![]()
关于作者
前滴滴出行技术专家,现任OPPO 文档数据库 mongodb 负责人,负责 oppo 千万级峰值 TPS/ 十万亿级数据量文档数据库 mongodb 研发和运维工作,一直专注于分布式缓存、高性能服务端、数据库、中间件等相关研发。后续持续分享《 MongoDB 内核源码设计、性能优化、最佳运维实践》, Github 账号地址 : https://github.com/y123456yz
序言
Mongodb 内核源码由第三方库 third_party 和 mongodb 服务层源码组成,其中 mongodb 服务层代码在不同模块实现中依赖不同的third_party 库,第三方库是 mongodb 服务层代码实现的基础 ( 例如 : 网络底层 IO 实现依赖 asio-master 库 , 底层存储依赖 wiredtiger 存储引擎库 ) ,其中第三方库也会依赖部分其他库 ( 例如: wiredtiger 库依赖 snappy 算法库, asio-master 依赖 boost 库 ) 。
虽然Mongodb 内核源码数百万行,工程量巨大,但是 mongodb 服务层代码实现层次非常清晰,代码目录结构、类命名、函数命名、文件名命名都非常一目了然,充分体现了 10gen 团队的专业精神。
说明:mongodb 内核除第三方库 third_party 外的代码,这里统称为 mongodb 服务层代码。
本文以mongodb 服务层 transport 实现为例来说明如何快速阅读整个 mongodb 代码,我们在走读代码前,建议遵循如下准则。
1. 熟悉 mongodb 基本功能和使用方法
首先,我们需要熟悉mongodb 的基本功能,明白 mongodb 是做什么用的,用在什么地方,这样才能体现 mongodb 的真正价值。此外,我们需要提前搭建一个 mongodb 集群玩一玩,这样也可以进一步促使我们了解 mongodb 内部的一些常用基本功能。千万不要急于求成,如果连mongodb 是做什么的都不知道,或者连 mongodb 的运维操作方法都没玩过,直接读取代码会非常不适合,没有目的的走读代码不利于分析整个代码,同时阅读代码过程会非常痛苦。
2. 下载代码编译源码
熟悉了mongodb 的基本功能,并搭建集群简单体验后,我们就可以从 github 下载源码,自己编译源码生成二进制文件,编译文档存放于docs/building.md 代码目录中,源码编译步骤如下 :
1. 下载对应releases 中对应版本的源码
2. 进入对于目录,参考docs/building.md 文件内容进行相关依赖工具安装
3. 执行buildscripts/scons.py 编译出对应二进制文件,也可以直接 scons mongod mongos 这样编译。
4. 编译成功后的生产可执行文件存放于./build/opt/mongo/ 目录
在正在编译代码并运行的过程中,发现以下两个问题:
1. 编译出的二进制文件占用空间很大,如下图所示:
![]()
![]()
从上图可以看出,通过strip处理工具处理后,二进制文件大小已经和官方二进制包大小一样了。
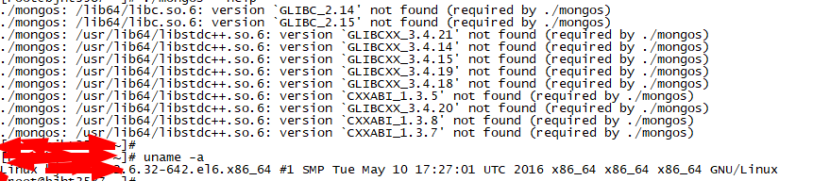
2. 在一些低版本操作系统运行的时候出错,找不到对应stdlib库,如下图所示:
![]()
如上图所示,当编译出的二进制文件拷贝到线上运行后,发现无法运行,提示libstdc库找不到。原因是我们编译代码时候依赖的stdc库版本比其他操作系统上面的stdc库版本更高,造成了不兼容。
解决办法:编译的时候编译脚本中带上-static-libstdc++,把stdc库通过静态库的方式进行编译,而不是通过动态库方式。
3. 了解代码日志模块使用方法,试着加打印调试
由于前期我们对代码整体实现不熟悉,不知道各个接口的调用流程,这时候就可以通过加日志打印进行调试。Mongodb的日志模块设计的比较完善,从日志中可以很明确的看出由那个功能模块打印日志,同时日志模块有多种打印级别。
1. 日志打印级别设置
启动参数中verbose设置日志打印级别,日志打印级别设置方法如下:Mongod -f ./mongo.conf -vvvv
这里的v越多,表明日志打印级别设置的越低,也就会打印更多的日志。一个v表示只会输出LOG(1)日志,-vv表示LOG(1) LOG(2)都会写日志。
2. 如何在.cpp文件中使用日志模块记录日志
如果需要在一个新的.cpp文件中使用日志模块打印日志,需要进行如下步骤操作:
i) 添加宏定义 #define MONGO_LOG_DEFAULT_COMPONENT ::mongo::logger::LogComponent::kExecutor
ii) 使用LOG(N)或者log()来记录想要输出的日志内容,其中LOG(N)的N代表日志打印级别,log()对应的日志全记录到文件。
例如: LogComponent::kExecutor代表executor模块相关的日志,参考log_component.cpp日志模块文件实现,对应到日志文件内容如下:
![]()
4. 学会用gdb调试mongodb代码
Gdb是linux系统环境下优秀的代码调试工具,支持设置断点、单步调试、打印变量信息、获取函数调用栈信息等功能。gdb工具可以绑定某个线程进行线程级调试,由于mongodb是多线程环境,因此在用gdb调试前,我们需要确定调试的线程号,mongod进程包含的线程号及其对应线程名查看方法如下:
注意:在调试mongod工作线程处理流程的时候,不要选择adaptive动态线程池模式,因为线程可能因为流量低引起工作线程不饱和而被销毁,从而造成调试过程因为线程销毁而中断,synchronous线程模式是一个链接一个线程,只要我们不关闭这个链接,线程就会一直存在,不会影响我们理解mongodb服务层代码实现逻辑。 synchronous线程模式调试的时候可以通过mongo shell链接mongod服务端端口来模拟一个链接,因此调试过程相对比较可控。
在对工作线程调试的时候,发现gdb无法查找到mongod进程的符号表,无法进行各种gdb功能调试,如下图所示:
上述gdb无法attach到指定线程调试的原因是无法加载二进制文件符号表,这是因为编译的时候没有加上-g选项引起,mongodb通过SConstruct脚本来进行scons编译,要启用gdb功能需要在scons编译代码的时候指定gdbserver选项:scons --gdbserver=GDBSERVER -j 2。
编译出新的二进制文件后,就可以gdb调试了,如下图所示,可以很方便的定位到某个函数之前的调用栈信息,并进行单步、打印变量信息等调试:
5. 熟悉代码目录结构、模块细化拆分
在进行代码阅读前还有很重要的一步就是熟悉代码目录及文件命名实现,mongodb服务层代码目录结构及文件命名都有很严格的规范。下面以truansport网络传输模块为例,transport模块的具体目录文件结构:
从上面的文件分布内容,可以清晰的看出,整个目录中的源码实现文件大体可以分为如下几个部分:
- message_compressor_*网络传输数据压缩子模块
- service_entry_point*服务入口点子模块
- service_executor*服务运行子模块,即线程模型子模块
- service_state_machine*服务状态机处理子模块
- Session*回话信息子模块
- Ticket*数据分发子模块
- transport_layer*套接字处理及传输层模式管理子模块
![]()
通过上面的拆分,整个大的transport模块实现就被拆分成了7个小模块,这7个小的子模块各自负责对应功能实现,同时各个模块相互衔接,整体实现网络传输处理过程的整体实现,下面的章节将就这些子模块进行简单功能说明。
6. 从main入口开始大体走读代码
前面5个步骤过后,我们已经熟悉了mongodb编译调试以及transport模块的各个子模块的相关代码文件实现及大体子模块作用。至此,我们可以开始走读代码了,mongos和mongod的代码入口分别在mongoSMain()和mongoDbMain(),从这两个入口就可以一步一步了解mongodb服务层代码的整体实现。
注意:走读代码前期不要深入各种细节实现,大体了解代码实现即可,先大体弄明白代码中各个模块功能由那些子模块实现,千万不要深究细节。
7. 总结
本章节主要给出了数百万级mongodb内核代码阅读的一些建议,整个过程可以总结为如下几点:
- 提前了解mongodb的作用及工作原理。
- 自己搭建集群提前学习下mongodb集群的常用运维操作,可以进一步帮助理解mongodb的功能特性,提升后期代码阅读的效率。
- 自己下载源码编译二进制可执行文件,同时学会使用日志模块,通过加日志打印的方式逐步开始调试。
- 学习使用gdb代码调试工具调试线程的运行流程,这样可以更进一步的促使快速学习代码处理流程,特别是一些复杂逻辑,可以大大提升走读代码的效率。
- 正式走读代码前,提前了解各个模块的代码目录结构,把一个大模块拆分成各个小模块,先大体浏览各个模块的代码实现。
- 前期走读代码千万不要深入细节,捋清楚各个模块的大体功能作用后再开始一步一步的深入细节,了解深层次的内部实现。
- 从main()入口逐步开始走读代码,结合log日志打印和gdb调试。
- 跳过整体流程中不熟悉的模块代码,只走读本次想弄明白的模块代码实现。