任何深度学习都是从数据开始的,这是关键点。没有数据,就无法训练模型,也无法评估模型质量,更无法做出预测,因此,数据源非常重要。在做研究、构建新的神经网络架构、以及做实验时,会习惯于使用最简单的本地数据源,通常是不同格式的文件,这种方法确实非常有效。但有时需要更加接近于生产环境,那么简化和加速生产数据的反馈,以及能够处理大数据就变得非常重要,这时就需要Apache Ignite大展身手了。
Apache Ignite是以内存为中心的分布式数据库、缓存,也是事务性、分析性和流式负载的处理平台,可以实现PB级的内存级速度。借助Ignite和TensorFlow之间的现有集成,可以将Ignite用作神经网络训练和推理的数据源,也可以将其用作分布式训练的检查点存储和集群管理器。
分布式内存数据源
作为以内存为中心的分布式数据库,Ignite可以提供快速数据访问,摆脱硬盘的限制,在分布式集群中存储和处理需要的所有数据,可以通过使用Ignite Dataset来利用Ignite的这些优势。
注意Ignite不只是数据库或数据仓库与TensorFlow之间ETL管道中的一个步骤,它还是一个HTAP(混合事务/分析处理)系统。通过选择Ignite和TensorFlow,可以获得一个能够处理事务和分析的单一系统,同时还可以获得将操作型和历史型数据用于神经网络训练和推理的能力。
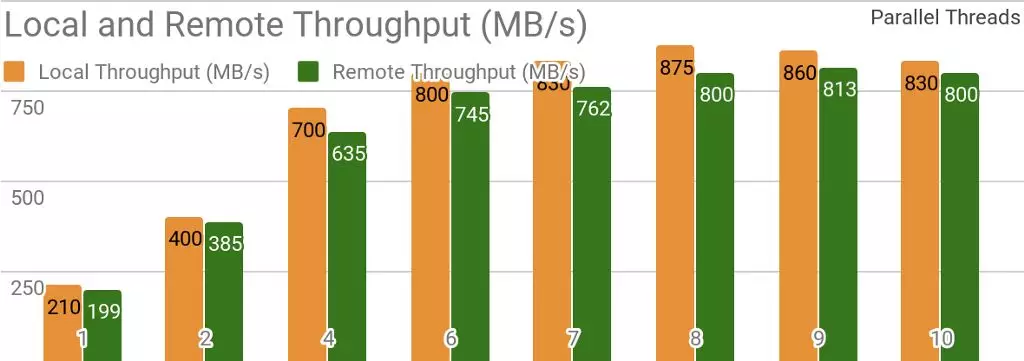
下面的测试结果表明,Ignite非常适合用于单节点数据存储场景。如果存储和客户端位于同一节点,则通过使用Ignite,可以实现每秒超过850MB的吞吐量,如果存储位于与客户端相关的远程节点,则吞吐量约为每秒800MB。
![]()
当存在一个本地Ignite节点时Ignite Dataset的吞吐量。执行该基准测试时使用的是2个Xeon E5–2609 v4 1.7GHz处理器,配备 16GB内存和每秒10Gb的网络(1MB的行和20MB 的页面大小)
另一个测试显示Ignite Dataset如何与分布式Ignite集群协作。这是Ignite作为HTAP系统的默认用例,它能够在每秒10Gb的网络集群上为单个客户端实现每秒超过1GB的读取吞吐量。
![]()
分布式Ignite集群具备不同数量的节点(从1到9)时Ignite Dataset的吞吐量。执行该测试时使用的是2个Xeon E5–2609 v4 1.7GHz处理器,配备16GB内存和每秒10Gb的网络(1MB的行和20MB的页面大小)
测试后的用例如下:Ignite缓存(以及第一组测试中数量不同的分区和第二组测试中的2048个分区)由10000个大小为1MB的行填充,然后TensorFlow客户端使用Ignite Dataset读取所有数据。所有节点均为2个Xeon E5–2609 v4 1.7GHz处理器,配备16GB内存和每秒10Gb的网络连接,每个节点都使用默认配置运行Ignite。
可以很轻松地将Ignite同时用作支持SQL接口的传统数据库和TensorFlow数据源。
apache-ignite/bin/ignite.sh
apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR);
INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY');
INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY');
INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE")
for element in dataset:
print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}}
{'key': 2, 'val': {'NAME': b'SOFT KITTY'}}
{'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
结构化对象
使用Ignite可以存储任何类型的对象,这些对象可以具备任何层次结构。Ignite Dataset有处理此类对象的能力。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES")
for element in dataset.take(1):
print(element)
{
'key': 'kitten.png',
'val': {
'metadata': {
'file_name': b'kitten.png',
'label': b'little ball of fur',
width: 800,
height: 600
},
'pixels': [0, 0, 0, 0, ..., 0]
}
}
如果使用Ignite Dataset,则神经网络训练和其它计算所需的转换都可以作为tf.data管道的一部分来完成。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels'])
for element in dataset:
print(element)
[0, 0, 0, 0, ..., 0]
分布式训练
作为机器学习框架,TensorFlow可以为分布式神经网络训练、推理及其它计算提供原生支持。分布式神经网络训练的主要理念是能够在每个数据分区(基于水平分区)上计算损失函数的梯度(例如误差的平方),然后对梯度求和,以得出整个数据集的损失函数梯度。借助这种能力,可以在数据所在的节点上计算梯度,减少梯度,最后更新模型参数。这样就无需在节点间传输数据,从而避免了网络瓶颈。
Ignite在分布式集群中使用水平分区存储数据。在创建Ignite缓存(或基于SQL的表)时,可以指定将要在此对数据进行分区的分区数量。例如,如果一个Ignite集群由100台机器组成,然后创建了一个有1000个分区的缓存,则每台机器将要维护10个数据分区。
Ignite Dataset可以利用分布式神经网络训练(使用TensorFlow)和Ignite分区两者的能力。Ignite Dataset是一个可以在远程工作节点上执行的计算图操作。远程工作节点可以通过为工作节点进程设置相应的环境变量(例如IGNITE_DATASET_HOST、IGNITE_DATASET_PORT或IGNITE_DATASET_PART)来替换Ignite Dataset的参数(例如主机、端口或分区)。使用这种替换方法,可以为每个工作节点分配一个特定分区,以使一个工作节点只处理一个分区,同时可以与单个数据集透明协作。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
dataset = IgniteDataset("IMAGES")
# Compute gradients locally on every worker node.
gradients = []
for i in range(5):
with tf.device("/job:WORKER/task:%d" % i):
device_iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
device_next_obj = device_iterator.get_next()
gradient = compute_gradient(device_next_obj)
gradients.append(gradient)
# Aggregate them on master node.
result_gradient = tf.reduce_sum(gradients)
with tf.Session("grpc://localhost:10000") as sess:
print(sess.run(result_gradient))
借助Ignite,还可以使用TensorFlow的高级Estimator API来进行分布式训练。此功能以所谓的TensorFlow分布式训练的独立客户端模式为基础,Ignite在其中发挥数据源和集群管理器的作用。
检查点存储
除数据库功能外,Ignite还有一个名为IGFS的分布式文件系统。IGFS 可以提供与Hadoop HDFS类似的功能,但仅限于内存。事实上除了自有API外,IGFS还实现了Hadoop的FileSystem API,可以透明地部署到Hadoop或Spark环境中。Ignite上的TensorFlow支持IGFS与TensorFlow集成,该集成基于TensorFlow端的自定义文件系统插件和Ignite端的IGFS原生API,它有许多使用场景,比如:
- 可以将状态检查点保存到IGFS中,以获得可靠性和容错性;
- 训练过程可以通过将事件文件写入
TensorBoard监视的目录来与TensorBoard通信。即使TensorBoard在不同的进程或机器中运行,IGFS也可以正常运行。
TensorFlow在1.13版本中发布了此功能,并将在TensorFlow 2.0中作为tensorflow/io的一部分发布。
SSL连接
通过Ignite,可以使用SSL和认证机制来保护数据传输通道。Ignite Dataset同时支持有认证和无认证的SSL连接,具体信息请参见Ignite的SSL/TLS文档。
import tensorflow as tf
from tensorflow.contrib.ignite import IgniteDataset
tf.enable_eager_execution()
dataset = IgniteDataset(cache_name="IMAGES",
certfile="client.pem",
cert_password="password",
username="ignite",
password="ignite")
Windows支持
Ignite Dataset完全兼容Windows系统,可以在Windows和Linux/MacOS系统上将其用作TensorFlow的一部分。
试用
下面的示例非常有助于入门。
Ignite Dataset
要试用Ignite Dataset,最简单的方法是运行装有Ignite和加载好的MNIST数据的Docker容器,然后使用Ignite Dataset与其交互。可以在Docker Hub:dmitrievanthony/ignite-with-mnist上找到此容器,然后执行如下命令启动容器:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
然后可以按照如下方法进行使用:
![]()
IGFS
TensorFlow的IGFS支持于TensorFlow 1.13中发布,并将在TensorFlow 2.0中作为tensorflow/io的一部分发布。如要通过TensorFlow试用IGFS,最简单的方法是运行一个装有Ignite和IGFS的Docker容器,然后使用TensorFlow的tf.gfile与之交互。可以在Docker Hub:dmitrievanthony/ignite-with-igfs上找到此容器,然后执行如下命令启动容器:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
然后可以按照如下方法进行使用:
import tensorflow as tf
import tensorflow.contrib.ignite.python.ops.igfs_ops
with tf.gfile.Open("igfs:///hello.txt", mode='w') as w:
w.write("Hello, world!")
with tf.gfile.Open("igfs:///hello.txt", mode='r') as r:
print(r.read())
Hello, world!
限制
目前,Ignite Dataset要求缓存中的所有对象都具有相同的结构(同类型对象),并且缓存中至少包含一个检索模式所需的对象。另一个限制与结构化对象有关,Ignite Dataset不支持UUID、Map和可能是对象结构组成部分的对象数组。
即将发布的TensorFlow 2.0
TensorFlow 2.0中会将此功能拆分到tensorflow/io模块,这样会更灵活。这些示例将略有改动,后续的文档和示例都会更新。