你是否曾想在TensorFlow或PyTorch编写的代码中使用二阶优化器?使用SciPy最小化来优化一个张量字典呢?如果是这样,可能需要很多麻烦的代码。对于另一种方法,请看dict-minimize包,它兼顾一切,让用户轻松优化在TensorFlow、PyTorch或JAX中实现的目标。
背景
现代深度学习框架及其内置的优化工具,都是围绕着用户想要使用随机梯度下降(SGD)或其变体(如ADAM)进行优化的假设而设计的。许多深度学习从业者甚至可能不知道在优化界有大量关于更普遍的方法的文献,这些方法在深度学习兴起之前是占主导地位的。
特别是,像L-BFGS和共轭梯度(CG)这样的方法是前深度学习时代的常用方法(有些人可能还记得使用 minim.m)。那么,是什么改变了呢?在深度学习中,我们要处理巨大的数据集。因此,为训练网络获得准确的梯度需要整个时代的数据,这在计算上是不可行的。因此,我们改用做数据子采样来获得训练损失梯度的随机(无偏)估计,并使用SGD。深度学习的奇迹是,对于训练深度神经网络的权重,使用随机梯度实际上比批量优化效果更好。这是因为隐性正则化和其他原因。
然而,优化不仅仅是训练深度神经网络的权重。对于许多问题来说,准确的梯度是廉价的,像L-BFGS这样的传统优化方法效果更好。它们在默认的超参数下也能很好地工作。相比之下,在SGD的大多数应用中,必须对超参数进行一些调整以获得良好的性能。在适用的情况下,将L-BFGS这样的方法作为优化的一个选项是非常有用的。
传统的精确梯度优化方法已经在scipy-minimize中使用多年了。然而,这些SciPy优化例程对现代用户来说是不方便的。首先,这些例程的SciPy API假定用户已经在NumPy中编码了一个目标函数,并手动编码了它的梯度。现代用户在TensorFlow、PyTorch或JAX等框架中实现他们的目标,这样他们就可以通过自动微分获得梯度,而我们的软件包允许这样做。第二,SciPy API假设用户想要优化一个一维NumPy向量。现代用户希望同时优化几个张量参数的集合。这就是为什么我们实现了我们的包,dict-minimize,作为一个张量的字典。
在Twitter,我们用dict-minimize来训练样本外分类校准器的参数,这些校准器的训练集较小。因为众所周知,深度网络在预测中给出的校准概率很差,所以可以使用少量的保留数据,例如1%,来训练β校准阶段。在这种情况下,精确梯度很便宜,因为用于训练校准器的数据集大小要小得多。较小的校准网络也使反向传播的速度更快。在这种情况下,我们可以对收敛性更有信心,而不需要进行超参数调整,这比我们对SGD更有信心。
使用实例
我们在dict-minimize包中支持TensorFlow、PyTorch、JAX和NumPy,可以互换。无论你对深度学习框架的偏好如何,你都可以使用dict-minimize进行优化。我们也支持NumPy,因为想要优化NumPy数组的字典的用户也不能简单地直接使用SciPy。
在这个例子中,我们展示了如何从PyTorch的实现中优化一个Rosenbrock函数。出于演示的目的,数值被分割成两个参数。
import torch
from dict_minimize.torch_api import minimize
def rosen_obj(params, shift):
"""Based on augmented Rosenbrock from botorch."""
X, Y = params["x_half_a"], params["x_half_b"]
X = X - shift
Y = Y - shift
obj = 100 * (X[1] - X[0] ** 2) ** 2 + 100 * (Y[1] - Y[0] ** 2) ** 2
return obj
def d_rosen_obj(params, shift):
obj = rosen_obj(params, shift=shift)
da, db = torch.autograd.grad(obj, [params["x_half_a"], params["x_half_b"]])
d_obj = OrderedDict([("x_half_a", da), ("x_half_b", db)])
return obj, d_obj
torch.manual_seed(123)
n_a = 2
n_b = 2
shift = -1.0
params = OrderedDict([("x_half_a", torch.randn((n_a,))), ("x_half_b", torch.randn((n_b,)))])
params = minimize(d_rosen_obj, params, args=(shift,), method="L-BFGS-B", options={"disp": True})
复制代码
在上面的代码块中,我们简单地导入
from dict_minimize.torch_api import minimize
复制代码
而不是
This Tweet is unavailable
from scipy.optimize import minimize
复制代码
这个接口与原来的scipy-minimize本质上是一样的。然而,在这里我们使用了一个张量的字典,而不是简单的NumPy向量。同样地,目标函数程序是梯度张量的字典,而不是简单的NumPy向量。对于大多数现代的实际问题来说,这是一个更自然的框架,在这些问题中,有许多不同的参数需要同时进行优化。
在深度梦境中应用Dict-Minimize
即使在深度学习中,也有许多优化的例子,其中准确的梯度不需要在大规模的训练集上评估损失。这些都是可以使用dict-minimize的情况。也许最知名的例子是对抗性例子。在对抗性例子中,梯度是一个在单一训练例子上训练的深度网络的输出。在这些情况下,从业者应用SGD是出于习惯而不是严格的需要。
在这篇博文中,我们看一下另一个可以精确梯度的例子:深度梦境。深度梦想背后的想法是将视觉的深度神经网络的输入可视化,例如InceptionV3,它能使神经网络中的内部层的神经元的反应最大化。它可以作为一个可解释的工具,甚至只是用于艺术。关于深度梦境的工作表明,神经网络的第一层的反应是如何被纹理等低层次的概念最大化的;而深层的反应则是被更高层次的概念最大化的。
深度梦想变得如此流行,以至于它成为了一个标准的TensorFlow演示。由于是在TensorFlow中实现的,作者简单地使用了SGD(可能是由于缺乏可供尝试的替代品)。在这里,我们展示了L-BFGS,在没有任何超参数调整的情况下,如何获得比演示中的SGD更快的收敛。
在这里,我们用L-BFGS优化一幅图像。我们将原始演示中的SGD优化的主循环替换为。
from dict_minimize.tensorflow_api import minimize
lb = OrderedDict({"img": -tf.ones_like(img)})
ub = OrderedDict({"img": tf.ones_like(img)})
params0 = OrderedDict({"img": img})
params = minimize(
deepdream.obj_and_grad_dict,
params0,
lb_dict=lb,
ub_dict=ub,
method="L-BFGS-B",
options={"disp": True, "maxfun": 100},
)
复制代码
请注意,我们可以更自然地表达约束条件,比如图像在白色和黑色之间有界限,使用界限参数。在SGD中,必须周期性地剪辑张量,以确保它保持在界限之内。
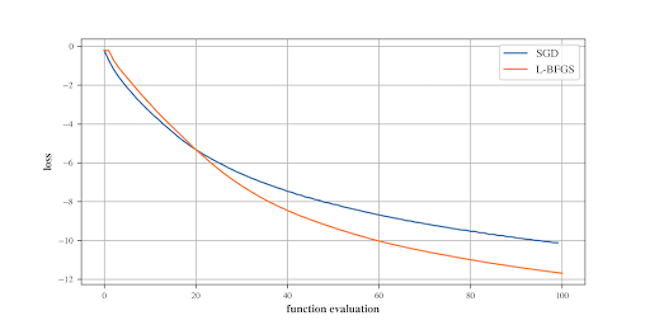
在这个例子中,我们优化了InceptionV3中 "mixed5 "层的神经元1,它是在ImageNet数据集上训练的。这个神经元对类似于鳄鱼皮的纹理有反应。
下面我们看到,默认的L-BFGS在收敛性方面优于调整后的演示中的SGD,是梯度评价的一个函数。
![]()
结论
dict-minimize包提供了方便的选项,可以与现代深度学习框架对接,其中有自动区分功能。更高级的扩展选项有很多。例如,在较小的搜索空间中,当与具有Hessian能力的JAX相结合时,完全的二阶方法如牛顿优化也是可能的。dict-minimize软件包提供了一个简单而方便的接口。当用户有一个新的优化问题时,他们应该考虑它,因为精确的梯度是可以得到的。