需求 在使用locust压测的时候,如果使用web则可以查看到QPS压测过程的曲线图。而如果使用no web 模式启动,则只有一些打印的日志可以查看。
那么能否将no web 模式启动的locust执行过程日志转化为曲线图表呢?
如果需要将日志转化为曲线图表,那么则以下步骤:1、将locust执行任务日志序列化,方便程序读取 2、需要定时刷新获取执行日志文件,将日志信息写入数据库 3、读取数据库数据,将其进行图表化呈现。
并且还要求这个日志采集处理要足够轻量级、资源消耗小 ,只有在执行locust的时候才启动即可。所以,我也放弃了filebeat + logstash + Elasticsearch 或者 kafka 、redis等大型采集日志的方案。
自己定制化写一个即可。
将locust执行任务日志序列化 方式一,直接在locust源码中挂上钩子,将日志格式化写入文件 对于locust执行任务的日志序列化我尝试过直接在locust源码中挂上钩子,然后将日志进行格式化之后,再写入一个文件中。功能上是可以实现的,但是压测性能上就会大打折扣,由于locust在压测过程需要对每个压测请求都进行格式化以及写入文件,这样就很影响压测机的并发效率。
所以这种方式已经被我抛弃。
有兴趣可以参考:Matplotlib可视化查看Locust测试结果(一)
方式二,过滤locust使用no web模式下打印出来的日志 在经过多测压测测试之后,我决定直接使用locust执行过程打印的日志来生成图表。
1、首先将locust执行过程的日志写入文件中 2、通过读取执行文件的日志信息,再将其转化存储到influxdb数据库 3、最后根据influxdb数据库的数据,展示图表
在这个过程,对于locust自身的压测过程,我并没有嵌入代码去影响执行效率。而是将locust执行过程自动打印出来的信息进行二次处理而已。
这样做的好处就是不会对locust压测造成较大的性能损耗,因为大概是5秒打印一次执行日志,相信这个损耗是比较低的了。
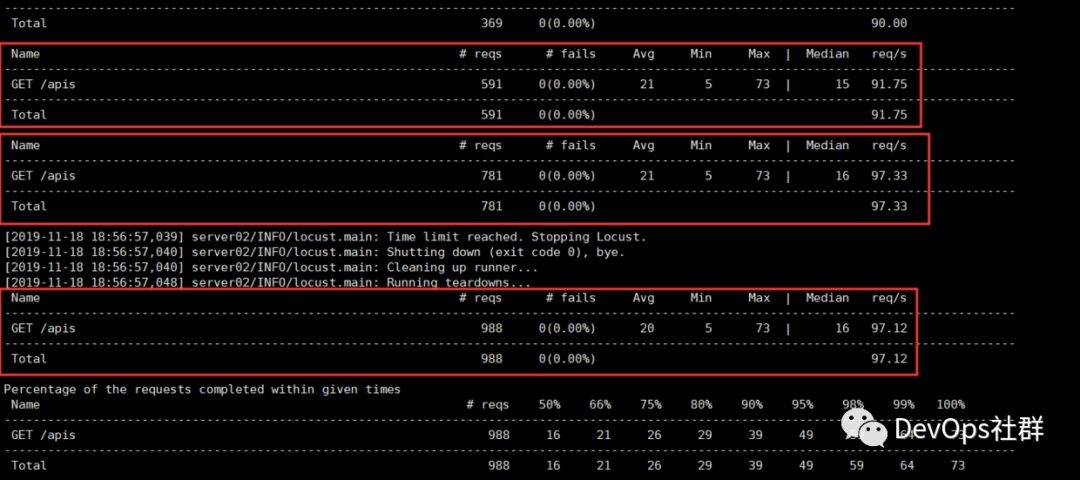
原生的locust执行日志:
可以从图中看到,在执行locust脚本使用no web 模式的时候,执行的日志默认是INFO级别的,一般我们都是这样去使用。此时,INFO的日志信息和locust压测执行结果混合在一起打印,这就让人很不开心了。所以必须将其分开。
首先确定我只需要的信息,如下:
如果压测的接口有多个,那么就会有对应的多条信息。示例如下:
Name # reqs # fails Avg Min Max | Median req/s确定好了需要的数据日志信息之后,下面第一步就是可以将INFO信息和执行结果信息拆分写入不同的日志文件中。
拆分日志中的INFO信息与执行结果信息
--logfile=locust.log --loglevel=INFO 将
INFO信息写到
locust.log日志中
1>run.log 2>&1 将压测执行的结果信息写到
run.log日志中
命令执行如下:locust -f locustfile.py --no-web -c 100 -r 50 --run-time=30 --expect-slaves=2 --csv=result --host='http://127.0.0.1:8000' --logfile=locust.log --loglevel=INFO 1>run.log 2>&1
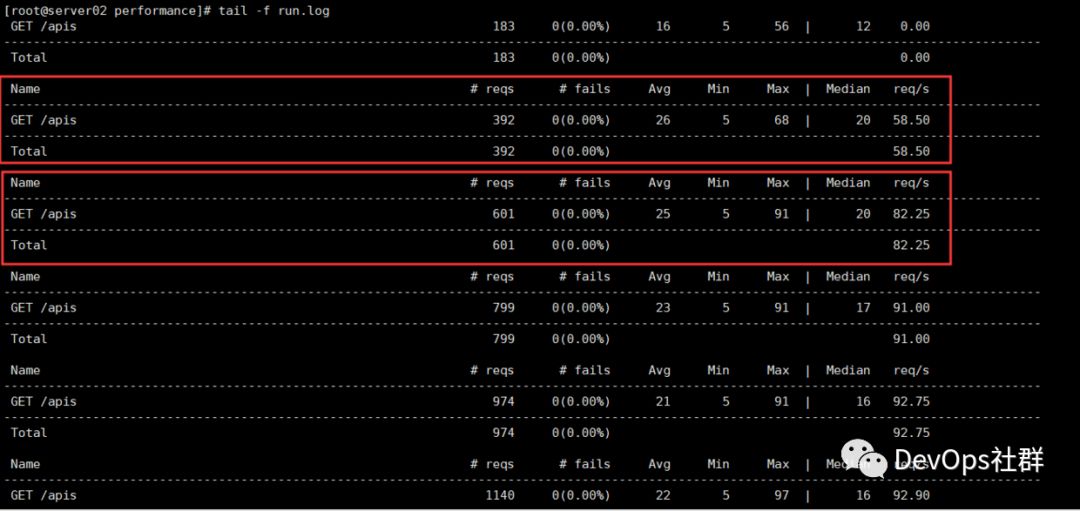
查看执行压测结果日志run.log如下:
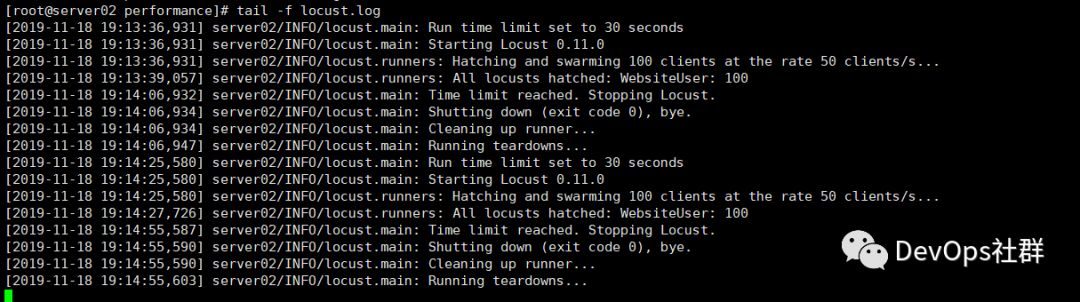
查看执行INFO信息日志locust.log如下:
可以看到INFO信息和locust执行的压测结果已经分开日志文件存储好了。那么下面就需要想办法将执行压测结果的数据进行序列化读取,存储到influxdb中。
使用python实时读取run.log日志信息 在这里可以写一个简单的功能,如下:
在开启执行locust脚本的同时,也启动这个python脚本或者一直长时间执行。
在python脚本执行的过程期间,需要执行两个动作即可:读取日志信息,然后写入influxdb
下面直接将实现好的python代码show出来,如下:
import subprocess此时执行的参数已经可以实时写入influxdb中了,如下:
> precision rfc3339那么下一步只要在grafana展示图表就可以了。
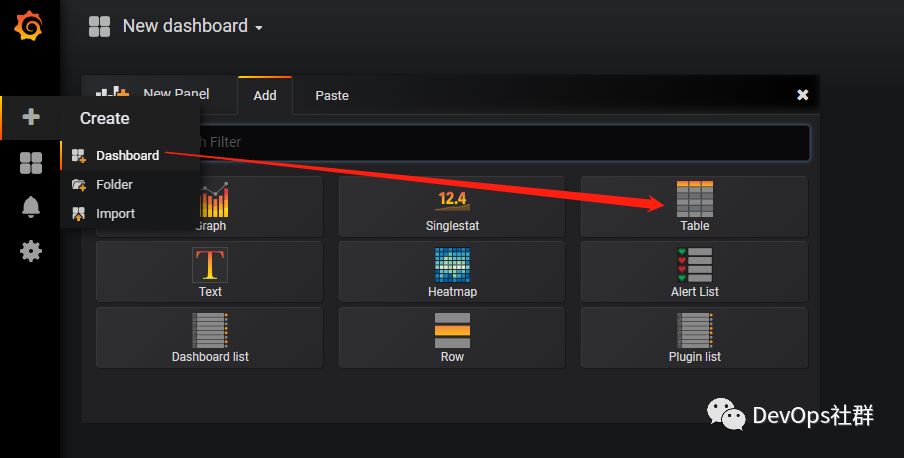
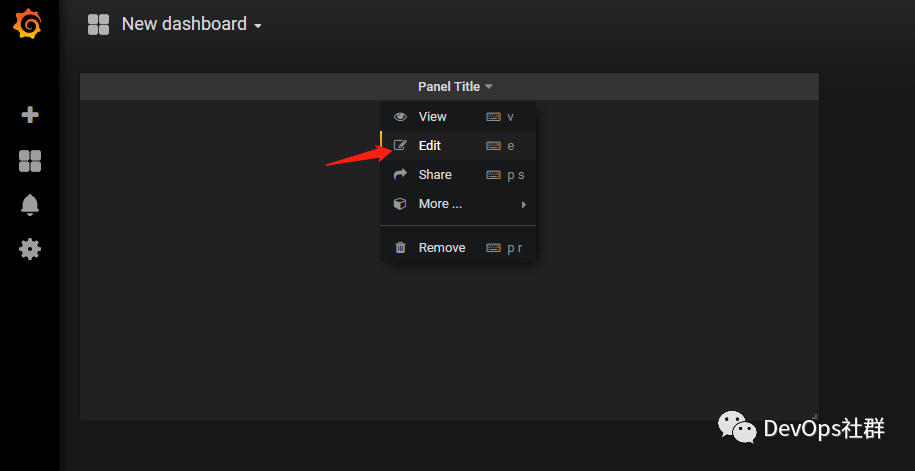
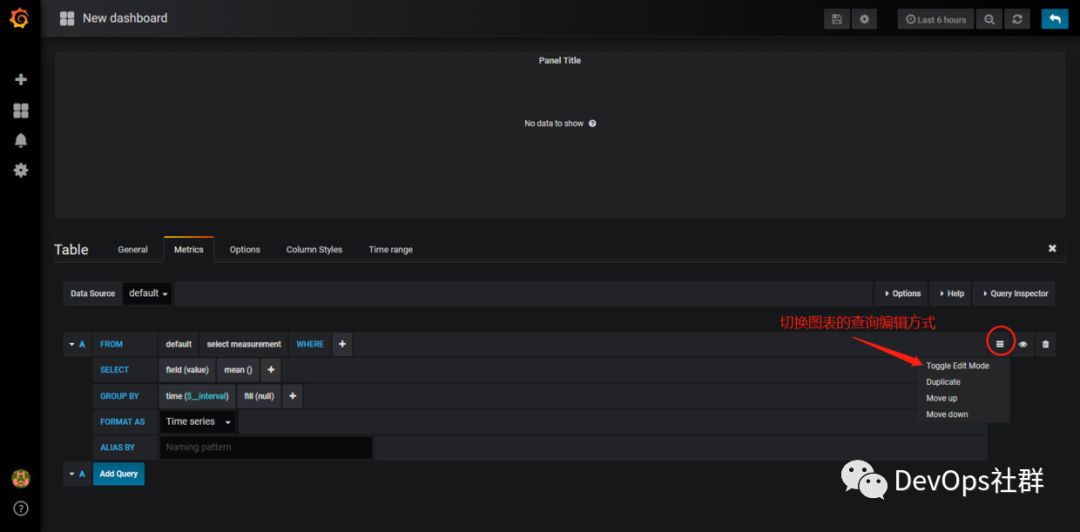
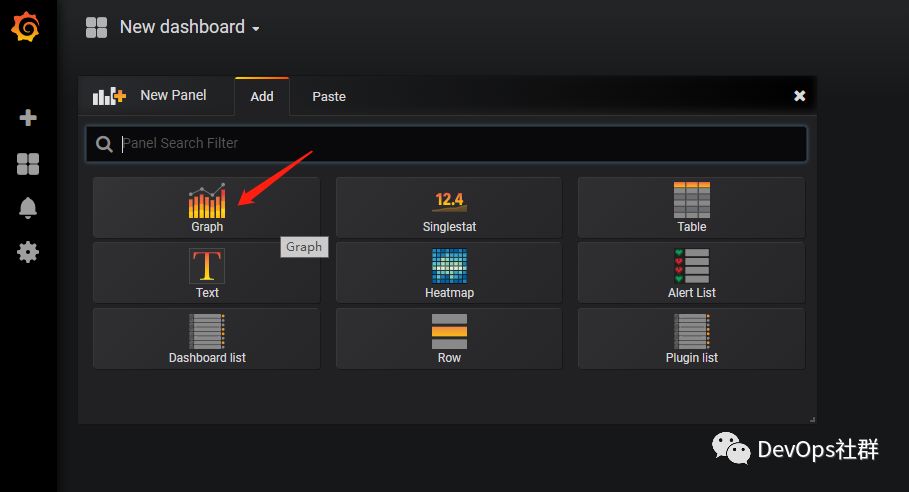
Grafana设置图表 创建table图表 先创建一个table表格,如下:
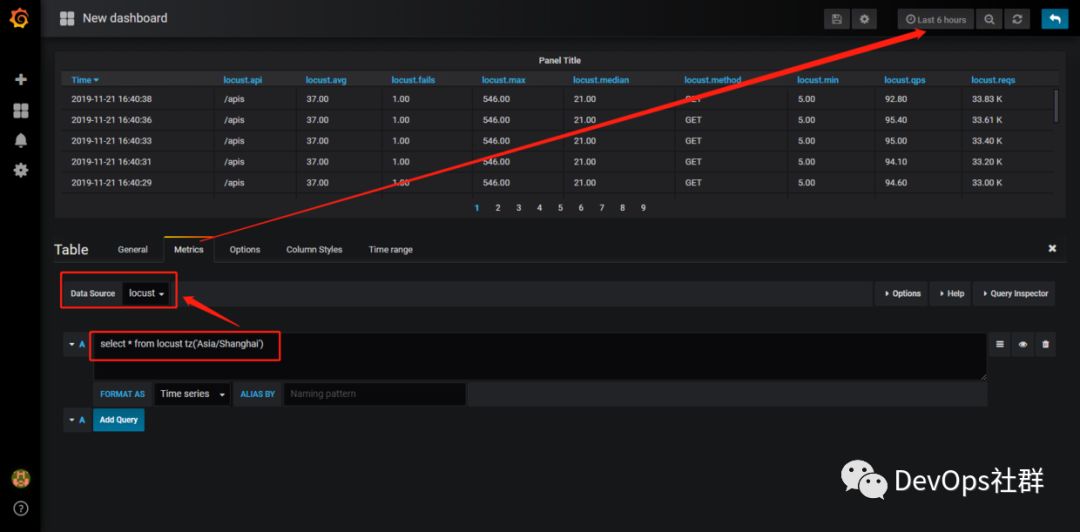
将查询语句直接写入查询框中,然后选择数据库(我前面已经设置好,这里就不展示了),最后设置查询的时间,就可以看到数据展示了。
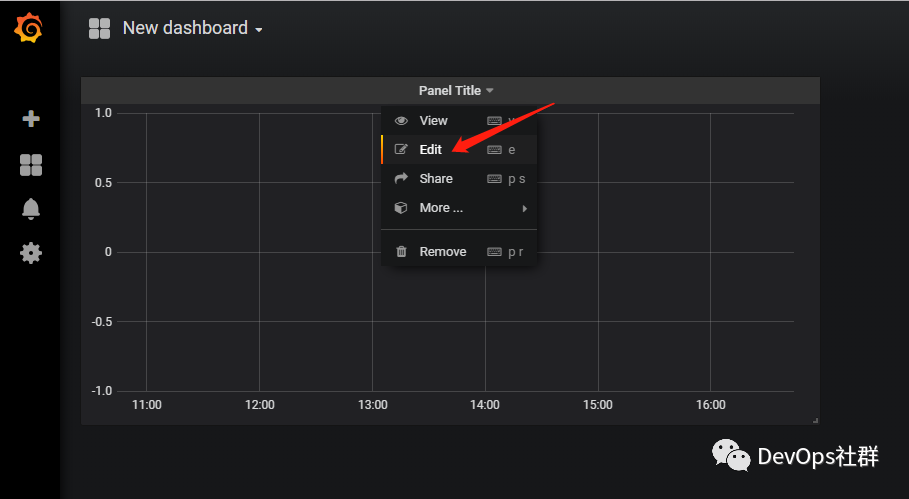
最后修改标题,保存起来就可以了,下面再来做一个折线图。
创建折线图
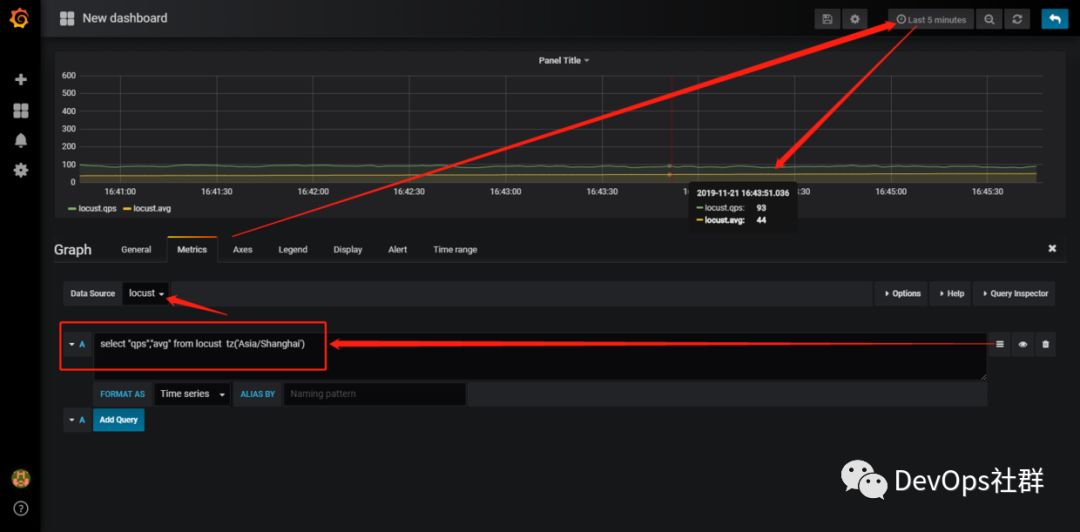
同样的操作,如何需要在折线图上显示什么曲线,那就增加字段即可。在复制到grafana之前,最好在influx查询执行一下,看看能否执行成功。
我的测试执行如下:
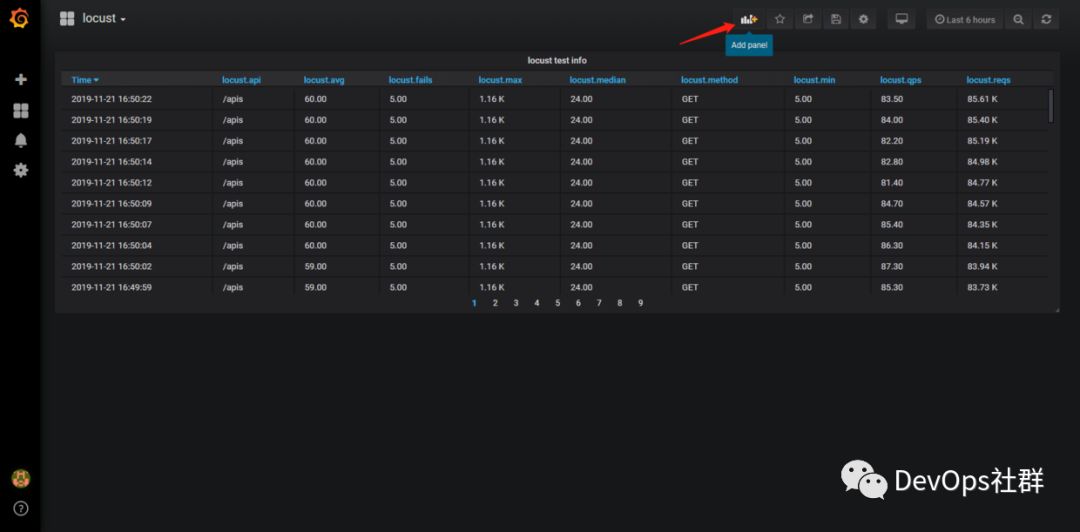
> select "qps","avg" from locust limit 5 tz('Asia/Shanghai')到这里就已经实现locust执行日志的实时查看了。
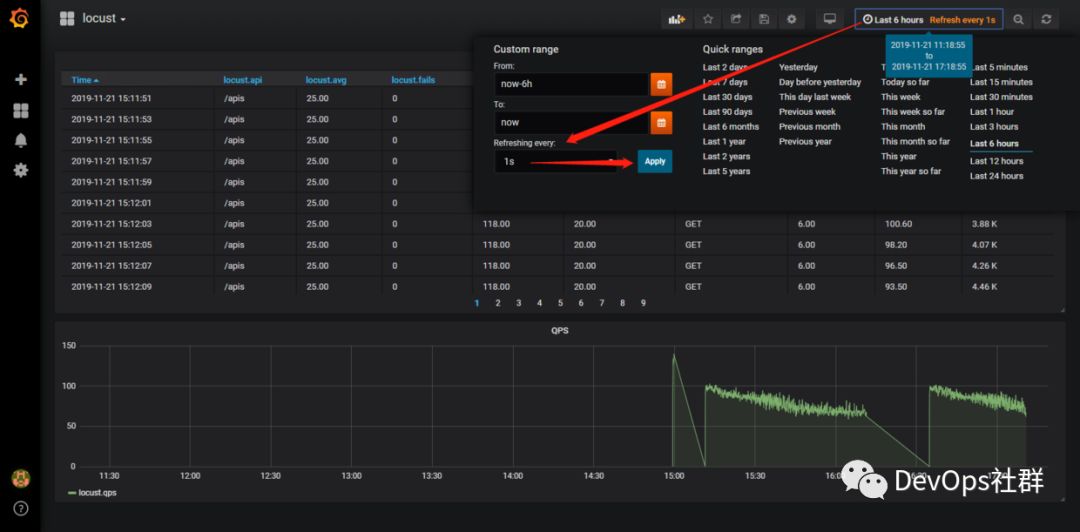
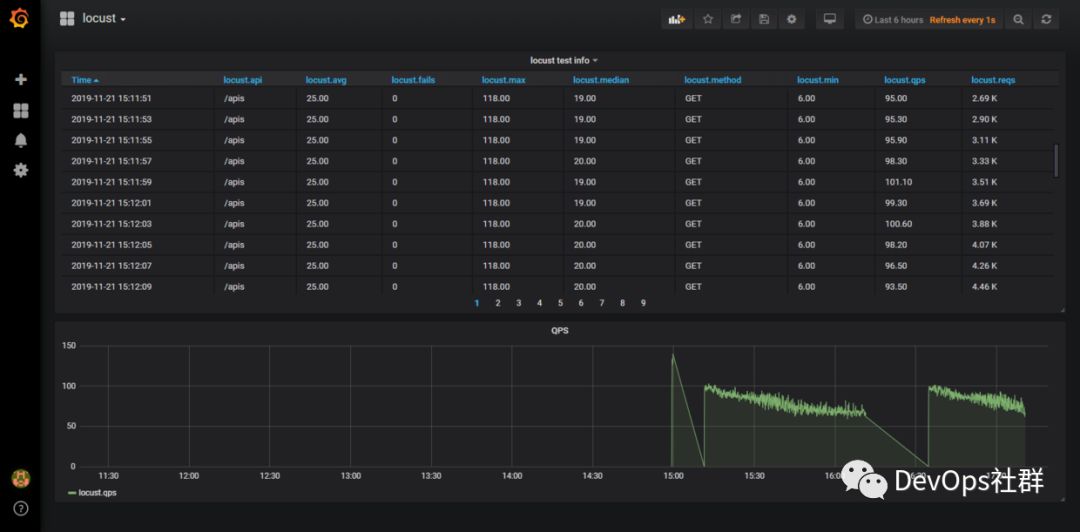
效果图 最后设置一下页面自动刷新,如下:
另外,如果有不清楚influxdb和grafana安装和基本操作的,可以看看我之前写关于这两个工具的篇章:Grafana系列InfluxDB系列