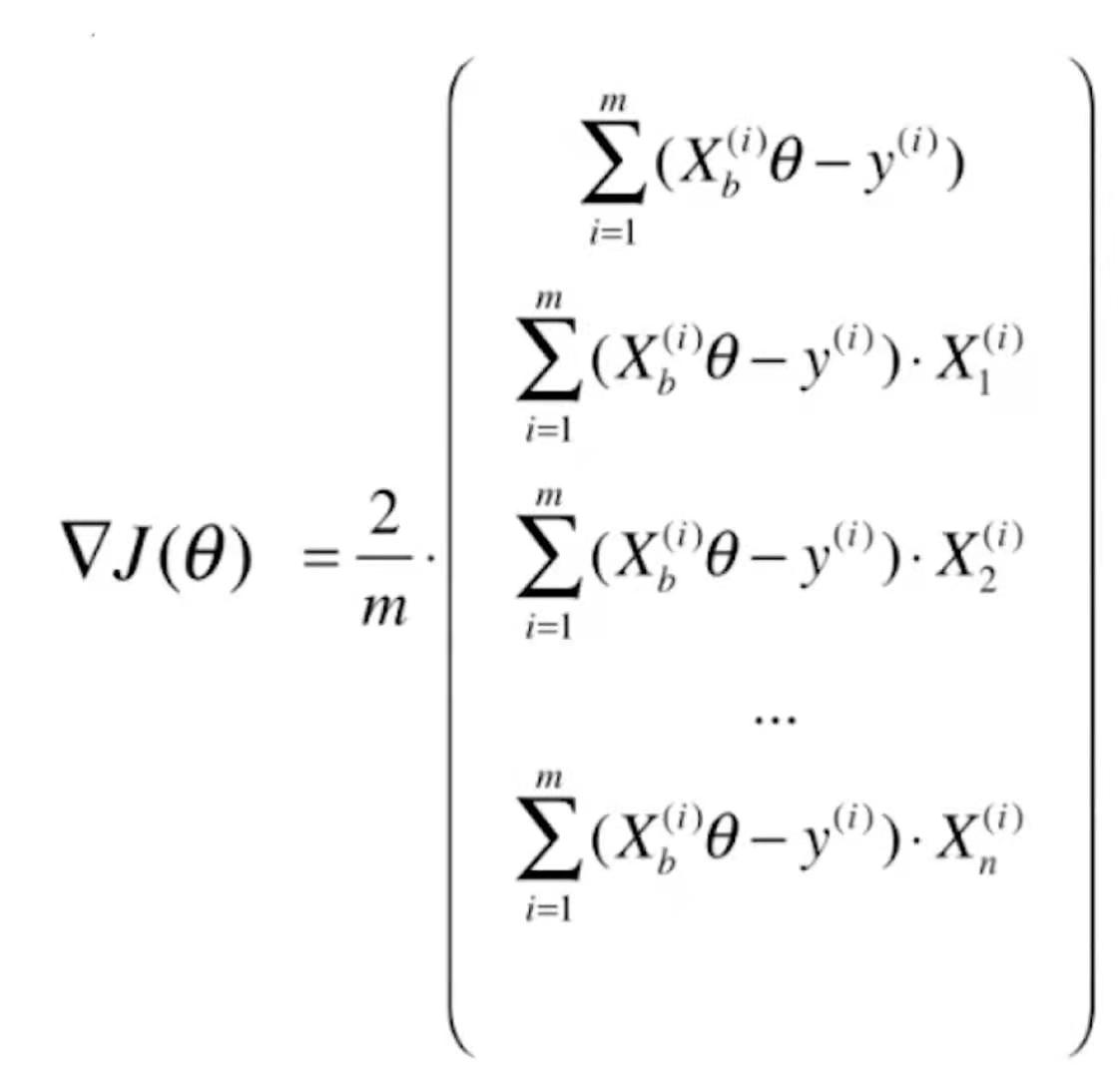
我们再来对比一下线性回归的梯度
![]()
我们会发现,逻辑回归和线性回归的梯度其实是一致的,只不过线性回归的预测值![]() =
=![]() ;而逻辑回归的预测值
;而逻辑回归的预测值![]() =
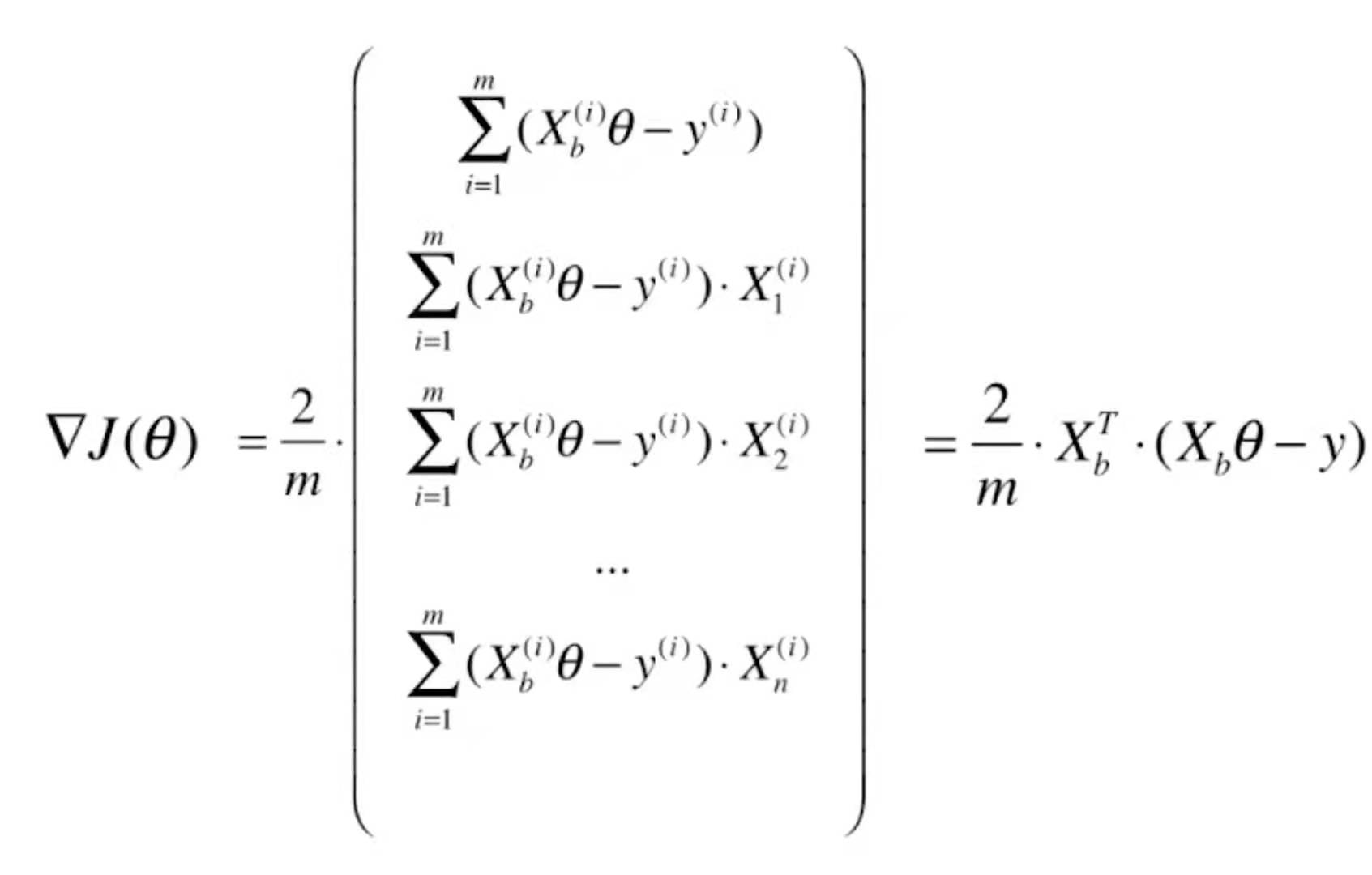
=![]() 。线性回归是均方误差,所以前面多了一个2,而逻辑回归没有这个平方,所以前面没有这个2。对于线性回归进行向量化处理,它的梯度可以写成
。线性回归是均方误差,所以前面多了一个2,而逻辑回归没有这个平方,所以前面没有这个2。对于线性回归进行向量化处理,它的梯度可以写成
![]()
那么对逻辑回归的梯度进行向量化处理,就有
![]()
实现逻辑回归算法
import numpy as np
from math import sqrt
def accuracy_score(y_true, y_predict):
"""计算y_true和y_predict之间的准确率"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum(y_true == y_predict) / len(y_true)
def mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的MSE"""
assert len(y_true) == len(y_predict), \
"the size of y_true must be equal to the size of y_predict"
return np.sum((y_true - y_predict)**2) / len(y_true)
def root_mean_squared_error(y_true, y_predict):
"""计算y_true和y_predict之间的RMSE"""
return sqrt(mean_squared_error(y_true, y_predict))
def mean_absolute_error(y_true, y_predict):
"""计算y_true和y_predict之间的MAE"""
return np.sum(np.absolute(y_true - y_predict)) / len(y_true)
def r2_score(y_true, y_predict):
"""计算y_true和y_predict之间的R Square"""
return 1 - mean_squared_error(y_true, y_predict) / np.var(y_true)
import numpy as np
from .metrics import accuracy_score
class LogisticRegression:
def __init__(self):
# 初始化LogisticRegression模型
self.coef = None # 系数
self.interception = None # 截距
self._theta = None
def _sigmoid(self, t):
return 1 / (1 + np.exp(-t))
def fit(self, X_train, y_train, eta=0.01, n_iters=1e4):
# 根据训练数据集X_train,y_train,使用梯度下降法训练Logistic Regression模型
assert X_train.shape[0] == y_train.shape[0], \
"X_train的列数必须等于y_train的长度"
def J(theta, X_b, y):
# 构建损失函数
p_hat = self._sigmoid(X_b.dot(theta))
try:
return - np.sum(y * np.log(p_hat) + (1 - y) * np.log(1 - p_hat)) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
# 对theta求偏导数,获取梯度向量
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) / len(X_b)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
"""
梯度下降算法
:param X_b: 带虚拟特征1的自变量特征矩阵
:param y: 因变量向量
:param initial_theta: 初始的常数向量,这里需要注意的是真正待求的是常数向量,求偏导的也是常数向量
:param eta: 迭代步长、学习率
:param n_iters: 最大迭代次数
:param epsilon: 误差值
:return:
"""
theta = initial_theta
# 真实迭代次数
i_iter = 0
while i_iter < n_iters:
# 获取梯度
gradient = dJ(theta, X_b, y)
last_theta = theta
# 迭代更新theta,不断顺着梯度方向寻找新的theta
theta = theta - eta * gradient
# 计算前后两次迭代后的损失函数差值的绝对值
if abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon:
break
# 更新迭代次数
i_iter += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters)
self.interception = self._theta[0]
self.coef = self._theta[1:]
return self
def predict_proba(self, X_predict):
# 给定待预测数据集X_predict,返回表示X_predict的结果概率向量
assert self.interception is not None and self.coef is not None, \
"开始预测前必须fit"
assert X_predict.shape[1] == len(self.coef), \
"预测的特征数必须与训练的特征数相等"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return self._sigmoid(X_b.dot(self._theta))
def predict(self, X_predict):
# 给定待预测数据集X_predict,返回表示X_predict的结果向量
assert self.interception is not None and self.coef is not None, \
"开始预测前必须fit"
assert X_predict.shape[1] == len(self.coef), \
"预测的特征数必须与训练的特征数相等"
proba = self.predict_proba(X_predict)
return np.array(proba >= 0.5, dtype='int')
def score(self, X_test, y_test):
# 根据测试数据集X_test和y_test确定当前模型的准确度
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self):
return "LogisticRegression()"
现在我们来使用逻辑回归判别鸢尾花数据集,先获取鸢尾花数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
if __name__ == "__main__":
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 鸢尾花数据集有3个分类,而逻辑回归只能进行二分类,所以我们去掉2这个特征
X = X[y < 2, :2]
y = y[y < 2]
print(X.shape)
print(y.shape)
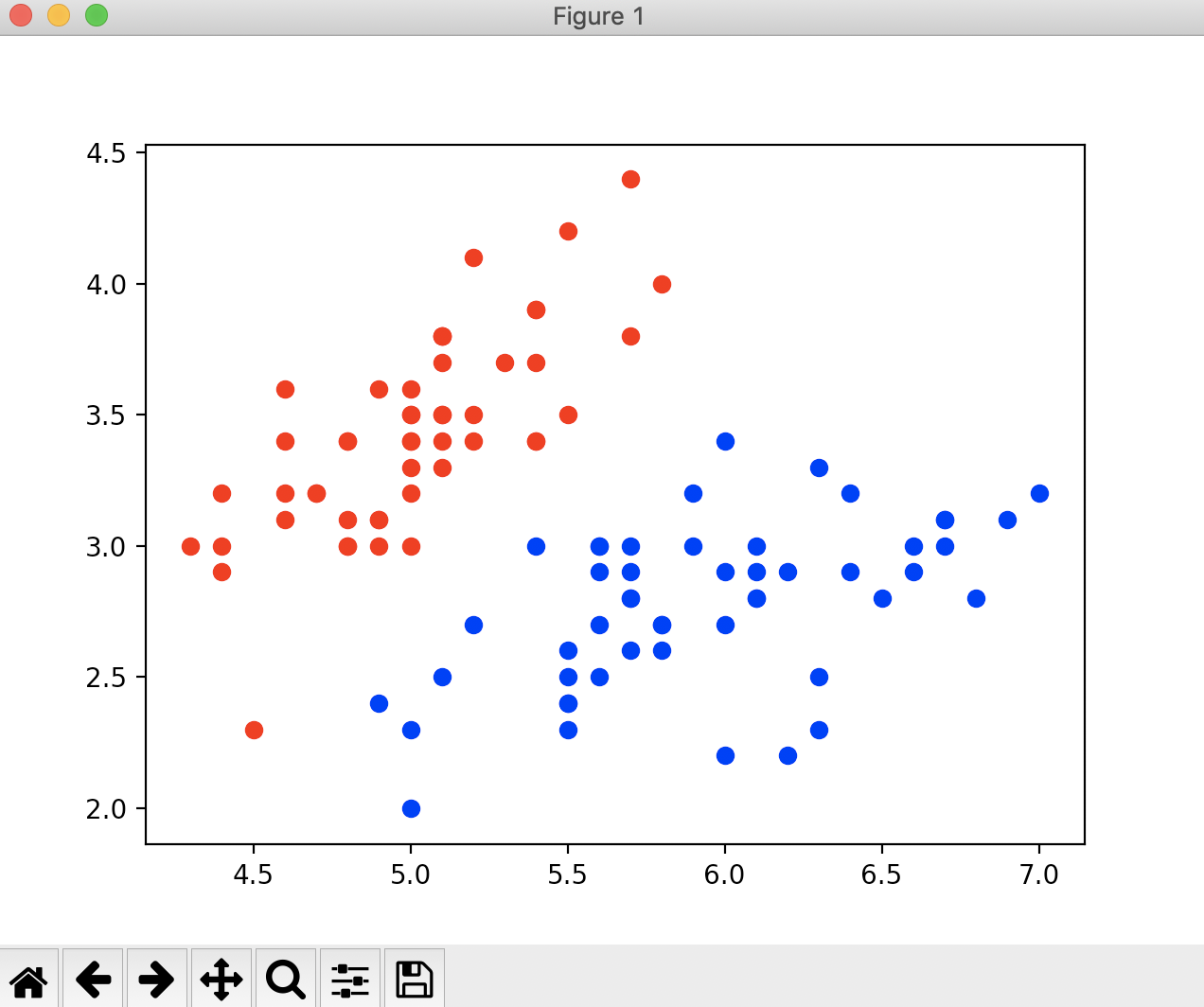
plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
plt.show()
运行结果
(100, 2)
(100,)
![]()
此时我们看到鸢尾花的数据集有100个样本数,2个特征。现在我们就用我们自己写的逻辑回归进行分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from playLA.model_selection import train_test_split
from playLA.LogisticRegression import LogisticRegression
if __name__ == "__main__":
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 鸢尾花数据集有3个分类,而逻辑回归只能进行二分类,所以我们去掉2这个特征
X = X[y < 2, :2]
y = y[y < 2]
print(X.shape)
print(y.shape)
# plt.scatter(X[y == 0, 0], X[y == 1, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 查看分类准确度
print(log_reg.score(X_test, y_test))
# 查看测试数据集每一个元素的概率值
print(log_reg.predict_proba(X_test))
# 查看分类结果
print(y_test)
# 查看预测结果
print(log_reg.predict(X_test))
运行结果
(100, 2)
(100,)
1.0
[0.92972035 0.98664939 0.14852024 0.01685947 0.0369836 0.0186637
0.04936918 0.99669244 0.97993941 0.74524655 0.04473194 0.00339285
0.26131273 0.0369836 0.84192923 0.79892262 0.82890209 0.32358166
0.06535323 0.20735334]
[1 1 0 0 0 0 0 1 1 1 0 0 0 0 1 1 1 0 0 0]
[1 1 0 0 0 0 0 1 1 1 0 0 0 0 1 1 1 0 0 0]
通过训练和查看分类准确度,我们可以看到,我们对鸢尾花数据集的测试数据全部都正确的进行了分类。并且可以查看测试数据集元素概率值。并通过概率值获取最终的分类结果和预测结果。
决策边界
对于逻辑回归,它同样也有系数和截距,我们来看一下鸢尾花数据集的系数和截距
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from playLA.model_selection import train_test_split
from playLA.LogisticRegression import LogisticRegression
if __name__ == "__main__":
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 鸢尾花数据集有3个分类,而逻辑回归只能进行二分类,所以我们去掉2这个特征
X = X[y < 2, :2]
y = y[y < 2]
print(X.shape)
print(y.shape)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 查看分类准确度
print(log_reg.score(X_test, y_test))
# 查看测试数据集每一个元素的概率值
print(log_reg.predict_proba(X_test))
# 查看分类结果
print(y_test)
# 查看预测结果
print(log_reg.predict(X_test))
# 查看逻辑回归的系数
print(log_reg.coef)
# 查看逻辑回归的截距
print(log_reg.interception)
运行结果
(100, 2)
(100,)
1.0
[0.92972035 0.98664939 0.14852024 0.01685947 0.0369836 0.0186637
0.04936918 0.99669244 0.97993941 0.74524655 0.04473194 0.00339285
0.26131273 0.0369836 0.84192923 0.79892262 0.82890209 0.32358166
0.06535323 0.20735334]
[1 1 0 0 0 0 0 1 1 1 0 0 0 0 1 1 1 0 0 0]
[1 1 0 0 0 0 0 1 1 1 0 0 0 0 1 1 1 0 0 0]
[ 3.01796521 -5.04447145]
-0.6937719272911228
这些系数和截距就组成了我们之前一直说的θ值。对于θ值它有没有几何意义呢,我们应该如何看待这个θ值呢?
之前我们在说逻辑回归原理的时候,有这样的式子
![]()
我们通过训练,得出了这个θ向量,如果我们的样本![]() 有n个特征(维度)的话,那么θ就有n+1个元素,我们要多添加一个
有n个特征(维度)的话,那么θ就有n+1个元素,我们要多添加一个![]() 。每当新来一个样本的时候,样本与θ进行点乘,点乘之后的结果送给
。每当新来一个样本的时候,样本与θ进行点乘,点乘之后的结果送给![]() 函数,得到的这个值,我们就称之为是这个样本发生我们定义的事件的概率值。如果概率值≥0.5的话,我们就分类这样样本属于1这一类;如果概率值<0.5的话,我们就分类这个样本属于0这一类。我们再来看一下
函数,得到的这个值,我们就称之为是这个样本发生我们定义的事件的概率值。如果概率值≥0.5的话,我们就分类这样样本属于1这一类;如果概率值<0.5的话,我们就分类这个样本属于0这一类。我们再来看一下![]() 函数
函数
![]()
当t>0时,p>0.5;t<0时,p<0.5,分界点在t=0的时候。将![]() 代入t,则有
代入t,则有
![]()
当![]() ≥0的时候,我们的概率估计值
≥0的时候,我们的概率估计值![]() ≥0.5,此时我们将新来的样本x分类为y=1;当
≥0.5,此时我们将新来的样本x分类为y=1;当![]() <0的时候,我们的概率估计值
<0的时候,我们的概率估计值![]() <0.5,此时我们将新来的样本x分类为y=0。换句话说,我们为新来的样本分类为1还是0,这个边界点
<0.5,此时我们将新来的样本x分类为y=0。换句话说,我们为新来的样本分类为1还是0,这个边界点![]() ,这个位置就被称为决策边界。
,这个位置就被称为决策边界。
![]() 两个向量进行点乘,它同时代表的是一条直线。如果X有两个特征,那么
两个向量进行点乘,它同时代表的是一条直线。如果X有两个特征,那么![]() 就可以写成
就可以写成
![]()
这样的一个式子是一个直线的表达式。在二维坐标系中,横轴是x1这个特征,纵轴是x2这个特征。经过转换,就有
![]()
推导出x2,我们是为了把这根直线给画出来,真实感性的看一下它的样子。
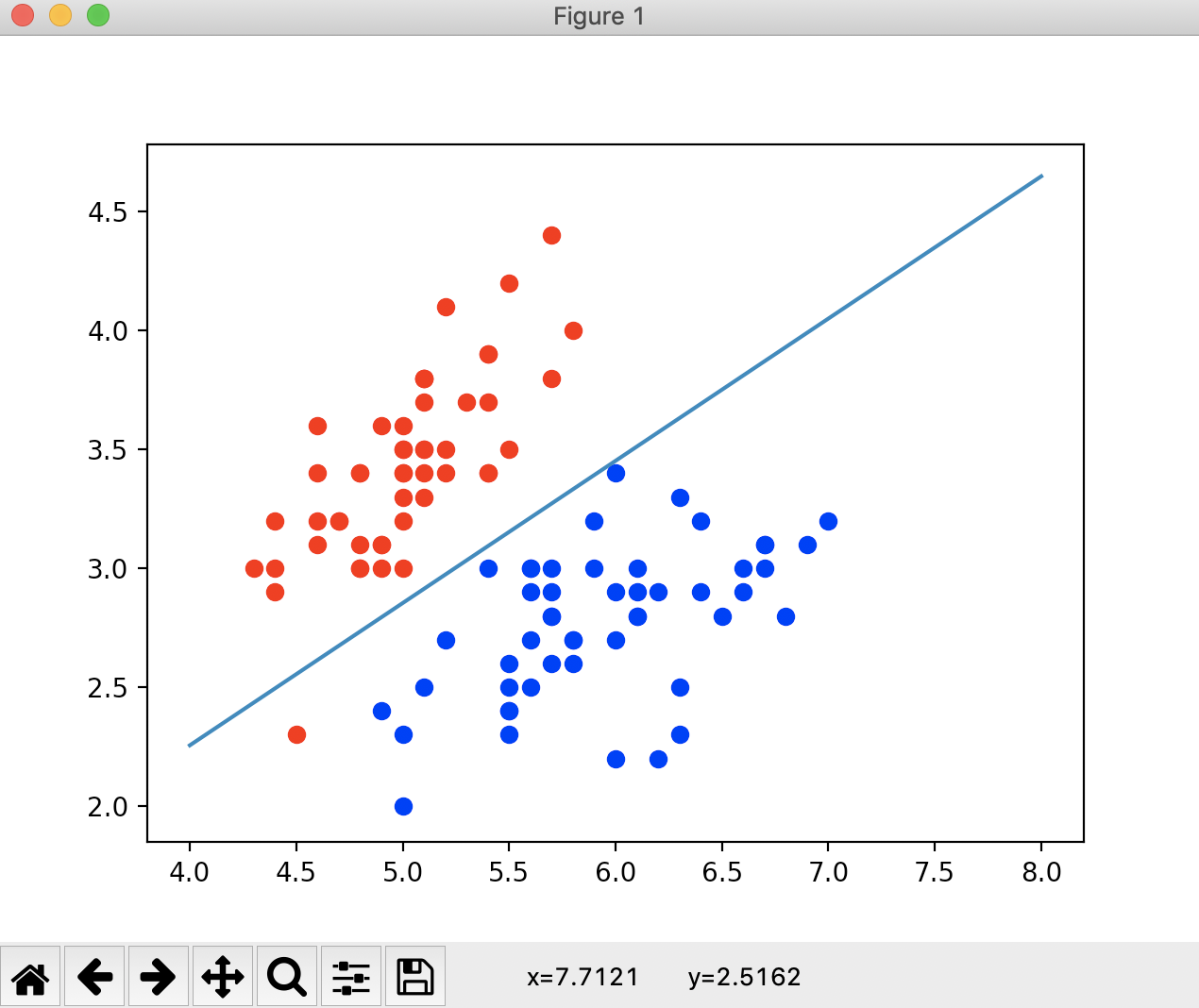
def x2(x1):
return (- log_reg.coef[0] * x1 - log_reg.interception) / log_reg.coef[1]
x1_plot = np.linspace(4, 8, 1000)
x2_plot = x2(x1_plot)
plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
plt.plot(x1_plot, x2_plot)
plt.show()
运行结果
![]()
图中的这根直线就是我们的决策边界。这根决策边界大体上将红色点和蓝色的点分成了两部分。如果我们新来一个样本的话,把样本的每一个特征和θ相乘,如果大于等于0的话,我们就给它分类为1,就在这根直线的下面。这就是这根直线的几何意义。如果得到的结果是小于0的话,我们就给它分类为0,就在这根直线的上方。如果等于0的话,它正好落在这一根决策边界上,此时无论我们把这个样本分类成0还是分类成1都是正确的,只不过我们这里分类成1。这里我们会发现在上图中有一个红色的点在决策边界的下方,显然这是一个分类错误的情况。而我们之前在测试用例中的分类准确率是100%,说明这个红色的点是在训练数据集中,我们可以来验证一下
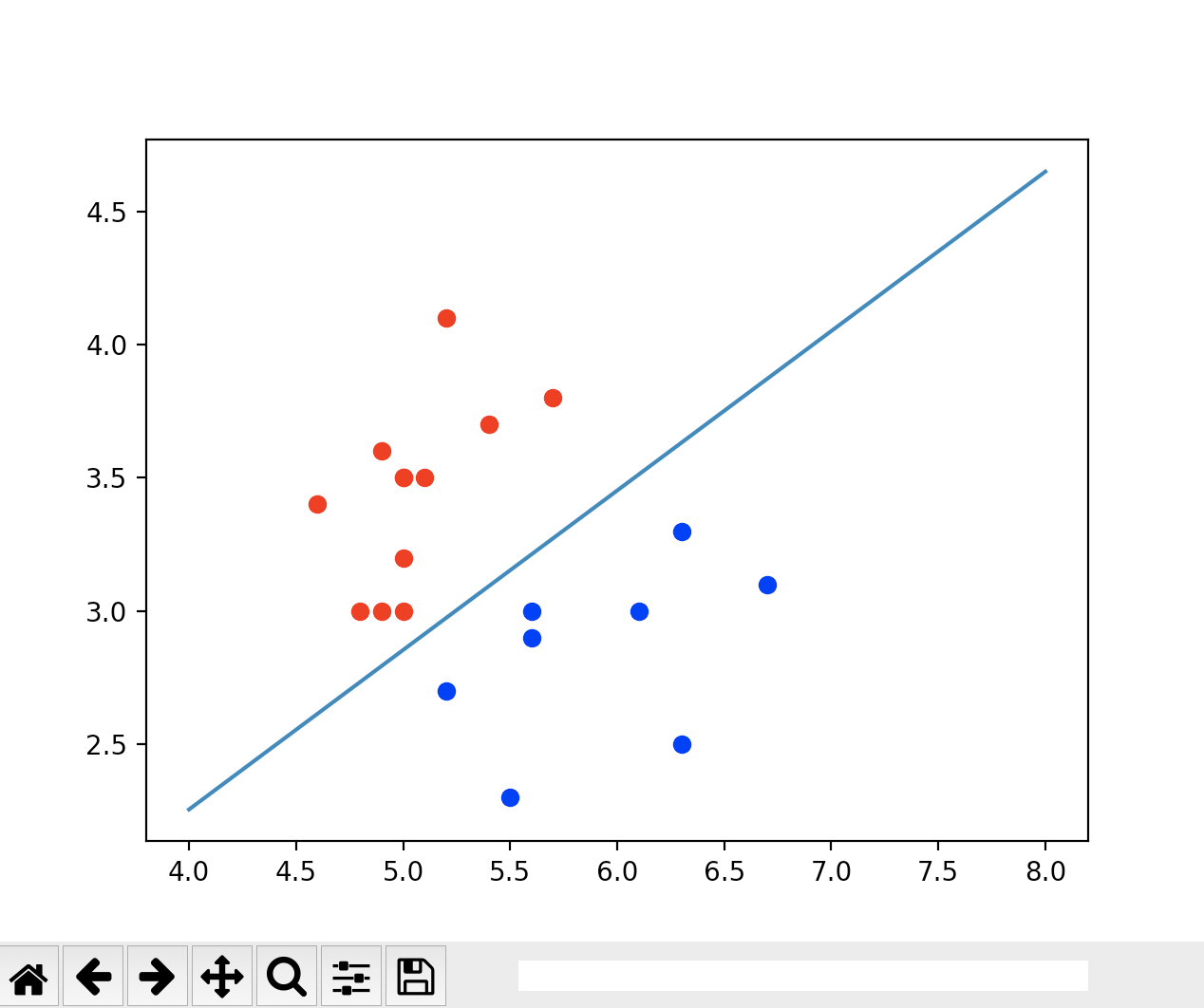
def x2(x1):
return (- log_reg.coef[0] * x1 - log_reg.interception) / log_reg.coef[1]
x1_plot = np.linspace(4, 8, 1000)
x2_plot = x2(x1_plot)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], color='red')
plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], color='blue')
plt.plot(x1_plot, x2_plot)
plt.show()
运行结果
![]()
由上图可见,我们的测试数据集只有这么几个点,它完全是分类正确的。
不规则的决策边界的绘制方法
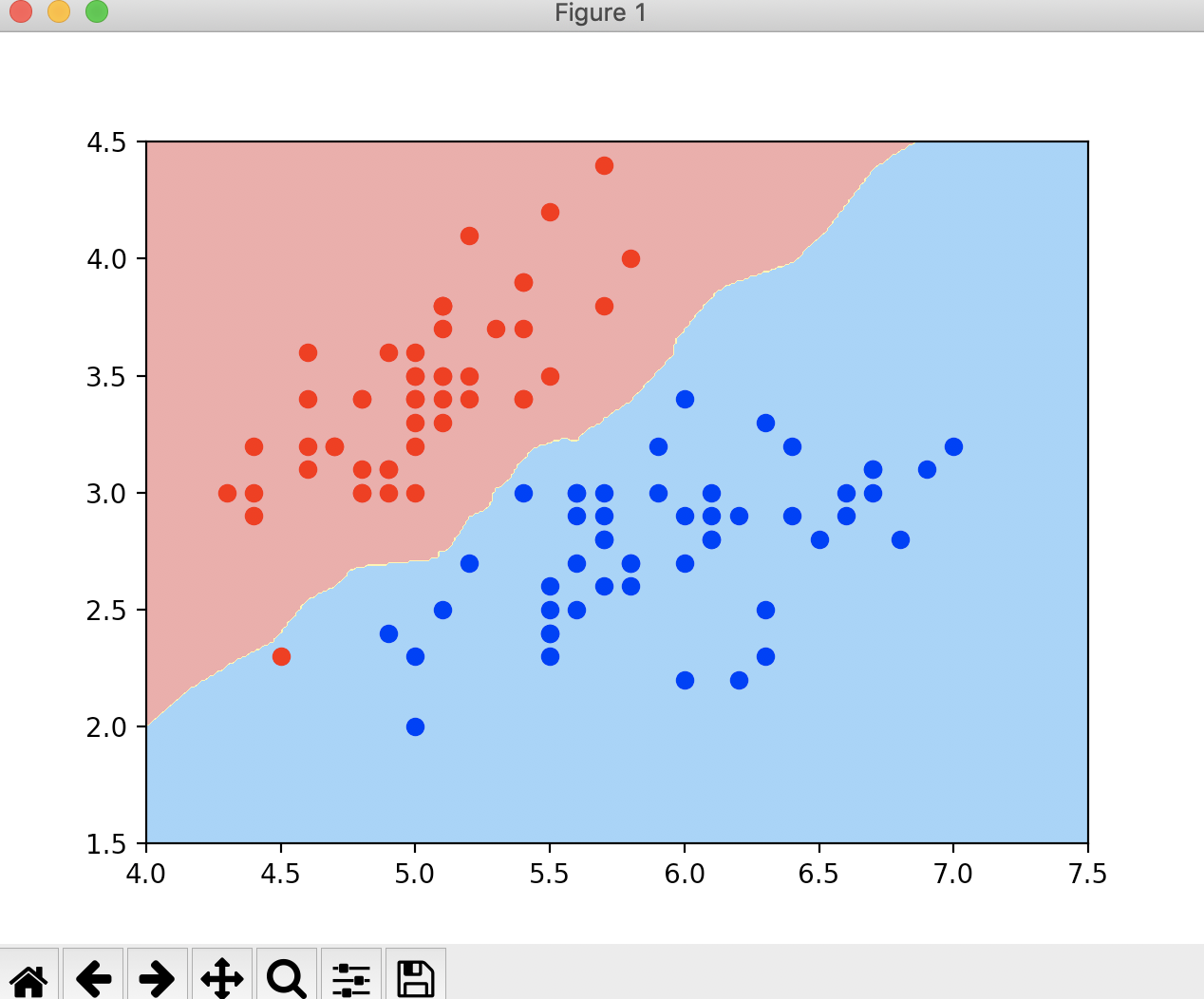
如果我们的分类样本本身没有一条这样的泾渭分明的可以用数学表达式来表达的决策边界
![]()
那我们如何来画出这种不规则的决策边界呢?我们依然还是用之前的逻辑回归的样本数据来进行决策边界的绘制
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from playLA.model_selection import train_test_split
from playLA.LogisticRegression import LogisticRegression
from matplotlib.colors import ListedColormap
if __name__ == "__main__":
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 鸢尾花数据集有3个分类,而逻辑回归只能进行二分类,所以我们去掉2这个特征
X = X[y < 2, :2]
y = y[y < 2]
# print(X.shape)
# print(y.shape)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 查看分类准确度
# print(log_reg.score(X_test, y_test))
# # 查看测试数据集每一个元素的概率值
# print(log_reg.predict_proba(X_test))
# # 查看分类结果
# print(y_test)
# # 查看预测结果
# print(log_reg.predict(X_test))
# # 查看逻辑回归的系数
# print(log_reg.coef)
# # 查看逻辑回归的截距
# print(log_reg.interception)
# def x2(x1):
# return (- log_reg.coef[0] * x1 - log_reg.interception) / log_reg.coef[1]
#
# x1_plot = np.linspace(4, 8, 1000)
# x2_plot = x2(x1_plot)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
# plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], color='red')
# plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
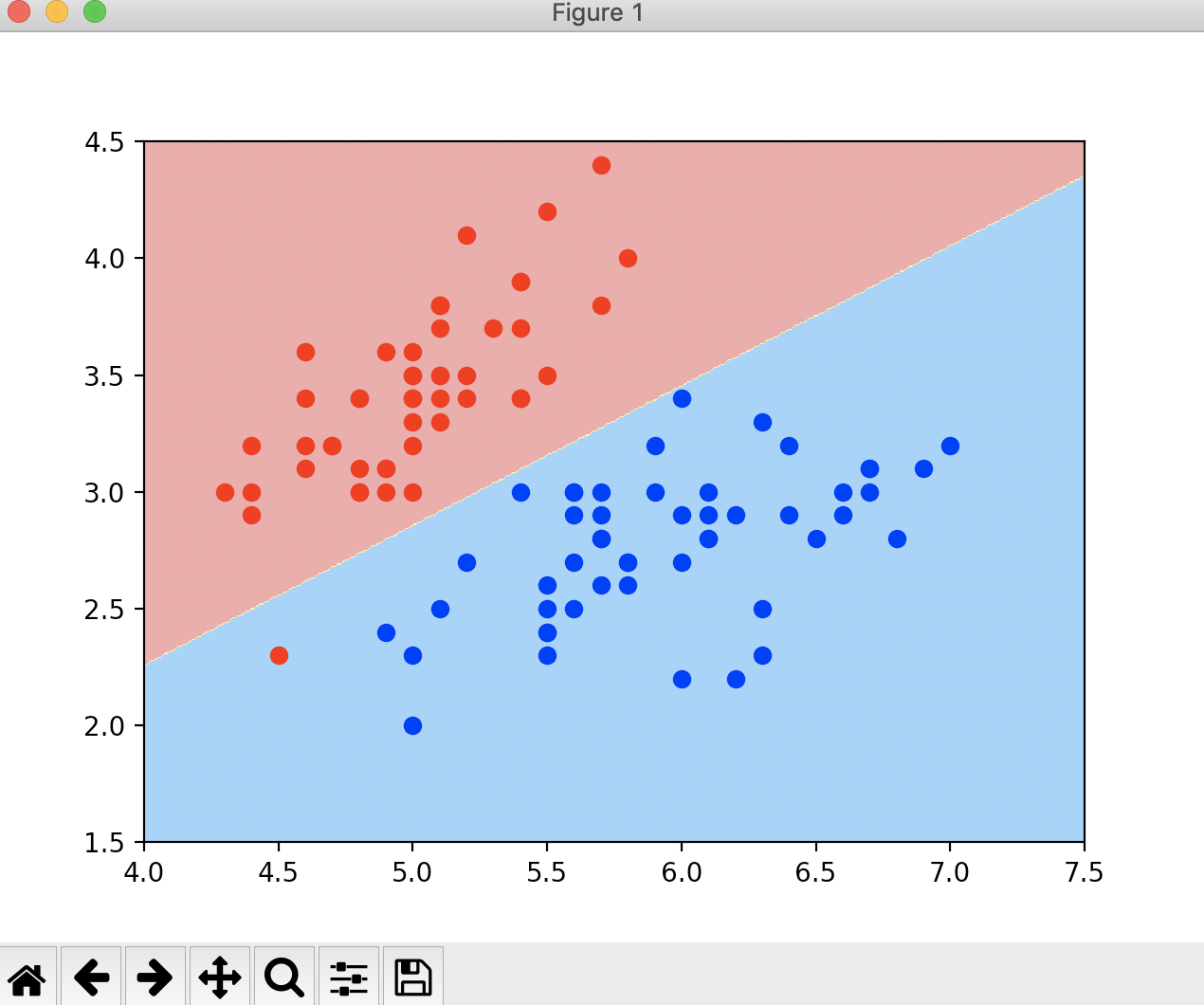
def plot_decision_boundary(model, axis):
# 绘制不规则决策边界
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[4, 7.5, 1.5, 4.5])
plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
plt.show()
运行结果
![]()
现在我们来看一下KNN算法的决策边界,KNN算法的决策边界也是没有数学表达式的
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from playLA.model_selection import train_test_split
from playLA.LogisticRegression import LogisticRegression
from matplotlib.colors import ListedColormap
from sklearn.neighbors import KNeighborsClassifier
if __name__ == "__main__":
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 鸢尾花数据集有3个分类,而逻辑回归只能进行二分类,所以我们去掉2这个特征
X = X[y < 2, :2]
y = y[y < 2]
# print(X.shape)
# print(y.shape)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 查看分类准确度
# print(log_reg.score(X_test, y_test))
# # 查看测试数据集每一个元素的概率值
# print(log_reg.predict_proba(X_test))
# # 查看分类结果
# print(y_test)
# # 查看预测结果
# print(log_reg.predict(X_test))
# # 查看逻辑回归的系数
# print(log_reg.coef)
# # 查看逻辑回归的截距
# print(log_reg.interception)
# def x2(x1):
# return (- log_reg.coef[0] * x1 - log_reg.interception) / log_reg.coef[1]
#
# x1_plot = np.linspace(4, 8, 1000)
# x2_plot = x2(x1_plot)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
# plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], color='red')
# plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
def plot_decision_boundary(model, axis):
# 绘制不规则决策边界
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
# plot_decision_boundary(log_reg, axis=[4, 7.5, 1.5, 4.5])
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
# KNN的决策边界
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_train)
print(knn_clf.score(X_test, y_test))
plot_decision_boundary(knn_clf, axis=[4, 7.5, 1.5, 4.5])
plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
plt.show()
运行结果
1.0
![]()
通过结果,我们可以看到KNN算法的预测数据集的分类准确率也是100%,但是KNN算法的决策边界就不再是一条直线,而是一条弯弯曲曲的曲线。在这条曲线的上方,用K-近邻的思路得到的点就是一个红色的点,而在曲线的下方得到的点用K-近邻的思路就是一个蓝色的点。我们知道KNN算法支持多分类,我们来看一下KNN多分类的决策边界
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from playLA.model_selection import train_test_split
from playLA.LogisticRegression import LogisticRegression
from matplotlib.colors import ListedColormap
from sklearn.neighbors import KNeighborsClassifier
if __name__ == "__main__":
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 鸢尾花数据集有3个分类,而逻辑回归只能进行二分类,所以我们去掉2这个特征
X = X[y < 2, :2]
y = y[y < 2]
# print(X.shape)
# print(y.shape)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 查看分类准确度
# print(log_reg.score(X_test, y_test))
# # 查看测试数据集每一个元素的概率值
# print(log_reg.predict_proba(X_test))
# # 查看分类结果
# print(y_test)
# # 查看预测结果
# print(log_reg.predict(X_test))
# # 查看逻辑回归的系数
# print(log_reg.coef)
# # 查看逻辑回归的截距
# print(log_reg.interception)
# def x2(x1):
# return (- log_reg.coef[0] * x1 - log_reg.interception) / log_reg.coef[1]
#
# x1_plot = np.linspace(4, 8, 1000)
# x2_plot = x2(x1_plot)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
# plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], color='red')
# plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
def plot_decision_boundary(model, axis):
# 绘制不规则决策边界
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
# plot_decision_boundary(log_reg, axis=[4, 7.5, 1.5, 4.5])
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
# KNN的决策边界
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_train)
# print(knn_clf.score(X_test, y_test))
# plot_decision_boundary(knn_clf, axis=[4, 7.5, 1.5, 4.5])
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
# KNN多分类的决策边界
knn_clf_all = KNeighborsClassifier()
knn_clf_all.fit(iris.data[:, :2], iris.target)
plot_decision_boundary(knn_clf_all, axis=[4, 8, 1.5, 4.5])
plt.scatter(iris.data[iris.target == 0, 0], iris.data[iris.target == 0, 1], color='red')
plt.scatter(iris.data[iris.target == 1, 0], iris.data[iris.target == 1, 1], color='blue')
plt.scatter(iris.data[iris.target == 2, 0], iris.data[iris.target == 2, 1], color='green')
plt.show()
运行结果
![]()
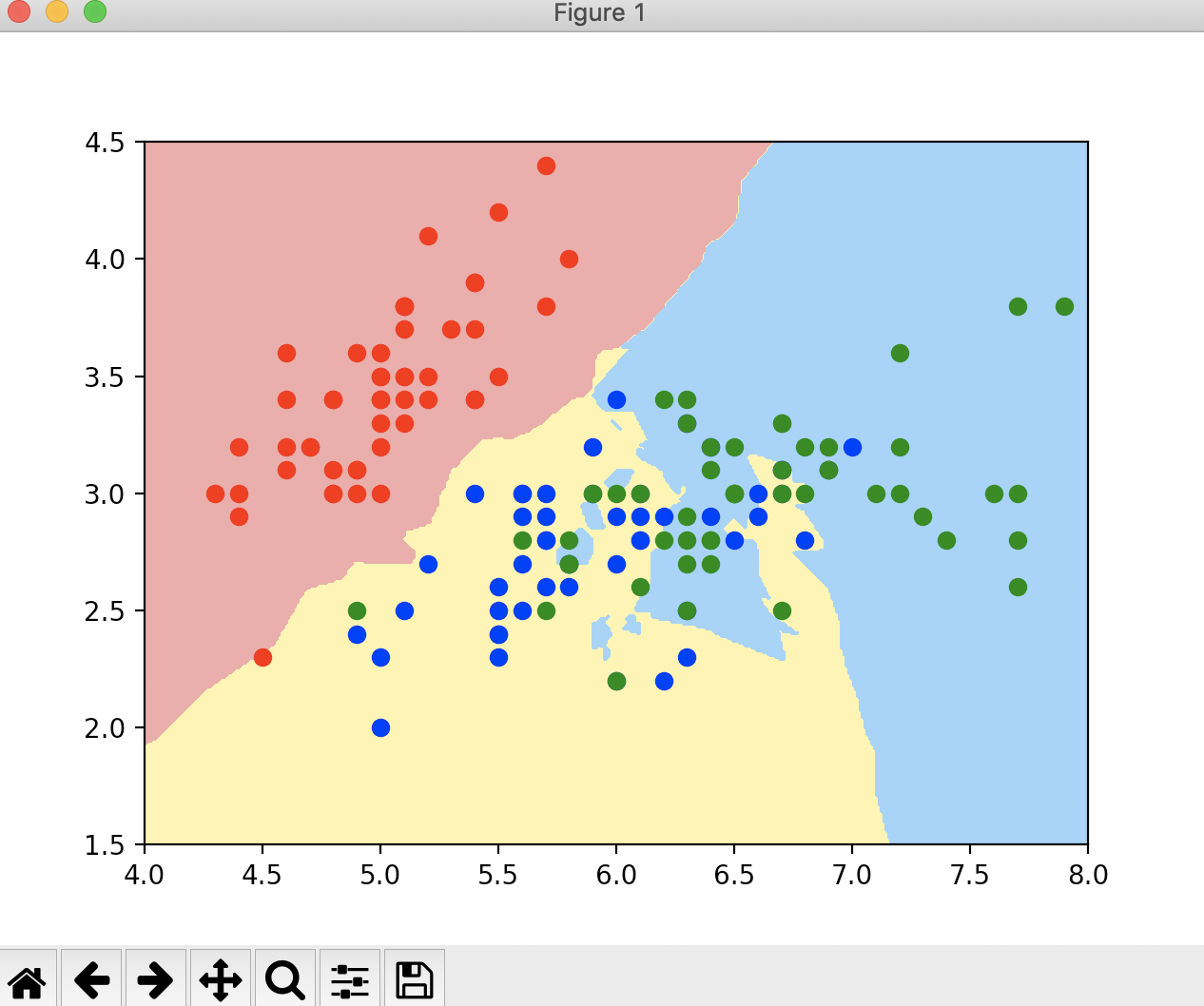
通过图中KNN的决策边界,可以看出是非常不规则的,黄蓝相间的地方图形非常的奇怪,甚至在黄色中还存在一些蓝色的部分,这样一种弯弯曲曲的形状显然就是过拟合的表现。这是因为KNN默认的超参数k太小导致的,我们需要调大这个参数。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from playLA.model_selection import train_test_split
from playLA.LogisticRegression import LogisticRegression
from matplotlib.colors import ListedColormap
from sklearn.neighbors import KNeighborsClassifier
if __name__ == "__main__":
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 鸢尾花数据集有3个分类,而逻辑回归只能进行二分类,所以我们去掉2这个特征
X = X[y < 2, :2]
y = y[y < 2]
# print(X.shape)
# print(y.shape)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
X_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# 查看分类准确度
# print(log_reg.score(X_test, y_test))
# # 查看测试数据集每一个元素的概率值
# print(log_reg.predict_proba(X_test))
# # 查看分类结果
# print(y_test)
# # 查看预测结果
# print(log_reg.predict(X_test))
# # 查看逻辑回归的系数
# print(log_reg.coef)
# # 查看逻辑回归的截距
# print(log_reg.interception)
# def x2(x1):
# return (- log_reg.coef[0] * x1 - log_reg.interception) / log_reg.coef[1]
#
# x1_plot = np.linspace(4, 8, 1000)
# x2_plot = x2(x1_plot)
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
# plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], color='red')
# plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], color='blue')
# plt.plot(x1_plot, x2_plot)
# plt.show()
def plot_decision_boundary(model, axis):
# 绘制不规则决策边界
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
# plot_decision_boundary(log_reg, axis=[4, 7.5, 1.5, 4.5])
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
# KNN的决策边界
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_train)
# print(knn_clf.score(X_test, y_test))
# plot_decision_boundary(knn_clf, axis=[4, 7.5, 1.5, 4.5])
# plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red')
# plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue')
# plt.show()
# KNN多分类的决策边界
knn_clf_all = KNeighborsClassifier(n_neighbors=50)
knn_clf_all.fit(iris.data[:, :2], iris.target)
plot_decision_boundary(knn_clf_all, axis=[4, 8, 1.5, 4.5])
plt.scatter(iris.data[iris.target == 0, 0], iris.data[iris.target == 0, 1], color='red')
plt.scatter(iris.data[iris.target == 1, 0], iris.data[iris.target == 1, 1], color='blue')
plt.scatter(iris.data[iris.target == 2, 0], iris.data[iris.target == 2, 1], color='green')
plt.show()
运行结果
![]()
这个样子的决策边界比之前的样子要规整了很多。整体分成了三大块。
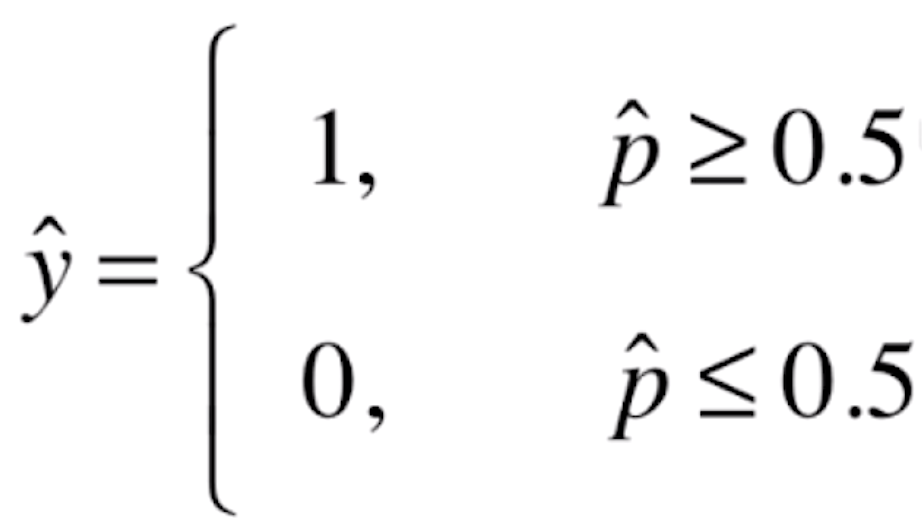
 它的
它的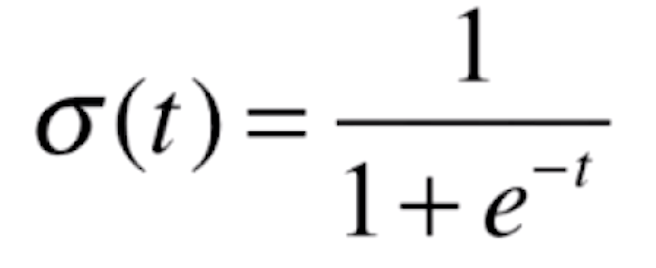
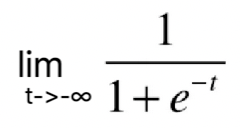 =0,
=0,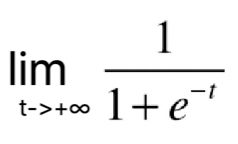 =1。当我们画上纵轴
=1。当我们画上纵轴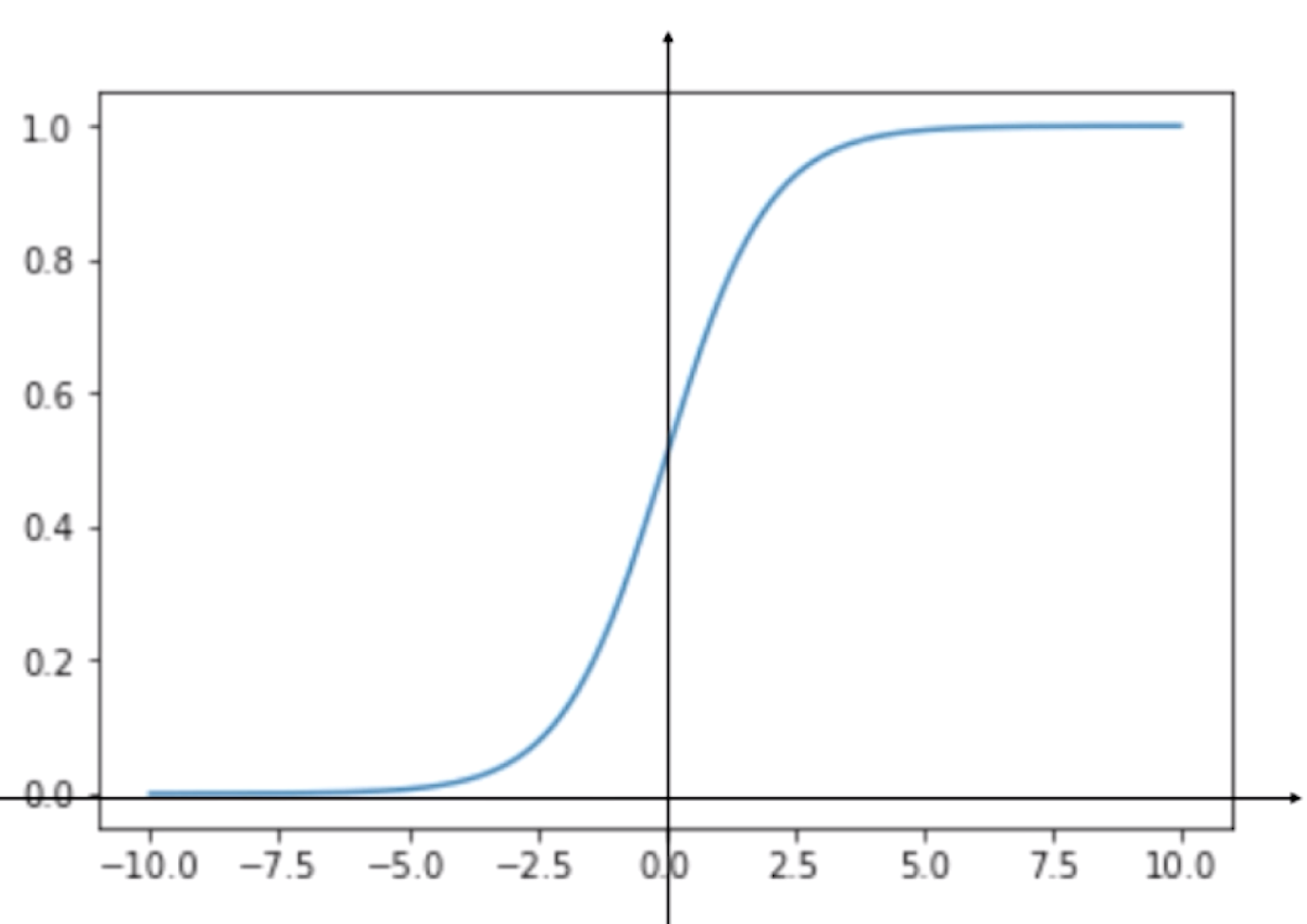
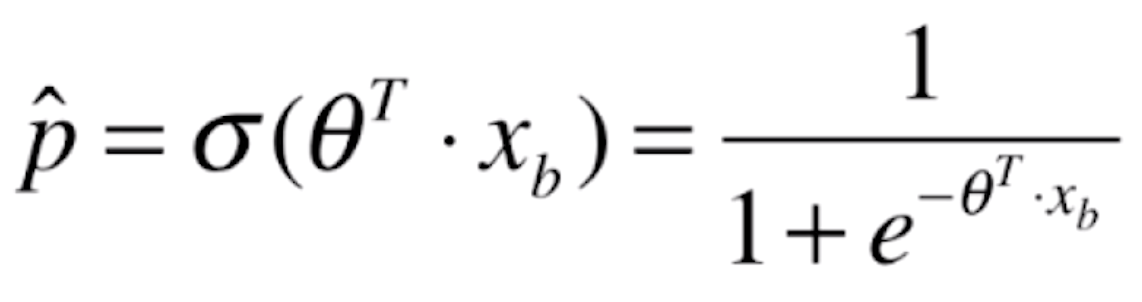 ,
,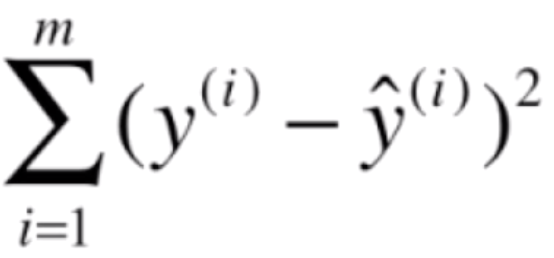 ,而
,而
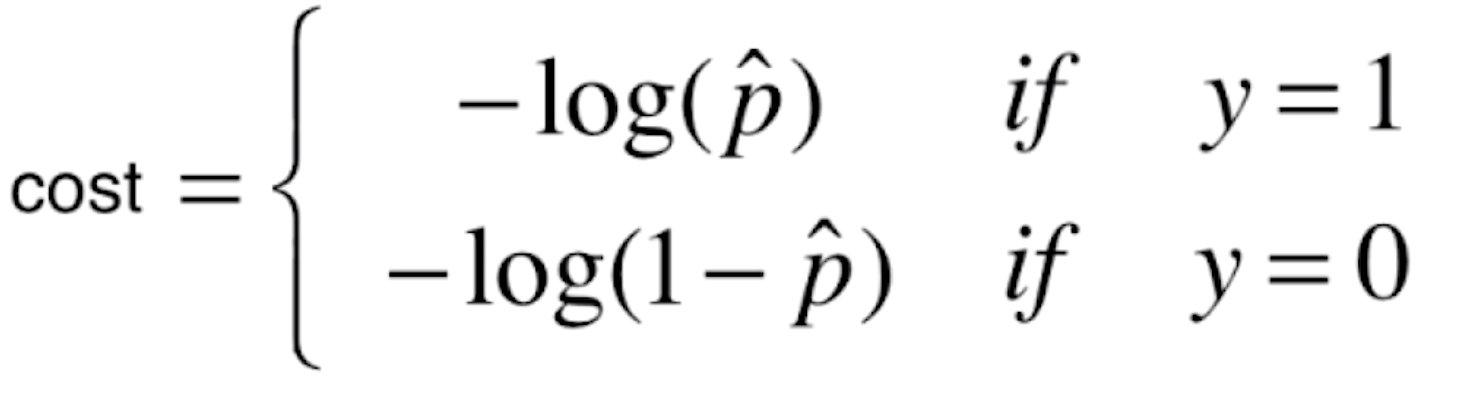
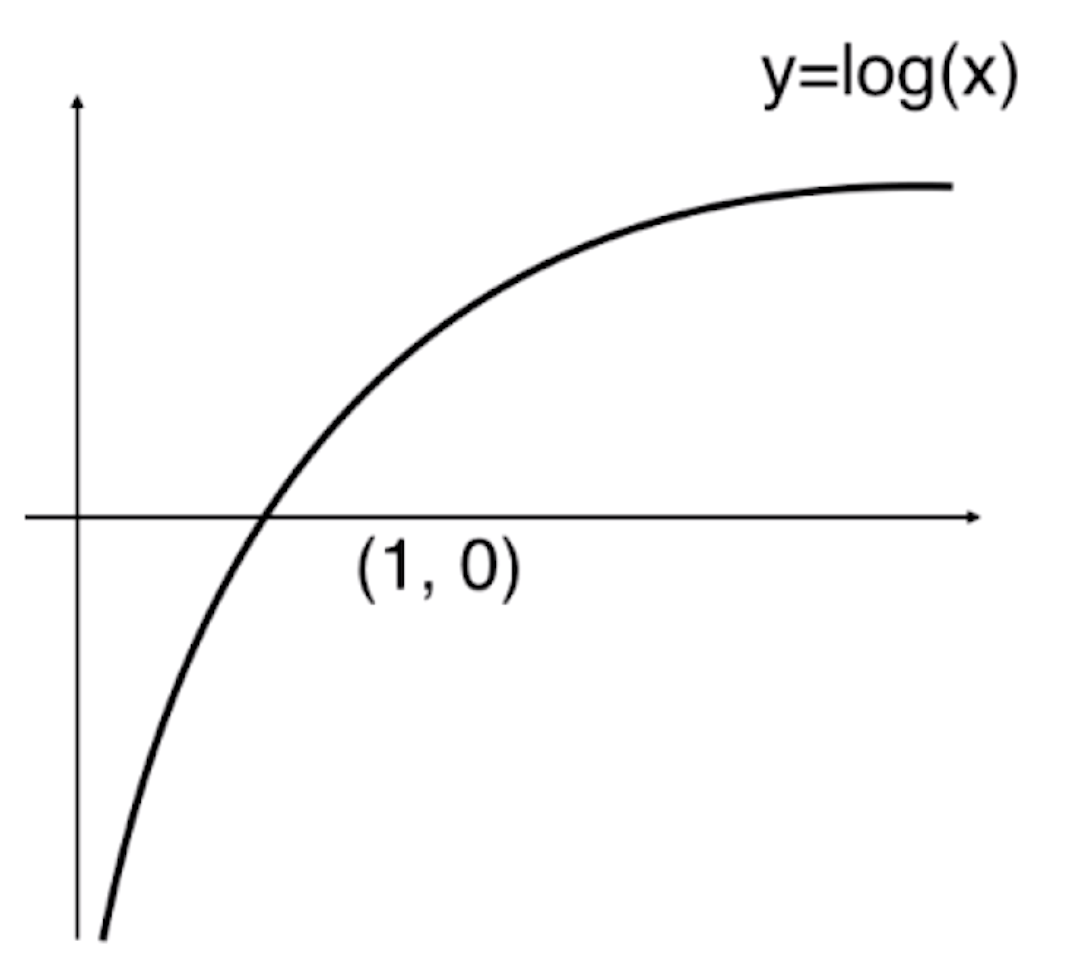
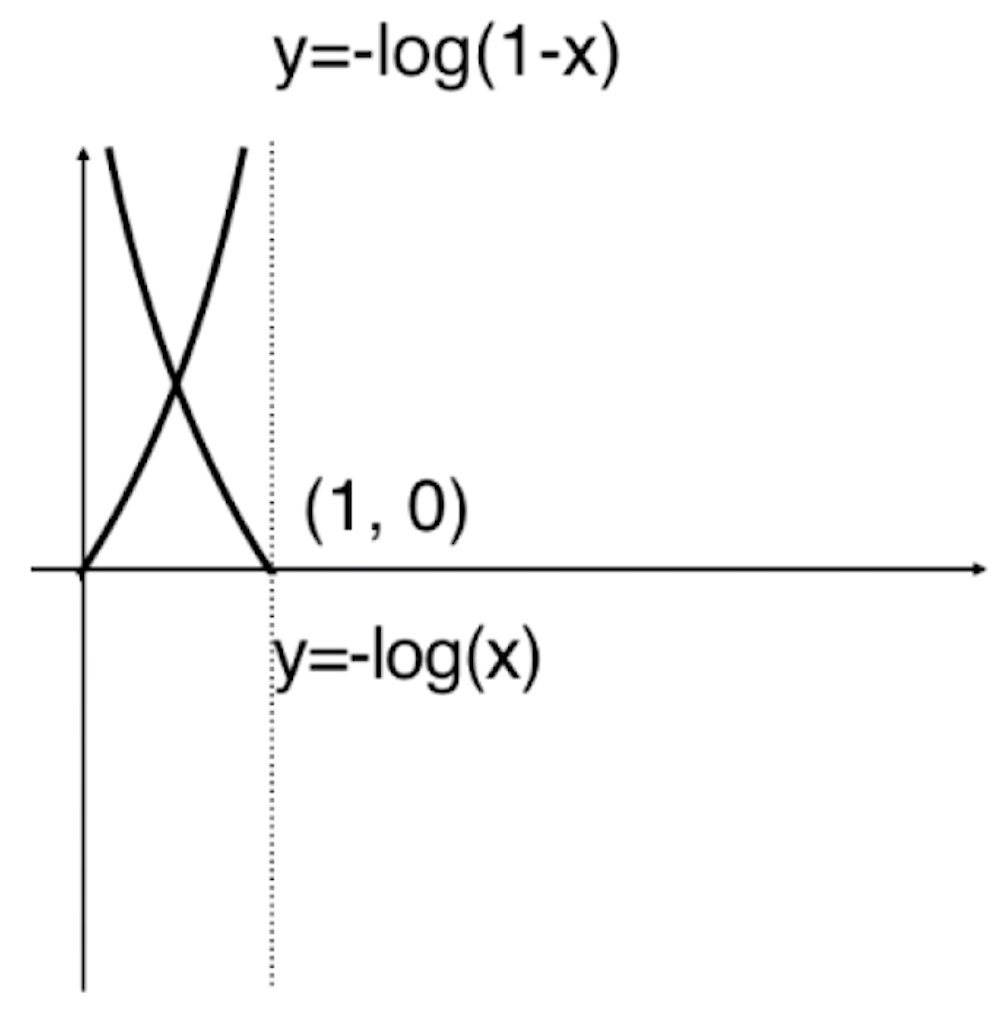
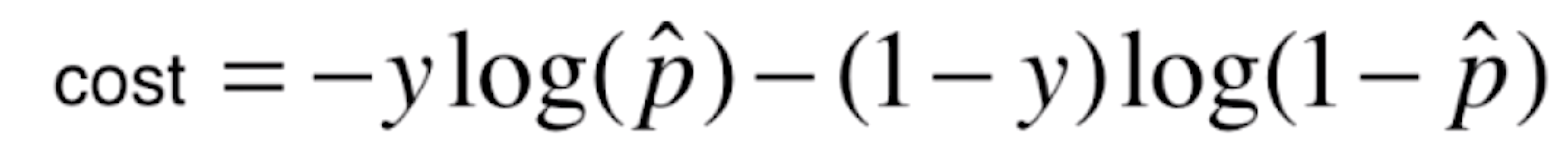 ,这个函数和上面的分类函数是等价的,原因也很简单,当y=1的时候,该式就等于
,这个函数和上面的分类函数是等价的,原因也很简单,当y=1的时候,该式就等于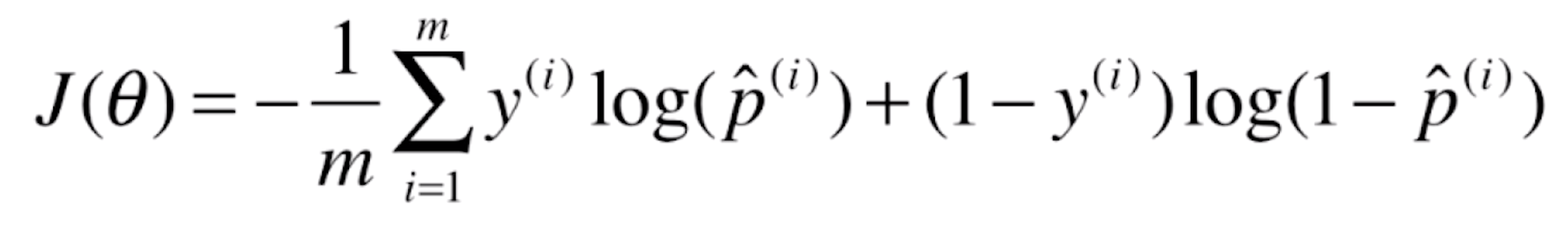
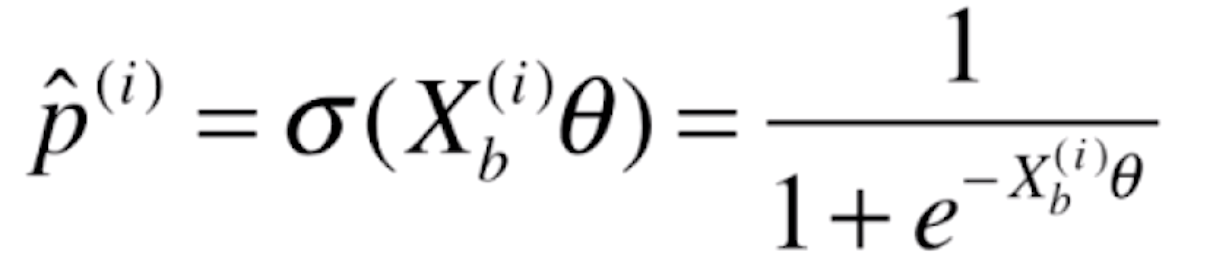
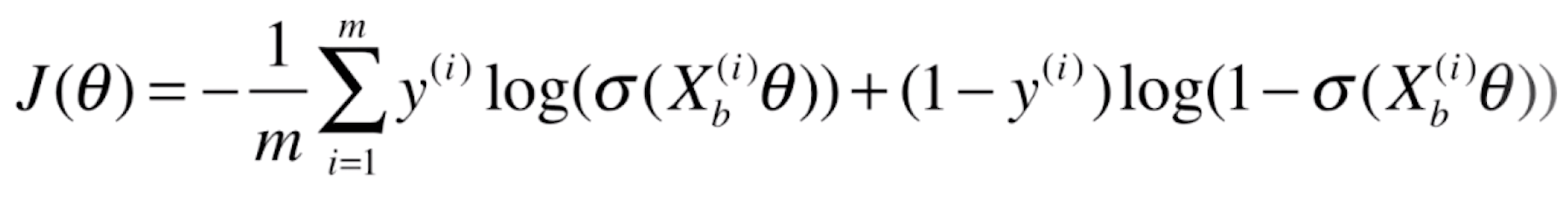
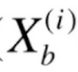 表示,以及对应的输出标记,用
表示,以及对应的输出标记,用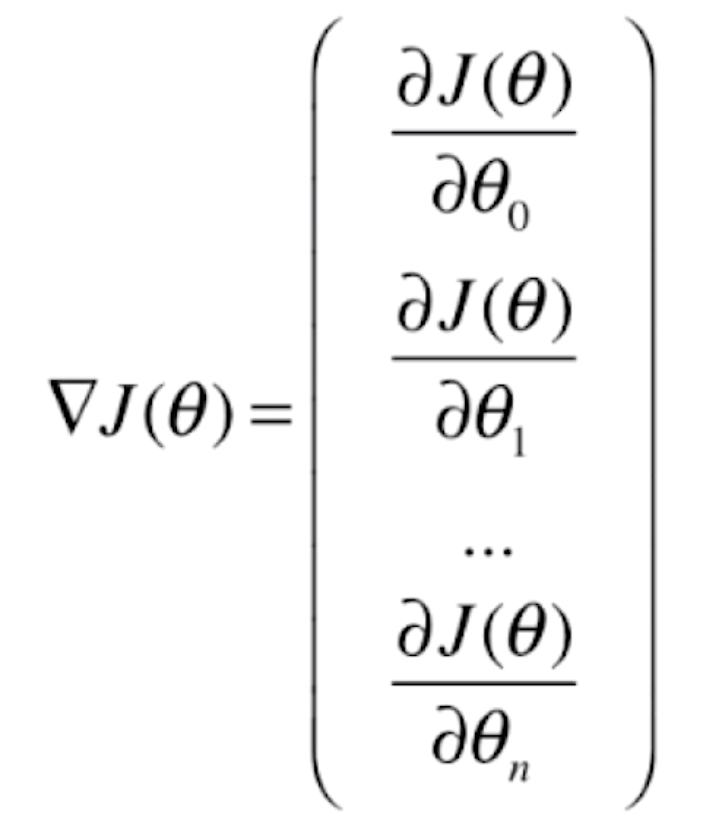
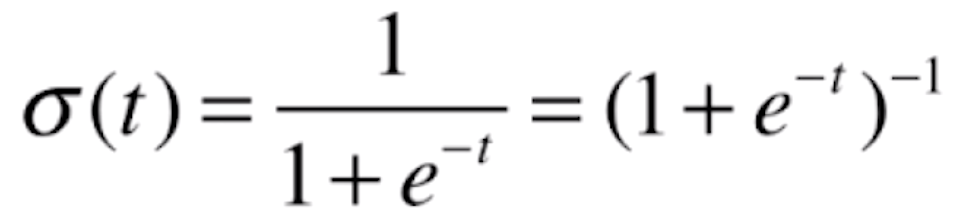 求导
求导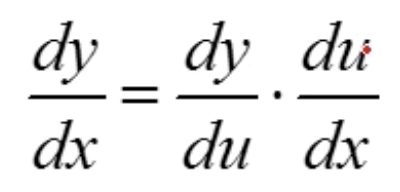 ,令a=-t,b=e^-t,c=
,令a=-t,b=e^-t,c=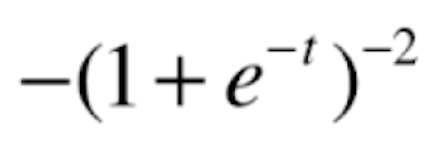
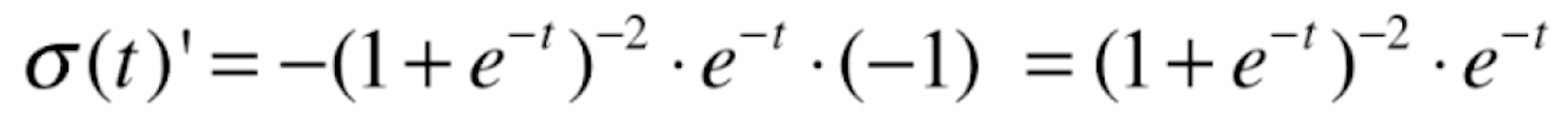
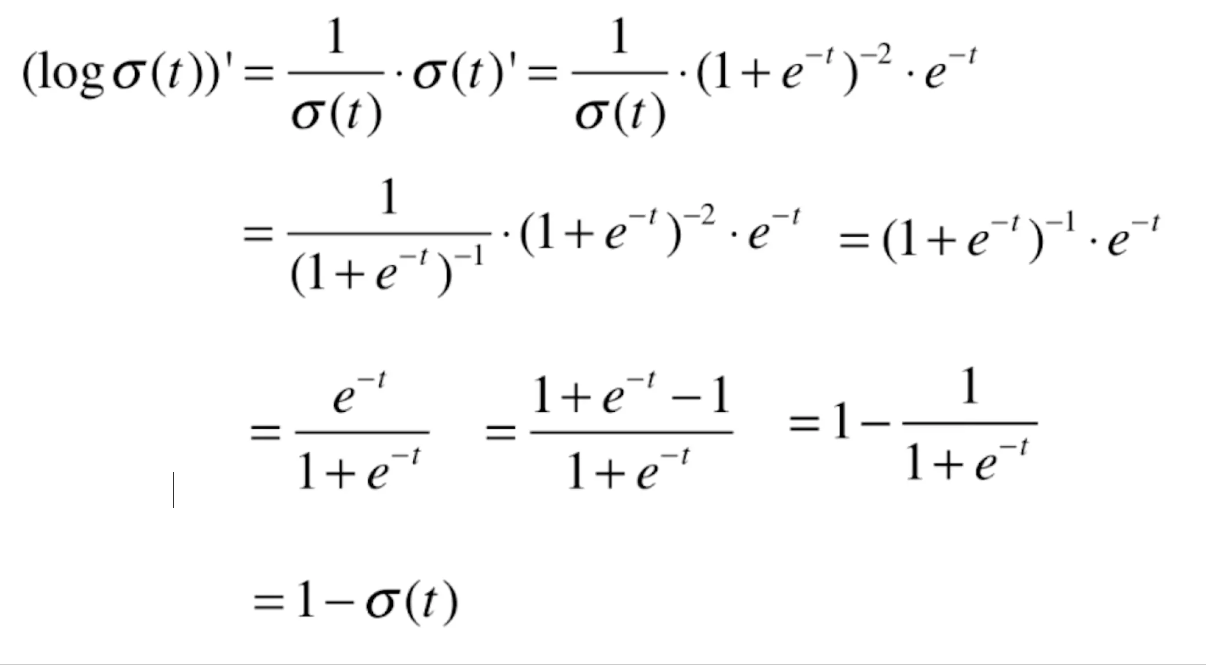
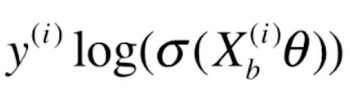 的导数就为(这里同样也是复合函数求导,
的导数就为(这里同样也是复合函数求导,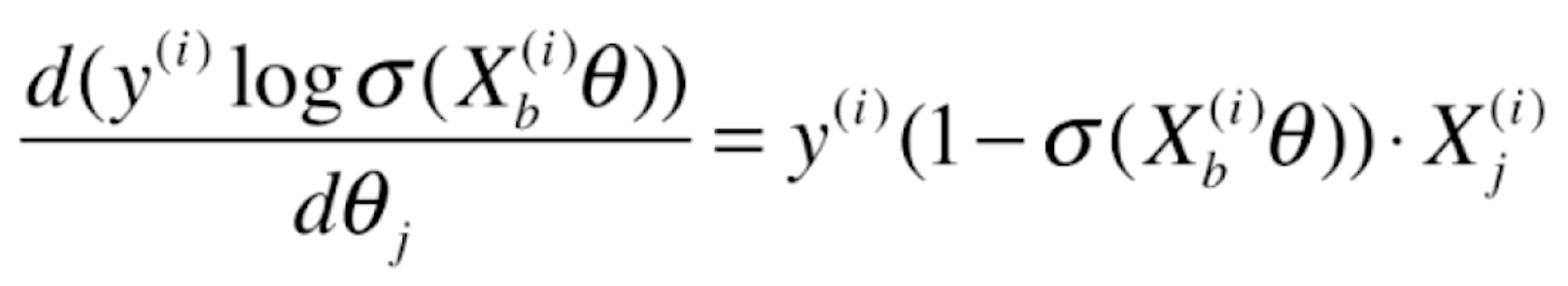
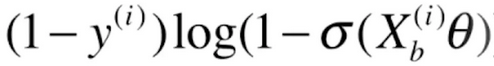 ,我们先看一下
,我们先看一下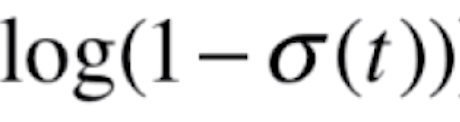 的导数,它同样是一个复合函数,a=logx,b=1-x,c=
的导数,它同样是一个复合函数,a=logx,b=1-x,c=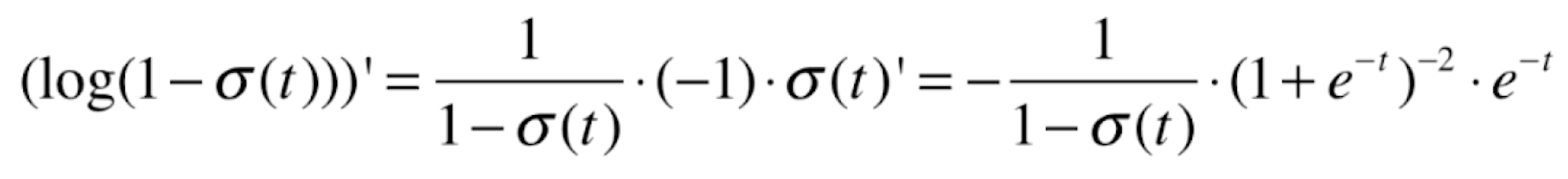
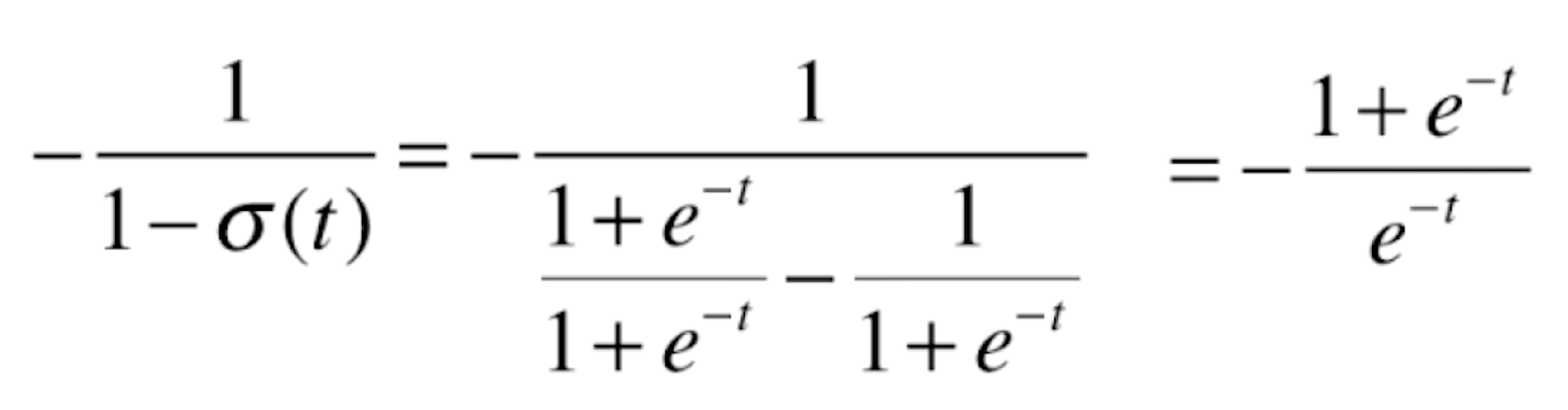 ,代入上式,可得
,代入上式,可得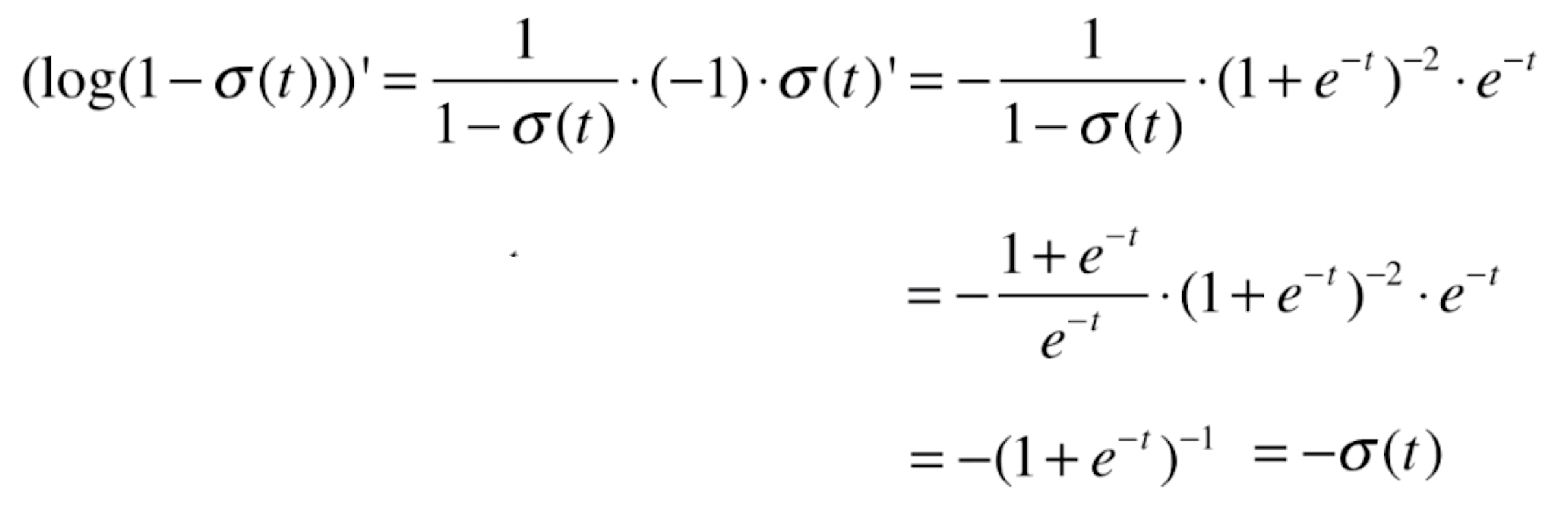
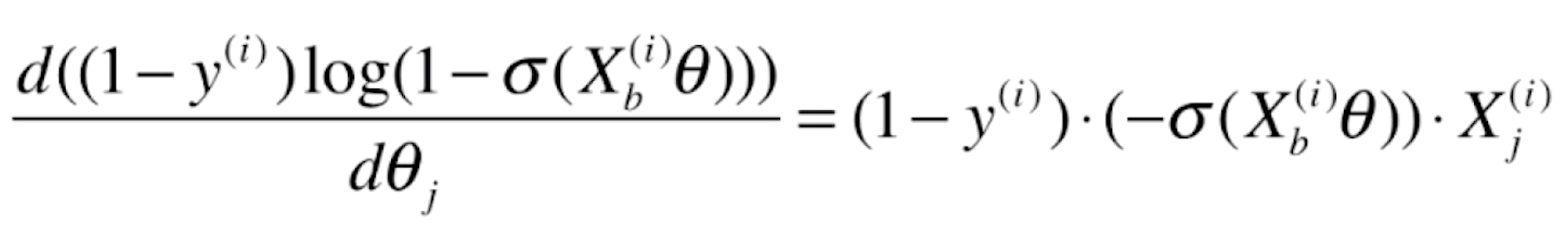
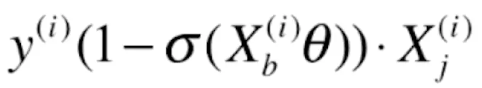 =
=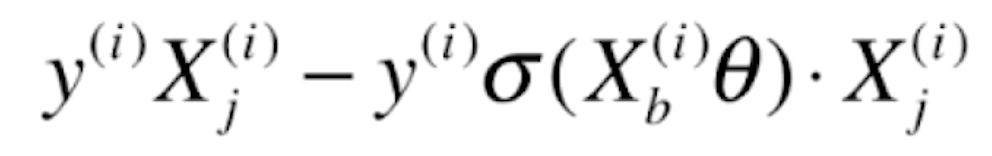
 =
=