在阿里巴巴的java开发手册有这么一条强制规定:超过三个表禁止join,需要join的字段,数据类型保持绝对一致,多表关联查询时,要保证被关联的字段需要有索引。
为什么尽量避免使用join?如果使用join,我们应该怎么用呢?接下来我们就一起聊一聊关于join的几种算法。
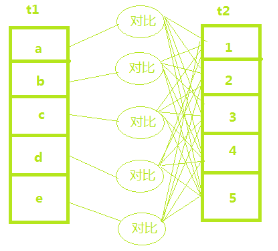
Simple Nested-Loop Join算法是指读取驱动表t1中的每行数据,将每行数据传递到被驱动表t2上,取出被驱动表t2中满足条件的行,和t1组成结果集。
在这个算法中,需要对t1进行全表扫描,假设t1表1000行数据,那么需要对t2表进行1000次全表扫描,假设t2表也是1000行数据,那么就需要扫描1000 X 1000=1000000行。
示例图如下:当t1表5行数据,t2表5行数据时,需要扫描25行数据。
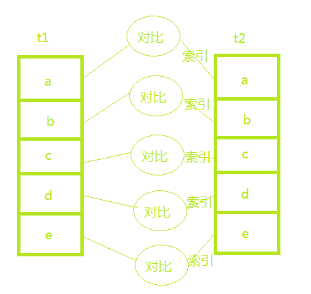
index nested-loop join算法的优化思路是通过驱动表的匹配条件,直接与被驱动表的索引进行匹配,减少了被驱动表的扫描次数。
该算法同样要对驱动表t1进行全表扫描,但是我们在拿着t1表的数据去被驱动表t2进行匹配时可以利用t2表的索引,如果t1表中1000行数据,t2表中1000行数据,那么一共就需要扫描1000+1000=2000行数据。这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以称之为“Index Nested-Loop Join”,简称 NLJ。
示例如下:当t1表有5行数据,t2表有5行数据时,一共需要扫描5+5=10行数据。
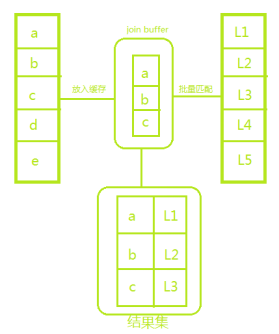
Block Nested-Loop join,基于块的嵌套循环,简称BNL算法,其优化思路主要是减少被驱动表的循坏次数,它会将驱动表的数据缓存起来,把参与查询的列缓存到join buffer里,然后拿join buffer里的数据批量与内层表的数据在join buffer中进行匹配,满足join条件的,作为结果集的一部分返回。
可以看到该算法对两个表都进行了全表扫描,因此扫描的行数是两个表的行数之和。这种场景下,虽然在扫描行数上和NLJ算法一样,但是由于BNL算法是在内存中进行判断,速度上会快很多。
join buffer的大小是由参数join_buffer_size设定,默认256k。如果一次放不下驱动表的所有数据,会分段放,这种情况下会导致被驱动表扫描多次。如果被驱动表是冷数据表,并且多次扫描读取被驱动表间隔超过1S的话,就会将他放入LRU链表的young区域,导致业务数据无法进入热数据区,减少了bufferpool的命中率,这又是另外一个课题了,暂不过多展开。我们可以通过调大join_buffer_size来提高缓存的数据量,减少对被驱动表的扫描次数。
启用BNL算法需要在optimizer_switch参数中设置block_nested_loop=on。
BNL算法提升了join的性能,但是它在通过辅助索引连接后需要回表,就会消耗大量的随机I/O,我们知道随机IO对MySQL的影响是非常大的。因此MySQL5.6引入了Batched Key Access(BKA,批量键访问联接)算法。
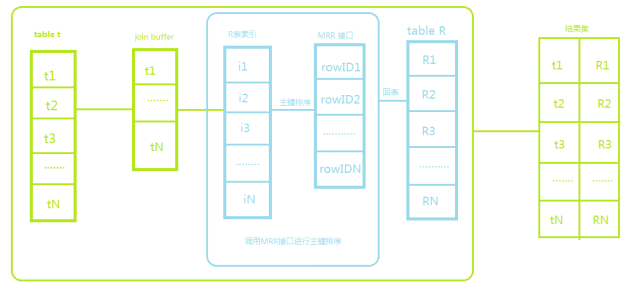
再说BKA算法时不得不提的就是MySQL的Multi-Range Read 优化,MRR的目的主要是减少磁盘的随机访问。我们都知道,Innodb索引采用的是B+tree的数据结构,数据保存在主键索引中,并且是按照主键递增的顺序插入的,但是二级索引的排列顺序和主键的排列顺序一般是不一样的,它保存的主键值也并非按照主键顺序排列,在回表时就会出现随机访问主键索引的情况。所以如果可以按照主键递增顺序查询的话,对磁盘的读比较接近顺序读,这样就能够提升读性能。
MRR优化的思路就是在进行范围查询时,在得到主键值之后,先按照主键的顺序进行排序,然后拿着排好序的主键ID再去主键索引进行查询,这样就能体现出顺序性的优势了。因为是多值查询,所以一般用于range、ref类型的查询。
再说会BKA算法,当被驱动表上有索引可以利用时,那么就在行提交给被 join 的表之前,先对两个表的对应列的索引字段进行join,得到主键值后,按照主键排好序后,利用 MRR 技术,批量访问表取数据,减少了随机 IO。但是如果被 join 的表没用索引的话,那就只能使用BNL算法了。
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
MySQL在8.0版本已经实现了hash join,这里暂不做介绍。
-
-
-
-
适当增大join_buffer_size的值,缓存的数据越多,就越能减少被驱动表扫描的次数。
-
-