
一文解开java中字符串编码的小秘密
简介
在本文中你将了解到Unicode和UTF-8,UTF-16,UTF-32的关系,同时你还会了解变种UTF-8,并且探讨一下UTF-8和变种UTF-8在java中的应用。
一起来看看吧。
Unicode的发展史
在很久很久以前,西方世界出现了一种叫做计算机的高科技产品。
初代计算机只能做些简单的算数运算,还要使用人工打孔的程序才能运行,不过随着时间的推移,计算机的体积越来越小,计算能力越来越强,打孔已经不存在了,变成了人工编写的计算机语言。
一切都在变化,唯有一件事情没有变化。这件事件就是计算机和编程语言只流传在西方。而西方日常交流使用26个字母加有限的标点符号就够了。
最初的计算机存储可以是非常昂贵的,我们用一个字节也就是8bit来存储所有能够用到的字符,除了最开始的1bit不用以外,总共有128中选择,装26个小写+26个大写字母和其他的一些标点符号之类的完全够用了。
这就是最初的ASCII编码,也叫做美国信息交换标准代码(American Standard Code for Information Interchange)。
后面计算机传到了全球,人们才发现好像之前的ASCII编码不够用了,比如中文中常用的汉字就有4千多个,怎么办呢?
没关系,将ASCII编码本地化,叫做ANSI编码。1个字节不够用就用2个字节嘛,路是人走出来的,编码也是为人来服务的。于是产生了各种如GB2312, BIG5, JIS等各自的编码标准。这些编码虽然与ASCII编码兼容,但是相互之间却并不兼容。
这严重的影响了国际化的进程,这样还怎么去实现同一个地球,同一片家园的梦想?
于是国际组织出手了,制定了UNICODE字符集,为所有语言的所有字符都定义了一个唯一的编码,unicode的字符集是从U+0000到U+10FFFF这么多个编码。
那么unicode和UTF-8,UTF-16,UTF-32有什么关系呢?
unicode字符集最后是要存储到文件或者内存里面的,直接存储的话,空间占用太大。那怎么存呢?使用固定的1个字节,2个字节还是用变长的字节呢?于是我们根据编码方式的不同,分成了UTF-8,UTF-16,UTF-32等多种编码方式。
其中UTF-8是一种变长的编码方案,它使用1-4个字节来存储。UTF-16使用2个或者4个字节来存储,JDK9之后的String的底层编码方式变成了两种:LATIN1和UTF16。
而UTF-32是使用4个字节来存储。这三种编码方式中,只有UTF-8是兼容ASCII的,这也是为什么国际上UTF-8编码方式比较通用的原因(毕竟计算机技术都是西方人搞出来的)。
Unicode详解
知道了Unicode的发展史之后,接下来我们详解讲解一下Unicode到底是怎么编码的。
Unicode标准从1991年发布1.0版本,已经发展到2020年3月最新的13.0版本。
Unicode能够表示的字符串范围是0到10FFFF,表示为U+0000到U+10FFFF。
其中U+D800到U+DFFF的这些字符是预留给UTF-16使用的,所以Unicode的实际表示字符个数是216 − 211 + 220 = 1,112,064个。
我们将Unicode的这些字符集分成17个平面,各个平面的分布图如下:

以Plan 0为例,Basic Multilingual Plane (BMP)基本上包含了大部分常用的字符,下图展示了BMP中所表示的对应字符:
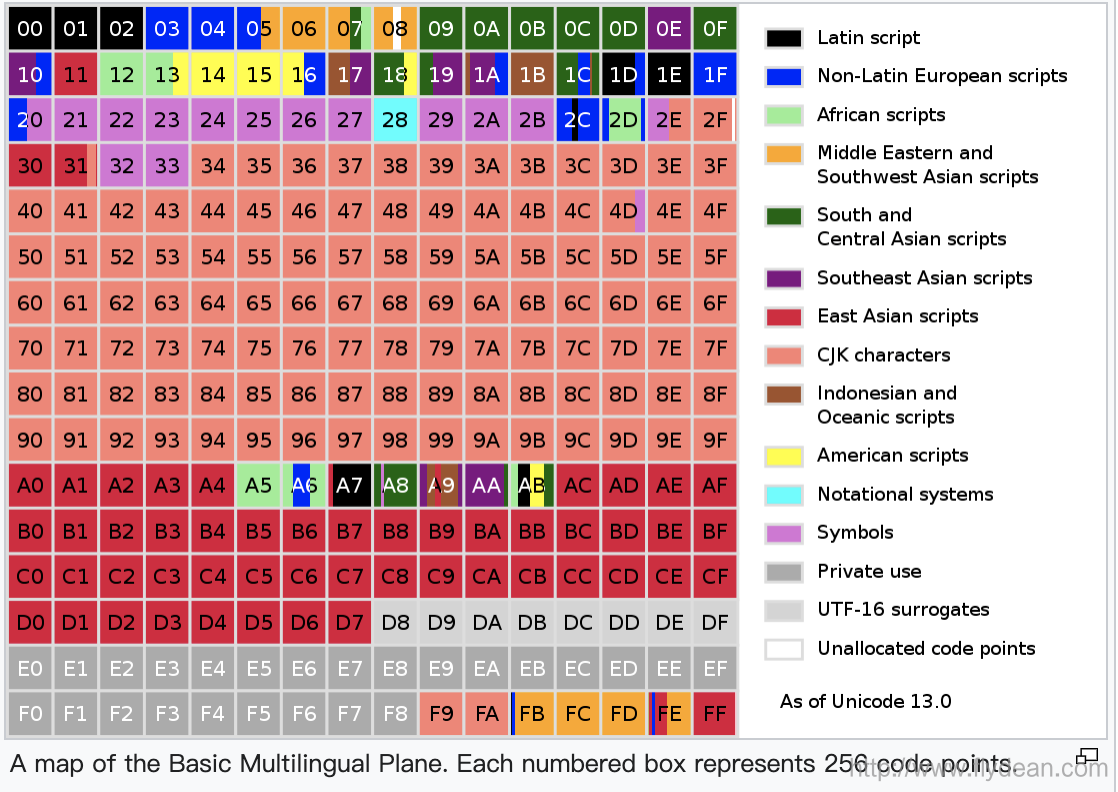
上面我们提到了U+D800到U+DFFF是UTF-16的保留字符。其中高位U+D800–U+DBFF和低位U+DC00–U+DFFF是作为一对16bits来对非BMP的字符进行UTF-16编码。单独的一个16bits是无意义的。
UTF-8
UTF-8是用1到4个字节来表示所有的1,112,064个Unicode字符。所以UTF-8是一种变长的编码方式。
UTF-8目前是Web中最常见的编码方式,我们看下UTF-8怎么对Unicode进行编码:
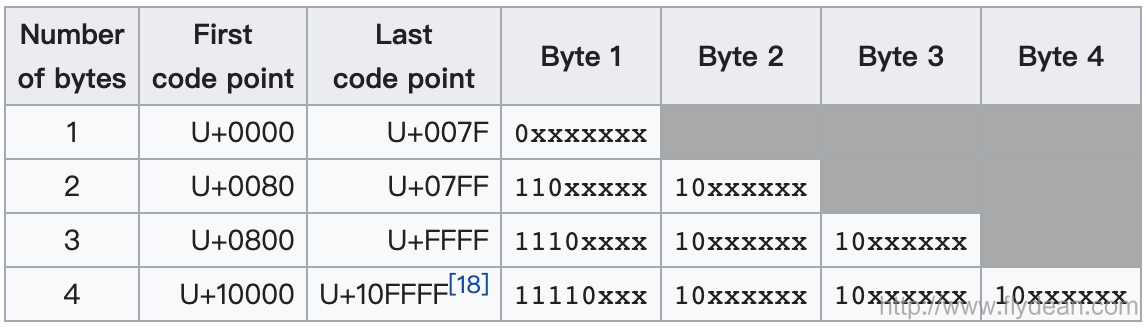
最开始的1个字节可以表示128个ASCII字符,所以UTF-8是和ASCII兼容的。
接下来的1,920个字符需要两个字节进行编码,涵盖了几乎所有拉丁字母字母表的其余部分,以及希腊语,西里尔字母,科普特语,亚美尼亚语,希伯来语,阿拉伯语,叙利亚语,Thaana和N'Ko字母,以及组合变音符号标记。BMP中的其余部分中的字符需要三个字节,其中几乎包含了所有常用字符,包括大多数中文,日文和韩文字符。Unicode中其他平面中的字符需要四个字节,其中包括不太常见的CJK字符,各种历史脚本,数学符号和表情符号(象形符号)。
下面是一个具体的UTF-8编码的例子:

UTF-16
UTF-16也是一种变长的编码方式,UTF-16使用的是1个到2个16bits来表示相应的字符。
UTF-16主要在Microsoft Windows, Java 和 JavaScript/ECMAScript内部使用。
不过UTF-16在web上的使用率并不高。
接下来,我们看一下UTF-16到底是怎么进行编码的。
首先:U+0000 to U+D7FF 和 U+E000 to U+FFFF,这个范围的字符,直接是用1个16bits来表示的,非常的直观。
接着是:U+010000 to U+10FFFF
这个范围的字符,首先减去0x10000,变成20bits表示的0x00000–0xFFFFF。
然后高10bits位的0x000–0x3FF加上0xD800,变成了0xD800–0xDBFF,使用1个16bits来表示。
低10bits的0x000–0x3FF加上0xDC00,变成了0xDC00–0xDFFF,使用1个16bits来表示。
U' = yyyyyyyyyyxxxxxxxxxx // U - 0x10000 W1 = 110110yyyyyyyyyy // 0xD800 + yyyyyyyyyy W2 = 110111xxxxxxxxxx // 0xDC00 + xxxxxxxxxx这也是为什么在Unicode中0xD800–0xDFFF是UTF-16保留字符的原因。
下面是一个UTF-16编码的例子:

UTF-32
UTF-32是固定长度的编码,每一个字符都需要使用1个32bits来表示。
因为是32bits,所以UTF-32可以直接用来表示Unicode字符,缺点就是UTF-32占用的空间太大,所以一般来说很少有系统使用UTF-32.
Null-terminated string 和变种UTF-8
在C语言中,一个string是以null character ('0')NUL结束的。
所以在这种字符中,0x00是不能存储在String中间的。那么如果我们真的想要存储0x00该怎么办呢?
我们可以使用变种UTF-8编码。
在变种UTF-8中,null character (U+0000) 是使用两个字节的:11000000 10000000 来表示的。
所以变种UTF-8可以表示所有的Unicode字符,包括null character U+0000。
通常来说,在java中,InputStreamReader 和 OutputStreamWriter 默认使用的是标准的UTF-8编码,但是在对象序列化和DataInput,DataOutput,JNI和class文件中的字符串常量都是使用的变种UTF-8来表示的。
本文已收录于 http://www.flydean.com/java-string-encodings/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

xDB Replication Server - PostgreSQL, Oracle, SQL Server, PPAS 全量、增量(re...
背景 PostgreSQL凭借友好的开源许可(类BSD开源许可),商业、创新两大价值,以及四大能力(企业级特性,兼容Oracle,TPAP混合负载能力,多模特性),在企业级开源数据库市场份额节节攀升,并蝉联2017,2018全球权威数据库评测机构db-engine的年度数据库冠军。 《中国 PostgreSQL 生态构建思考 - 安全合规、自主可控、去O战略》 如果说兼容Oracle是企业级市场的敲门砖,那么跨Oracle, PostgreSQL 的异构数据库迁移、同步能力就是连接新旧世界的桥梁。如何将Oracle的数据库以及应用平滑,有据可循的迁移到PostgreSQL,可参考阿里云ADAM产品,增量的同步到PostgreSQL可使用xDB replication server。 ADAM xDB replicatoin server 《从人类河流文明 洞察 数据流动的重要性》 数据同步技术是数据流动的重要环节。在很多场景有非常重要的作用: 1、线上业务系统上有实时分析查询,担心影响线上数据库。使用同步技术,实时将数据同步到BI库,减少在线业务数据库的负载。 2、跨版本,跨硬件平台升...
- 下一篇
八种经典排序算法总结,妈妈再也不用担心我不会了
思维导图 文章已收录Github精选,欢迎Star:https://github.com/yehongzhi/learningSummary 前言 算法和数据结构是一个程序员的内功,所以经常在一些笔试中都会要求手写一些简单的排序算法,以此考验面试者的编程水平。下面我就简单介绍八种常见的排序算法,一起学习一下。 一、冒泡排序 思路: 比较相邻的元素。如果第一个比第二个大,就交换它们两个; 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素就是最大的数; 排除最大的数,接着下一轮继续相同的操作,确定第二大的数... 重复步骤1-3,直到排序完成。 动画演示: 实现代码: /** * @author Ye Hongzhi 公众号:java技术爱好者 * @name BubbleSort * @date 2020-09-05 21:38 **/ public class BubbleSort extends BaseSort { public static void main(String[] args) { BubbleSort sort = new BubbleS...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- Red5直播服务器,属于Java语言的直播服务器
- Docker安装Oracle12C,快速搭建Oracle学习环境
- SpringBoot2整合MyBatis,连接MySql数据库做增删改查操作
- Windows10,CentOS7,CentOS8安装MongoDB4.0.16
- CentOS7编译安装Cmake3.16.3,解决mysql等软件编译问题
- SpringBoot2更换Tomcat为Jetty,小型站点的福音
- CentOS7安装Docker,走上虚拟化容器引擎之路
- CentOS6,7,8上安装Nginx,支持https2.0的开启
- Windows10,CentOS7,CentOS8安装Nodejs环境
- CentOS7编译安装Gcc9.2.0,解决mysql等软件编译问题
 微信收款码
微信收款码 支付宝收款码
支付宝收款码