Elasticsearch 数据同步工具 Elasticsearch-datatran 6.1.0 发布,Elasticsearch-datatran 是由 bboss 开源的一款将各种数据源中的海量数据同步到 Elasticsearch 的高效数据同步工具。
![]()
v6.1.0功能改进
-
如果在程序里面配置的增量字段类型发生改变,要把增量状态表对应的类型调整为最新的字段类型
设置了类型后,就按照类型来,不再按照设置的日期和数字字段名称来区分:
增加setLastValueColumn方法,废弃setDateLastValueColumn和setNumberLastValueColumn两个方法
-
DB-DB数据同步工具:增加在作业中直接指定sql语句的功能
-
修复数据同步bug:数据库到数据库跨库同步无效
-
可以通过ImportBuilder组件设置geoip数据库地址,使用案例:
importBuilder.setGeoipDatabase("E:/workspace/hnai/terminal/geolite2/GeoLite2-City.mmdb");
importBuilder.setGeoipAsnDatabase("E:/workspace/hnai/terminal/geolite2/GeoLite2-ASN.mmdb");
5.数据同步增加db-db数据同步spring boot案例工程:
https://github.com/bbossgroups/db-db-job
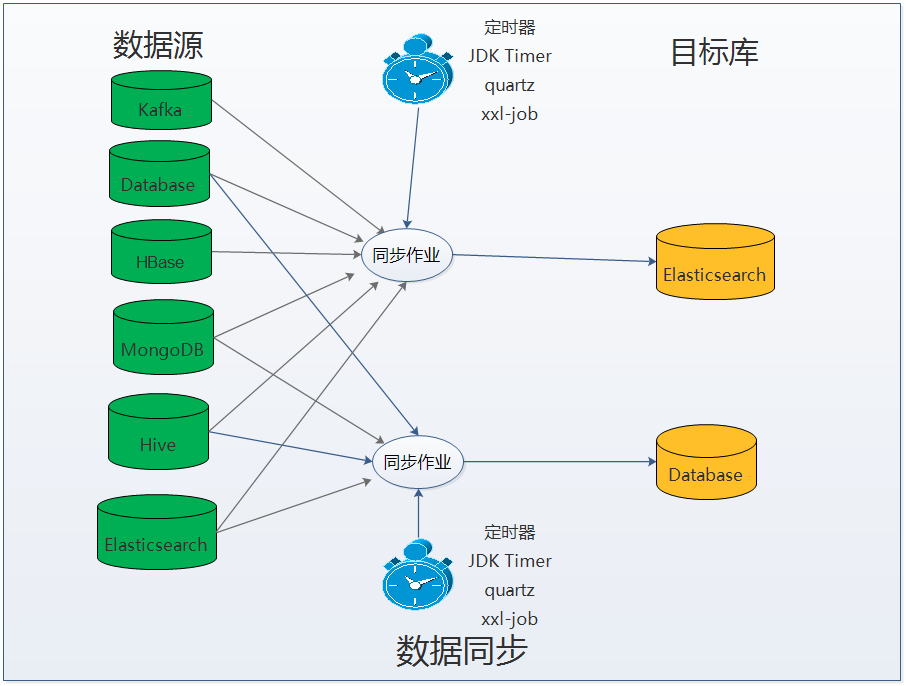
Elasticsearch-datatran功能特点
1.支持多种数据源之间的数据同步
2.支持增删改数据同步
3.支持多种数据导入方式
- 批量数据导入
- 批量数据多线程并行导入
- 定时全量(串行/并行)数据导入
- 定时增量(串行/并行)数据导入
4.支持的数据库和消息中间件类型
数据库: mysql,maridb,postgress,oracle ,sqlserver,db2,tidb,hive,mongodb、HBase、elasticsearch、达梦等
消息中间件:kafka 1x,kafka 2x
5.Elasticsearch版本兼容性
Elasticsearch 1.x,2.x,5.x,6.x,7.x,+
6.支持海量PB级数据同步导入Elasticsearch
7.支持将ip转换为对应的运营商/省份城市/经纬度坐标位置信息
8.支持设置数据bulk导入任务结果处理回调函数,对每次bulk任务的结果进行成功和失败反馈,然后针对失败的bulk任务通过error和exception方法进行相应处理
9.支持多种定时任务执行引擎
10.基于java语言开发和发布数据同步作业
bboss elasticsearch数据同步工具另一个显著的特色就是直接基于java语言来编写数据同步作业程序,基于强大的java语言和第三方工具包,能够非常方便地加工和处理需要同步的源数据,然后将最终的数据保存到目标库(Elasticsearch或者数据库);同时也可以非常方便地在idea或者eclipse中调试和运行同步作业程序,调试无误后,通过bboss提供的gradle打包构建脚本,即可发布出可部署到生产环境的同步作业包。
11.支持两种作业运行方式
- 嵌入到应用中运行,基于quartz和jdk timer调度的作业都可以运行在这种模式下,参考文档:spring boot运行案例
- 独立发布包运行,基于quartz和xxl-job,jdk timer调度的作业都可以运行在这种模式下,参考文档:作业发布
更新说明:https://esdoc.bbossgroups.com/#/changelog