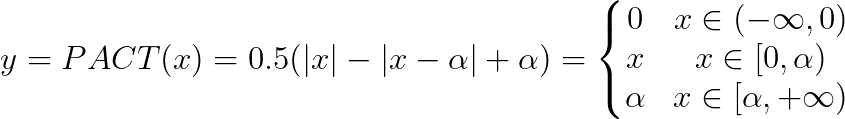随着 FaceID 人脸识别技术在手机、IoT 等设备的普及,受能耗和设备体积的限制,端上硬件的计算性能和存储能力相对较弱,这给端上人脸识别带来了新的挑战——需要更小更快更强的模型。
为了实现 FaceID 人脸识别技术在移动端上更快更准的运行,量化就成为一个重要手段。量化简单来说,就是用更低比特数据代替原浮点数据,已达到缩小模型的过程。其最核心的挑战,是如何在减少模型数据位宽的同时,保证人脸识别的准确率。为了解决人脸识别速度和精度的平衡问题,就需要考虑整个人脸识别过程中的诸多因素,接下来依次阐述人脸模型量化的好处、使用传统量化面临的问题、百度 FaceID 人脸识别模型量化技术/量化收益、以及对不同芯片的支持情况等。
人脸模型量化的好处
人脸模型量化,是将以往用 32/64bit 表达的浮点数,用 8/16bit 甚至 1bit、2bit 等占用较少内存空间的形式进行存储。
量化之后的好处是:
-
减少模型体积。降低模型存储空间需求,使模型更容易在端上部署。
-
压缩成本。降低端设备内存带宽,及数据访问功耗,使得设备运维成本降低。
-
加速计算。针对支持SIMD(单指令流多数据流)的设备,以128-bit 寄存器为例,单个指令可以同时运算4个32位单精度浮点,或8个16位整型,亦或16个8位整型。显然8位整型数在 SIMD 的加持下,运算速率要更快。在大部分 ARM 芯片上可以实现40%到一倍的加速。
人脸模型使用传统量化面临的问题:精度受损
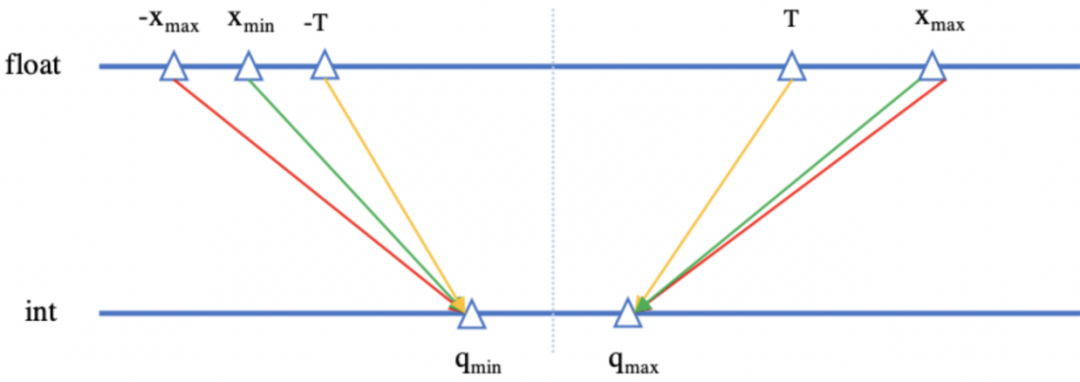
传统的人脸识别模型量化映射方式,是将32bit 浮点数转换成8bit 整数,转换过程分为三种方式:
-
非饱和方式:将模型中浮点数正负绝对值的最大值映射到整数的最大最小值。
-
饱和方式:先计算模型中浮点数的阈值,然后将浮点数的正负阈值映射到整数的最大最小值。
-
仿射方式:将模型中浮点数的最大最小值映射到整数的最大最小值。
![]()
▲ 红色代表非饱和方式
黄色代表饱和方式,绿色代表仿射方式
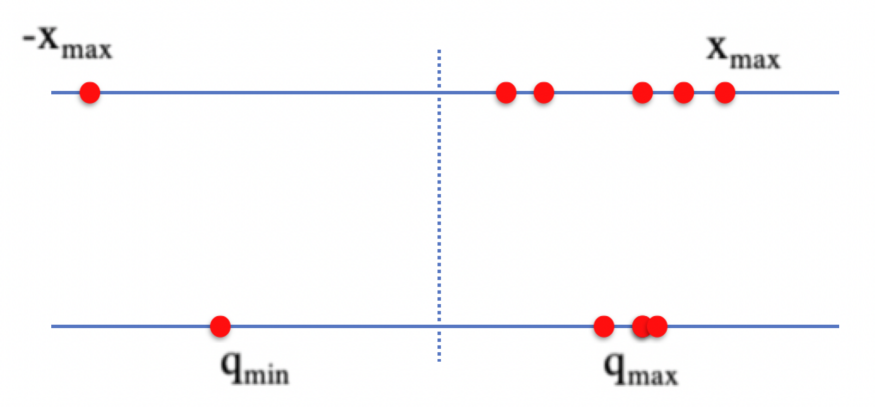
那么,使用传统的量化方式,对人脸识别模型进行量化时,无论哪种映射方式,都会受到离群点、float 参数分布不均匀的影响,造成量化后识别精度损失增加。如图,由于左侧的离群点,使得量化的范围更大,让量化后的右侧数值点变的过度密集,增大了量化损失。
![]()
百度大脑 FaceID 人脸识别模型量化原理
针对人脸识别模型量化过程中的精度损失情况,百度 FaceID 团队通过对量化技术的研究总结,发现模型量化主要包括两个部分,一是对权重 Weight 量化,一是针对激活值 Activation 量化。同时对两部分进行量化,才能获得最大的计算效率收益。
针对模型权重 Weight 量化,百度 FaceID 人脸识别技术研究人员在做模型训练的时候,加入了网络正则化等手段,实现了让权重分布更紧凑,减少了离群点、不均匀分布等情况的发生。
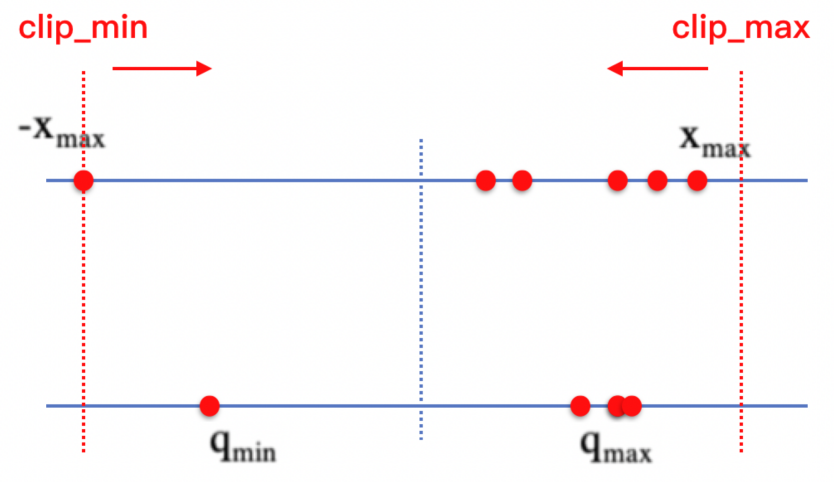
针对激活值 Activation 量化,百度研究人员采用了一种全新的量化方法,在量化激活值之前,去掉一些离群点来降低模型量化带来的精度损失。百度提出截断式的激活函数,该截断的上界,即 α 是可学习的参数,这保证了每层能够通过训练学习到不一样的量化范围,最大程度降低量化带来的舍入误差。
![]()
如上图,百度 FaceID 人脸识别模型的量化的方法是,不断裁剪激活值范围,使得激活值分布收窄,从而降低量化映射损失。具体量化公式如下:
![]()
通过对激活数值做裁剪,从而减少激活分布中的离群点,使量化模型能够得到一个更合理的量化 scale,降低量化损失。
百度大脑 FaceID 人脸识别模型量化收益
人脸识别模型作为 FaceID 端人脸识别技术中体积最大、模型最耗时、对结果影响最直接的模块,如何有效的对模型进行加速的同时保证模型精度不变显得至关重要。结合百度自研的量化技术及 PaddleLite 预测库加速,我们实现了在 RK3288 ARM 芯片上有一倍的加速,同时可以保持模型精度不变。
百度大脑 FaceID 人脸识别模型量化技术对不同芯片的支持
百度 FaceID 人脸识别量化技术不仅在 ARM 系列芯片上验证有效,在不同 NPU 芯片上也取得了不俗效果。其中针对目前常用海思3559、RV1109 两款芯片做了量化前后速度及精度对比。在不同芯片上,量化技术都能在速度及精度上取得最佳平衡,实现精度几乎不降的同时加速1倍左右。针对不同芯片做了不同模型适配,目前已支持17款芯片 SDK 专项适配,助力不同客户业务开发需求落地。
推荐阅读:
被“监控”的打工人:因算法裁定“效率低下”,近150名员工遭解雇