JVM执行引擎的效率提升
JVM是如何在保证可移植性的前提下提供高执行效率的?
![]()
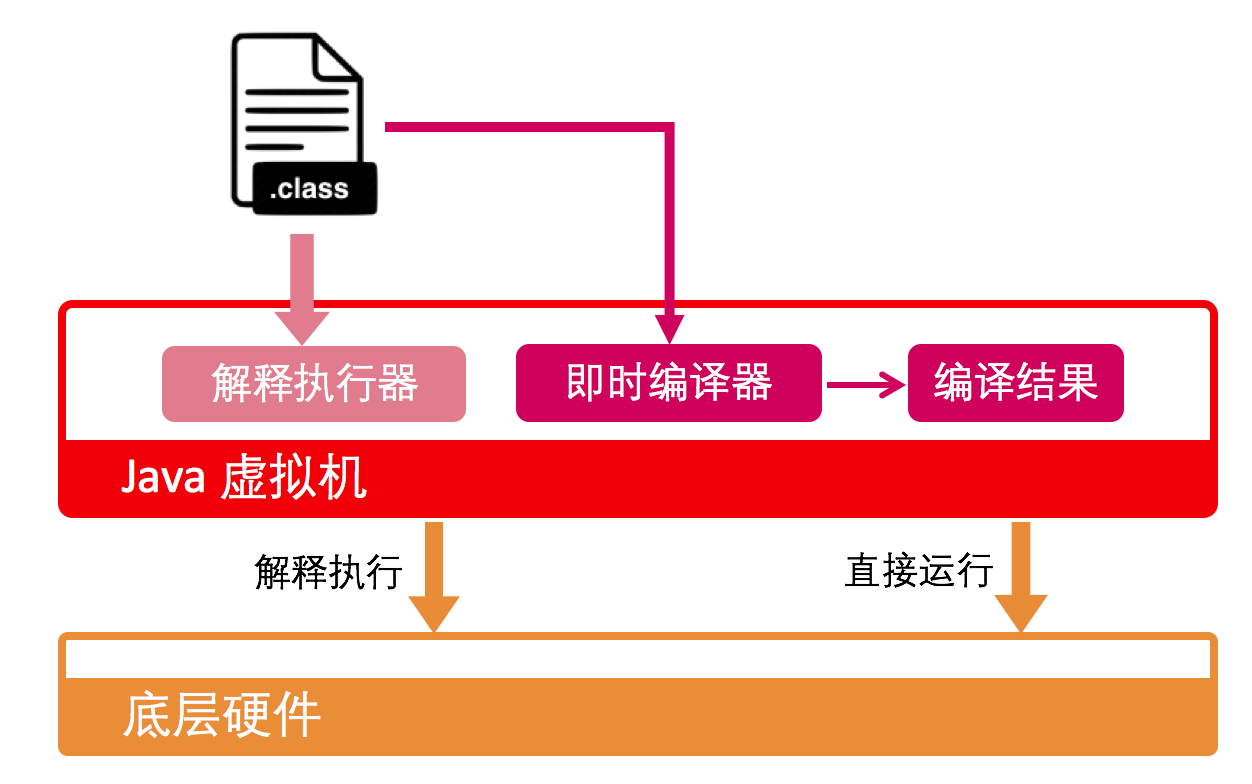
Java跨平台性
Java程序最为常见的执行方式,是预先编译为一种名为 Java 字节码的中间代码格式。这种代码格式无法直接运行在 CPU 之上,而是需要借助 JVM 来执行。换句话说,只要某个平台提供了合乎JVM 规范的实现,它便能执行这份Java 字节码。这也就是我们经常说的“一次编写,到处运行”。
Java执行方式
主流的 OpenJDK/OracleJDK 中所提供的 JVM 叫做HotSpot。它同时采用了解释执行和即时编译。
- 解释执行就好比同声传译,JVM一边理解输入的字节码一边解释字节码生成机器码向CPU发出指令序列;
- 即时编译则是“磨刀不误砍柴工”,JVM 会在运行过程中将 热点代码编译成为可直接执行二进制代码。
这种混合执行模式是建立在程序符合二八定律的假设上,即百分之二十的代码占据了百分之八十的计算资源。对于不常用代码,我们无需耗费时间将其编译成二进制代码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,JVM 则会花费时间将其编译为二进制代码,以达到理想的运行效率。
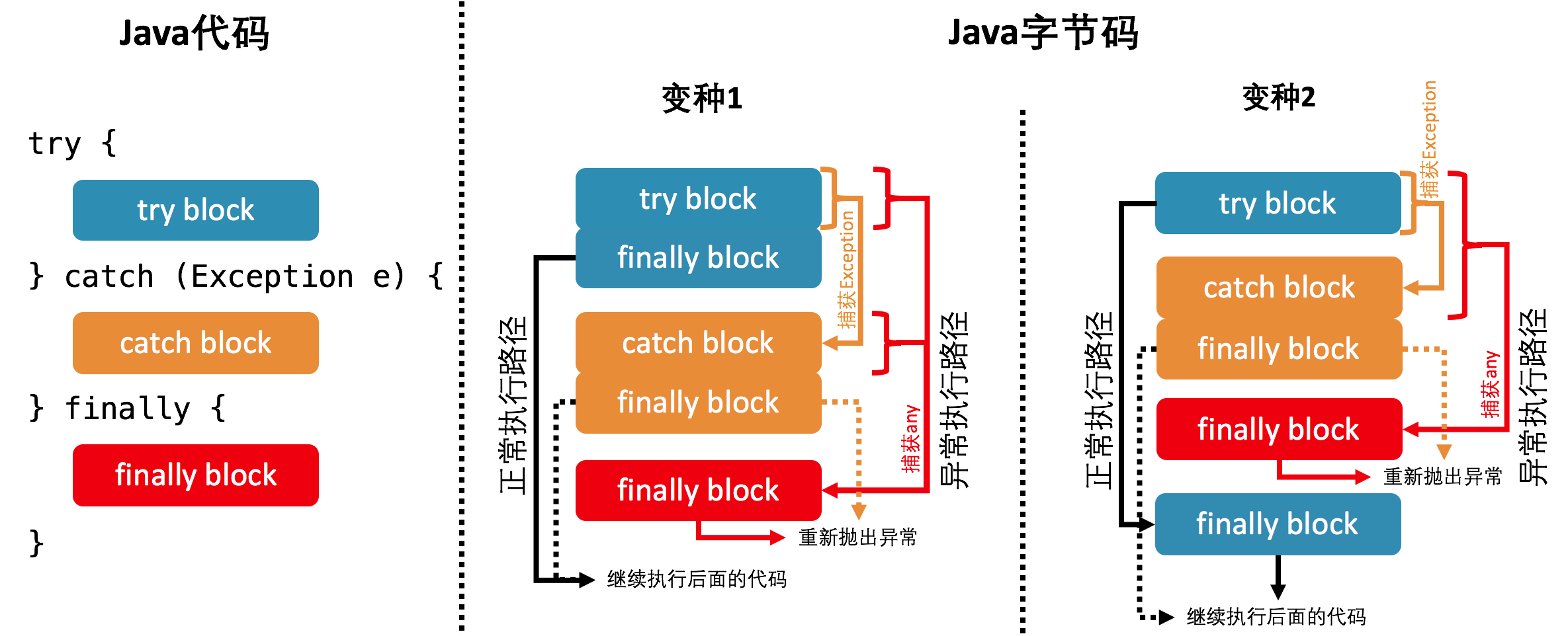
Java异常捕获
![]()
- 编译生成的Java字节码中,每个方法都附带一个异常表。异常表中的每一行均定义了一条异常执行路径,其中包括规定捕获范围的起始字节码索引、终止(不包含)字节码索引,异常处理代码的起始字节码索引,以及所捕获的异常类型。
- 当程序触发异常时,JVM会从上至下遍历异常表中的所有条目。当触发异常的字节码的索引值在某行异常表条目的捕获范围内,JVM 会判断所抛出的异常和该条目想要捕获的异常是否匹配。如果匹配,JVM 会将控制流转移至该条目所指向的异常处理代码。
- 上述异常捕获机制还被用于 finally 从句的实现。通常,Java程序的编译器javac会复制多份 finally 代码块,放置于生成的 Java 字节码之中,然后通过生成多行异常表条目,来实现完整的 finally 逻辑。
![]()
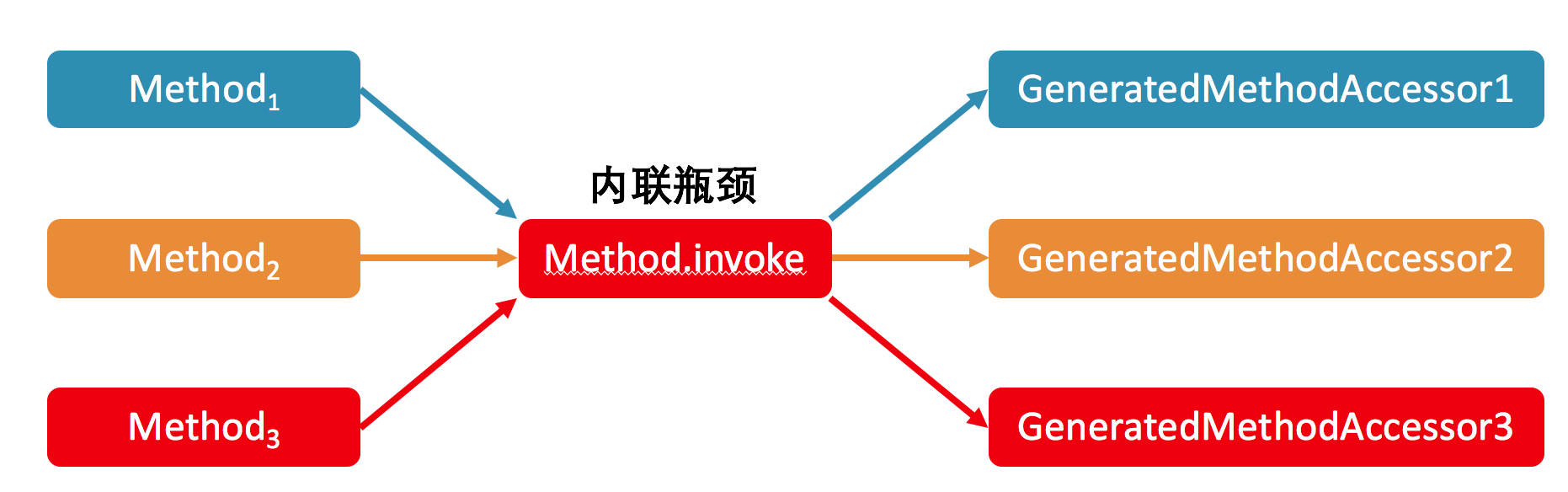
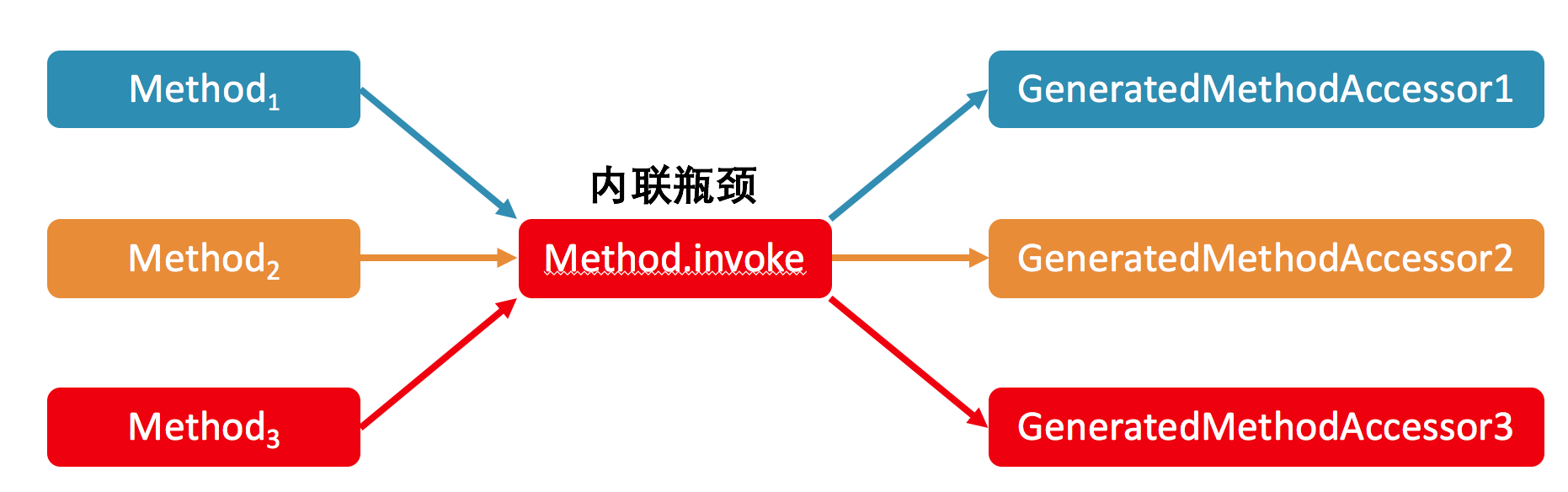
Java反射调用
![]()
- 默认情况下,反射调用首先会被委派给native方法来进行。可想而知,其运行效率低下。当某个反射调用的调用次数达到 15 之后,JDK 代码断定该调用属于热点调用。
- 继而,JDK 将动态生成直接调用目标方法的字节码,并将反射调用的委派对象由原本的 native 方法实现切换至该动态生成的实现。这种方式的运行效率相对于 native 方法来说要高很多。
- 之所以 JDK 不从一开始便采用动态生成字节码的方式,主要是因为生成过程需要耗费一定的时间。对于那些整个生命周期中仅执行数次的反射调用,动态生成字节码将得不偿失。
- 然而,即便是直接调用目标方法的动态实现,其峰值性能也无法跟真正的直接调用相媲美。这背后涉及到即时编译中的虚方法内联。
JVM垃圾回收
![]()
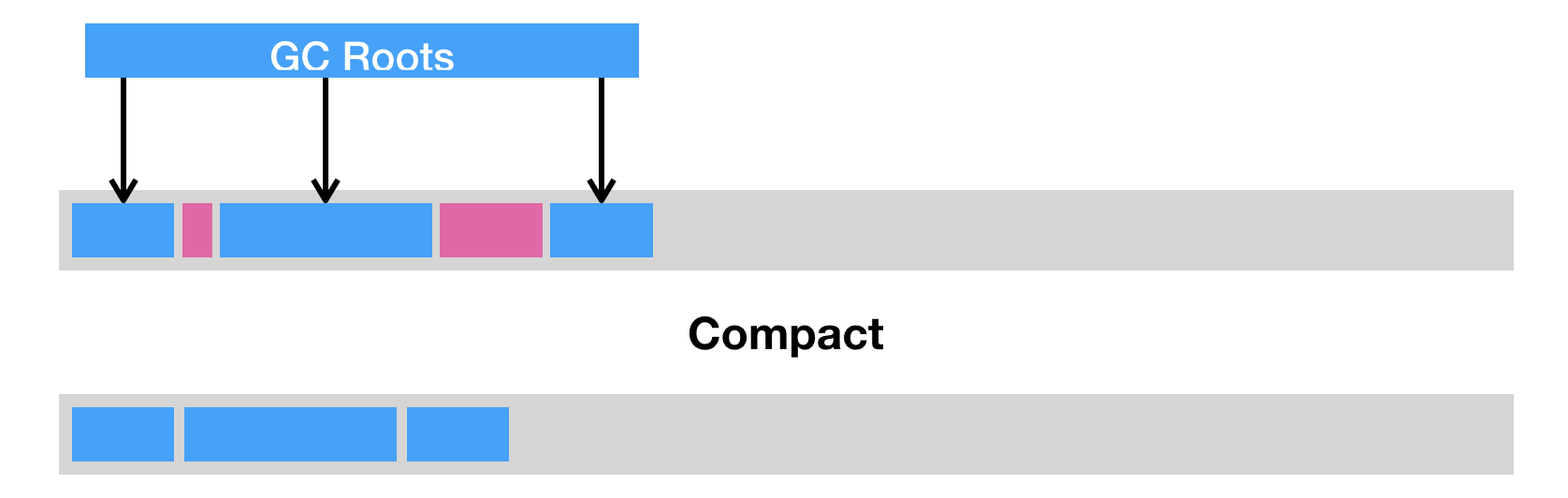
目前 JVM 的主流垃圾回收器采取的都是可达性分析算法。
该算法的实质是将一系列被称为GC Roots的对象作为初始的存活对象合集,然后从该合集出发探索所有能够被该集合引用到的对象,并标记为存活对象。当标记阶段结束之后,未被标记到的对象便是可以清除的。
传统的垃圾回收算法在标记、清除过程中需要中止其他应用线程,即所谓的 Stop-The-World。新型的垃圾回收算法,如 CMS、G1 以及 ZGC,尽可能地实现并发标记、清除,从而让Stop-The-World 的时间长度可控。
垃圾回收的另一基础思想则是分代回收。JVM 会将新生成的对象划为新生代,而将在多次垃圾回收中存活下来的对象划为老年代。JVM 会为不同的分代设置不同的回收算法,从而达到新生代多收集、快收集,老年代少收集、全收集的目标。
Java内存模型
现代计算机多为对称多处理器的体系架构。每个处理器均有独立的寄存器组和缓存(这在 Java 内存模型中被抽象为工作内存);多个处理器可同时执行同一进程中的不同线程。
不同线程可能访问同一变量或对象。如果任由编译器或处理器对这些访问进行优化,则很可能出现在单线程执行思维下无法想象的问题。因此,Java语言规范引入了Java内存模型,通过定义多项规则对编译器和处理器进行限制。
这些规则所体现的最为重要的属性便是可见性,即对某一变量的访问能否被同一线程的其他操作,或者不同线程所观测到。
Java内存模型引入了多种 happens-before 关系,以实现上述可见性。以volatile字段为例,对其的写操作 happens before这之后的读操作,也就是说,我们总能读到volatile字段的最新值。
JVM对象锁
重量级锁是最为基础、最为低效的对象锁实现。JVM会阻塞加锁失败的线程,并且在目标锁被释放的时候,唤醒这些线程。我们用等红灯作类比。Java线程进入阻塞状态相当于熄火停车,再次点火启动必然耗费时间。JVM 会在进入阻塞状态之前进行自旋,也就是怠速停车。如果目标锁能够在短时间内被释放出来,该线程便能够不进入阻塞状态,直接获取该锁。
重量级锁针对的是多个线程同时竞争同一把锁的场景。在现实中,多个线程可能在不同时间段持有同一把锁。为了应对这种没有锁竞争的情况,JVM 采用了轻量级锁机制。在加锁时,JVM 将在锁对象处做标记,指向当前线程的栈上;在解锁时,上述标记会被清除。如果某线程在请求锁时,发现该锁为轻量级锁,并且指向另一线程所对应的栈,那么它会将该锁膨胀为重量级锁。
偏向锁所应对的场景则更为乐观:至始至终只有一个线程请求某把锁。JVM 采取的做法是在第一次加锁时为锁对象做标记,使其指向当前线程的地址;在解锁时则不做任何操作。如果下一次请求该锁的仍是同一线程,便直接跳过标记过程;否则,JVM 会将该锁膨胀为轻量级锁。