点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
创建用于室内和室外火灾检测的定制InceptionV3和CNN架构。
![]()
嵌入式处理技术的最新进展已使基于视觉的系统可以在监视过程中使用卷积神经网络检测火灾。在本文中,两个定制的CNN模型已经实现,它们拥有用于监视视频的高成本效益的火灾检测CNN架构。第一个模型是受AlexNet架构启发定制的基本CNN架构。我们将实现和查看其输出和限制,并创建一个定制的InceptionV3模型。为了平衡效率和准确性,考虑到目标问题和火灾数据的性质对模型进行了微调。我们将使用三个不同的数据集来训练我们的模型。
我们将使用TensorFlow API Keras构建模型。首先,我们创建用于标记数据的ImageDataGenerator。[1]和[2]数据集在这里用于训练。最后,我们将提供980张图像用于训练和239张图像用于验证。我们也将使用数据增强。
import tensorflow as tfimport keras_preprocessingfrom keras_preprocessing import imagefrom keras_preprocessing.image import ImageDataGeneratorTRAINING_DIR = "Train"training_datagen = ImageDataGenerator(rescale = 1./255, horizontal_flip=True, rotation_range=30, height_shift_range=0.2, fill_mode='nearest')VALIDATION_DIR = "Validation"validation_datagen = ImageDataGenerator(rescale = 1./255)train_generator = training_datagen.flow_from_directory(TRAINING_DIR, target_size=(224,224), class_mode='categorical', batch_size = 64)validation_generator = validation_datagen.flow_from_directory( VALIDATION_DIR, target_size=(224,224), class_mode='categorical', batch_size= 16)
在上面的代码中应用了3种数据增强技术,它们分别是水平翻转,旋转和高度移位。
现在,我们将创建我们的CNN模型。该模型包含三对Conv2D-MaxPooling2D层,然后是3层密集层。为了克服过度拟合的问题,我们还将添加dropout层。最后一层是softmax层,它将为我们提供火灾和非火灾两类的概率分布。通过将类数更改为1,还可以在最后一层使用‘Sigmoid’激活函数。
from tensorflow.keras.optimizers import Adammodel = tf.keras.models.Sequential([tf.keras.layers.Conv2D(96, (11,11), strides=(4,4), activation='relu', input_shape=(224, 224, 3)), tf.keras.layers.MaxPooling2D(pool_size = (3,3), strides=(2,2)),tf.keras.layers.Conv2D(256, (5,5), activation='relu'),tf.keras.layers.MaxPooling2D(pool_size = (3,3), strides=(2,2)),tf.keras.layers.Conv2D(384, (5,5), activation='relu'),tf.keras.layers.MaxPooling2D(pool_size = (3,3), strides=(2,2)),tf.keras.layers.Flatten(),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(2048, activation='relu'),tf.keras.layers.Dropout(0.25),tf.keras.layers.Dense(1024, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(2, activation='softmax')])model.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.0001),metrics=['acc'])history = model.fit(train_generator,steps_per_epoch = 15,epochs = 50,validation_data = validation_generator,validation_steps = 15)
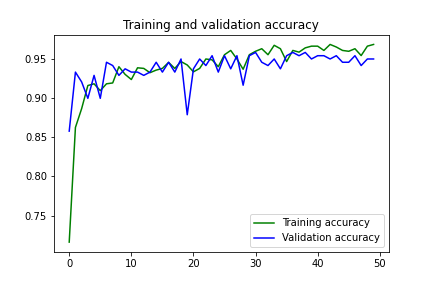
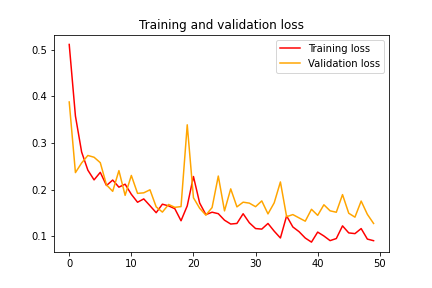
我们将使用Adam作为学习率为0.0001的优化器。经过50个时期的训练,我们得到了96.83的训练精度和94.98的验证精度。训练损失和验证损失分别为0.09和0.13。
让我们测试模型中的所有图像,看看它的猜测是否正确。为了进行测试,我们选择了3张图像,其中包括有火的图像,没有火的图像以及包含火样颜色和阴影的照片。
我们最终得到上面创建的模型在对图像进行分类时犯了一个错误。
该模型52%的把握确定图像中有火焰。
这是因为已进行训练的数据集中几乎没有图像可以说明室内火灾的模型。
所以该模型仅知道室外火灾情况,而当给出一张室内火样的阴影图像时会出现错误。
另一个原因是我们的模型不具备可以学习火的复杂特征。
接下来,我们将使用标准的InceptionV3模型并对其进行自定义。复杂模型能够从图像中学习复杂特征。
这次我们将使用不同的数据集[3],其中包含室外和室内火灾图像。
我们已经在该数据集中训练了我们之前的CNN模型,结果表明它是过拟合的,因为它无法处理这个相对较大的数据集和从图像中学习复杂的特征。
我们开始为自定义的InceptionV3创建ImageDataGenerator。数据集包含3个类,但对于本文,我们将仅使用2个类。它包含用于训练的1800张图像和用于验证的200张图像。另外,我添加了8张客厅图像,以在数据集中添加一些噪点。
import tensorflow as tfimport keras_preprocessingfrom keras_preprocessing import imagefrom keras_preprocessing.image import ImageDataGeneratorTRAINING_DIR = "Train"training_datagen = ImageDataGenerator(rescale=1./255,zoom_range=0.15,horizontal_flip=True,fill_mode='nearest')VALIDATION_DIR = "/content/FIRE-SMOKE-DATASET/Test"validation_datagen = ImageDataGenerator(rescale = 1./255)train_generator = training_datagen.flow_from_directory(TRAINING_DIR,target_size=(224,224),shuffle = True,class_mode='categorical',batch_size = 128)validation_generator = validation_datagen.flow_from_directory(VALIDATION_DIR,target_size=(224,224),class_mode='categorical',shuffle = True,batch_size= 14)
为了使训练更加准确,我们可以使用数据增强技术。在上面的代码中应用了2种数据增强技术-水平翻转和缩放。
让我们从Keras API导入InceptionV3模型。我们将在InceptionV3模型的顶部添加图层,如下所示。我们将添加一个全局空间平均池化层,然后是2个密集层和2个dropout层,以确保我们的模型不会过拟合。最后,我们将为2个类别添加一个softmax激活的密集层。
接下来,我们将首先仅训练我们添加并随机初始化的图层。我们将在这里使用RMSprop作为优化器。
from tensorflow.keras.applications.inception_v3 import InceptionV3from tensorflow.keras.preprocessing import imagefrom tensorflow.keras.models import Modelfrom tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Input, Dropoutinput_tensor = Input(shape=(224, 224, 3))base_model = InceptionV3(input_tensor=input_tensor, weights='imagenet', include_top=False)x = base_model.outputx = GlobalAveragePooling2D()(x)x = Dense(2048, activation='relu')(x)x = Dropout(0.25)(x)x = Dense(1024, activation='relu')(x)x = Dropout(0.2)(x)predictions = Dense(2, activation='softmax')(x)model = Model(inputs=base_model.input, outputs=predictions)for layer in base_model.layers: layer.trainable = Falsemodel.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])history = model.fit(train_generator,steps_per_epoch = 14,epochs = 20,validation_data = validation_generator,validation_steps = 14)
在训练了顶层20个周期之后,我们将冻结模型的前249层,并训练其余的层(即顶层2个初始块)。在这里,我们将使用SGD作为优化器,学习率为0.0001。
layer.trainable = Falsefor layer in model.layers[249:]: layer.trainable = Truemodel.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy', metrics=['acc'])history = model.fit(train_generator,steps_per_epoch = 14,epochs = 10,validation_data = validation_generator,validation_steps = 14)
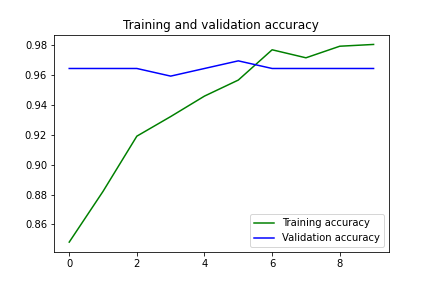
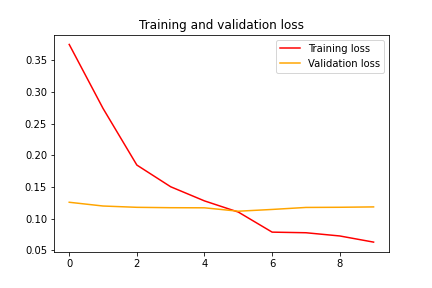
经过10个周期的训练,我们获得了98.04的训练准确度和96.43的验证准确度。训练损失和验证损失分别为0.063和0.118。
我们用相同的图像测试我们的模型,看看是否它可以正确猜出。
这次我们的模型可以使所有三个预测正确。
96%的把握可以确定图像中没有任何火。
我用于测试的其他两个图像如下:
现在,我们的模型已准备好在实际场景中进行测试。
以下是使用OpenCV访问我们的网络摄像头并预测每帧图像中是否包含火的示例代码。
如果框架中包含火焰,我们希望将该框架的颜色更改为B&W。
import cv2import numpy as npfrom PIL import Imageimport tensorflow as tffrom keras.preprocessing import imagemodel = tf.keras.models.load_model('InceptionV3.h5')video = cv2.VideoCapture(0)while True: _, frame = video.read() im = Image.fromarray(frame, 'RGB') im = im.resize((224,224)) img_array = image.img_to_array(im) img_array = np.expand_dims(img_array, axis=0) / 255 probabilities = model.predict(img_array)[0] prediction = np.argmax(probabilities) if prediction == 0: frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) print(probabilities[prediction])cv2.imshow("Capturing", frame) key=cv2.waitKey(1) if key == ord('q'): breakvideo.release()cv2.destroyAllWindows()
这个项目的Github链接在这里:https://github.com/DeepQuestAI/Fire-Smoke-Dataset。可以从那里找到数据集和上面的所有代码。
使用智能相机可以识别各种可疑事件,例如碰撞,医疗紧急情况和火灾。其中,火灾是最危险的异常事件,因为在早期阶段无法控制火灾会导致巨大的灾难,从而造成人员,生态和经济损失。受CNN巨大潜力的启发,我们可以在早期阶段从图像或视频中检测到火灾。本文展示了两种用于火灾探测的自定义模型。考虑到CNN模型的火灾探测准确性,它可以帮助灾难管理团队按时管理火灾,从而避免巨额损失。
数据集1:https://www.kaggle.com/atulyakumar98/test-dataset
数据集2:https://www.kaggle.com/phylake1337/fire-dataset
数据集3:https://github.com/DeepQuestAI/Fire-Smoke-Dataset
如果本文对小伙伴有帮助,希望可以在文末来个“一键三连”。
![]()
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
![]()
![]()