【摘要】有研究表明,全球数据总量每两年翻一番,各企业都在处理和存储这些海量数据。这些数据主要由结构化数据、非结构化数据等类型数据构成。企业对数据了解得越透彻,就能够越准确地判断数据的价值及风险。
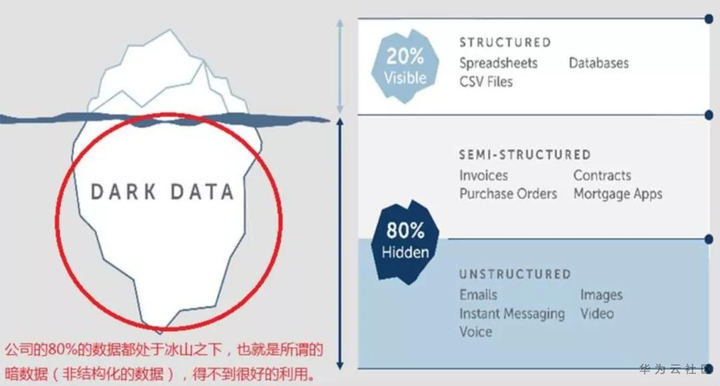
结构化的数据:即有固定格式和有限长度的数据。例如填的表格就是结构化的数据,国籍:中华人民共和国,民族:汉,性别:男,这都叫结构化数据。对于ICT领域来说,就是以固定的格式存储到数据库里的数据(Oracle/MySQL/…)。
半结构化数据:是一些 XML 或者 HTML 的格式的,当根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理。
非结构化的数据:就是不定长、无固定格式的数据,例如网页,邮件,有时候非常长;有时候非常短,几句话就没了;例如Word文档、语音,视频、图片都是非结构化的数据。现在非结构化的数据居多。
为了描述方便,我们把半结构化数据和非结构化数据,合二为一统称为“暗数据”,当然这个词不是我起的,是AA公司起的名字。AA(Automation Anywhere)公司于2003年最初由Ankur Kothari,Mihir Shukla,Neeti Mehta和Rushabh Parmani在加利福尼亚州圣何塞的Tethys Solutions,LLC成立。该软件公司在10多个国家/地区开展业务,开发适用于领先金融服务,业务流程外包,医疗保健,技术和保险公司的机器人过程自动化技术的产品。在RPA领域市场份额第一,全球最大的RPA生态,培训并认证超过10,000名RPA人员。
AA公司统计“暗数据”占比达80%,就像下图冰山在水下的部分。这些暗数据,导致信息是断裂的,传统的自动化不能访问。业界最头疼的就是如何处理这部分数据?
![]()
一、传统处理暗数据的方法
目前传统的公司,在处理暗数据的时候,采用的是笨办法,想办法把非结构化的数据转换成结构化数据。或者干脆,大部分公司是让这些暗数据躺在数据湖里沉睡中,没有任何用处,反而还浪费了存储和维护资源。像我们的站点数据、设备数据、网络数据、操作数据,大部分都是暗数据。我们现在花大力气在想办法结构化,这可能是最笨的办法。费时费力,结果还很差。
二、利用AI处理暗数据的新方法
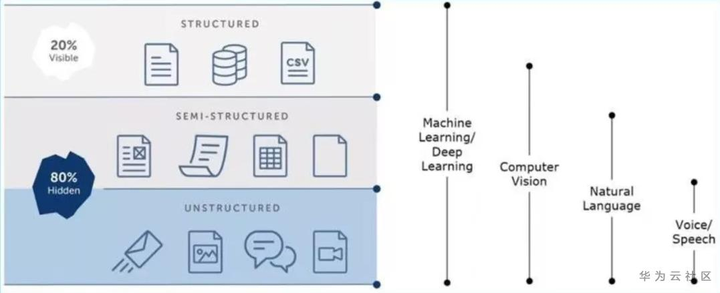
其实单纯的RPA做的工作非常有限,RPA主要是处理结构化和流程化的数据,不能处理“暗数据”。利用AI技术,就可以处理图片、邮件等暗数据,同时AI还可以随机应变的处理一些突发的流程。
下面列举了AI和RPA的差异点:
![]()
AA这家公司把AI和RPA结合起来,处理暗数据。使用的关键技术如下:
![]()
1、语音识别:主要处理对话、录音、音频等文件。
2、NLP:主要处理文本、邮件、文档等文件。
3、计算视觉:主要处理图片、PDF中嵌入的图片等信息。
4、机器学习&深度学习:主要通过“学习”,处理一些异常事件,让流程能正常流转,像人一样,能灵活处理问题。
三、AA这家公司推出的关键产品(或解决方案)
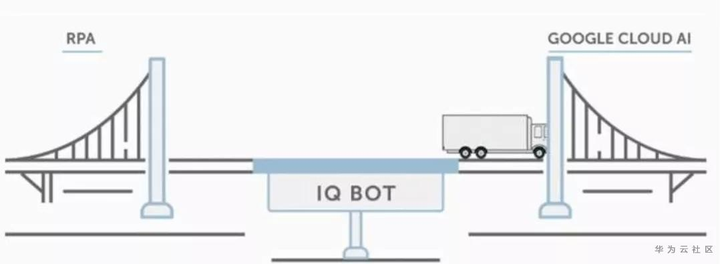
推出了IQ-Bot的解决方案。IQ Bot™是人工智能(AI)解决方案,业务用户可以轻松设置和使用,以更快地自动读取和处理各种复杂的文档和电子邮件。另外,IQ Bot通过构建的自动化认知,可与IBM Watson/Google Cloud AI/MS Cognitive Service等AI解决方案集成,以弥合RPA与纯认知平台之间的差距。
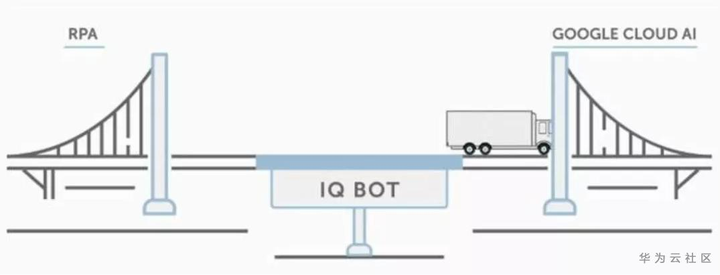
在其主页上呈现的IQ BOT解决方案的示例如图,重点是想说明IQ Bot是一座桥梁,可以连接RPA和认知平台:
![]()
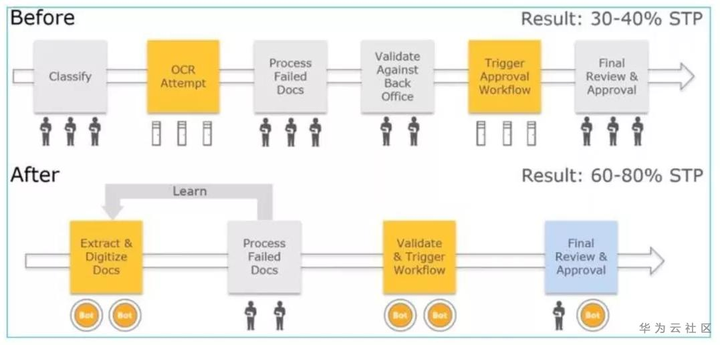
使用IQ-Bot前后对比
![]()
AI能够以内容为中心实现流程自动化,使AI成为理想的RPA的补充技术。 使用两者的组合,组织可以端到端自动化流程,例如使用AI,解析,分类和理解语义或情绪,并将所需的行动传递给RPA。 例如:完成使用AI为客户撰写确认函/文本或电子邮件等案例。
四、如何把AI嵌入到前台的RPA流程中去?
1、许多流程需要理解语义。利用AI中的NLP技术理解句子的结构,语义和意图。
通过统计方法和机器学习。NLP将文本转换为数据,反之亦然,允许人与人之间有意义的互动。它包括自然语言理解和生成,例如:保险公司处理索赔、银行抵押贷款,这些都需要补充材料,包括图片(身份证信息)、表格信息、邮件信息、文本信息等等,这些都是非结构化信息,很难直接使用RPA自动化,影响了这个流程的效率。文本,电子邮件,信件和图像,首先通过NLP和图像识别技术以便进一步处理。
2、利用计算机视觉技术自动提取,分析图片,转换成语义。
从单个图像或一系列图像(包括扫描文档)中理解有用信息,实现自动视觉理解。
3、通过ML(Machine Learning)来实现一些灵活化处理问题的能力。
通过算法来实现人处理问题的灵活性,无需明确固定的流程,可以通过“学习”来灵活处理,具备随机应变的处理机制,避免通过系统对接传递大量数据。
五、AI方法的借鉴意义?
这多年过去了,整个电信业界就没有搞定网络拓扑,特别是跨域和跨厂商的。我一直认为,通过采集上来的现有公开数据(不同厂商肯定有网管系统),通过数据的拼接,是可以拼出一个拓扑的。大家觉得不可能。其实想想Google地图,看看Google地图是怎么做到的?地图需要拼接的数据量肯定是网络信息的很多倍,难度也大于网络拓扑,但为什么地图能搞出来,而一个拓扑就搞不出来呢?利用数据的拼接+AI技术,是可以把整网跨厂商的网络拓扑拼接出来的。
六、给大家介绍的IQ Bot的目的是打开一扇窗,让大家去寻宝
IQ Bot:认知自动化机器人,是专门负责处理暗数据,IQ Bot发现和转换隐藏数据,以更快,更高效地自动化业务流程,同时消除人为错误。
![]()
在这个AI时代,如何让手里的数据发挥出价值成为在市场中杀出重围的重要的技能。企业面对内部大量的暗数据,需要建立高效的数据管理体系,学会妥善运用算法、简化流程,才能迎接这数据洪流时代。
本文作者作者:华为云社区高亮,点击关注,第一时间了解华为云新鲜技术~
![]()