![]()
2个月前开源了Dragonboat这个Go实现的高性能多组Raft共识库,它的一大卖点是其高吞吐性能,在使用内存内的状态机的场景下,能在三组单插服务器上达到千万每秒的吞吐性能。作为个人用Go写的第一个较大的应用库,Dragonboat的开发过程可谓踏坑无数,逐步才具备了目前的性能和可靠性。本文选取几个在各类Go项目中踏坑概率较高的具有普遍性的问题,以Dragonboat踏坑详细过程为背景,具体分享。
Channel的实现没有黑科技
虽然是最核心与基础的内建类型,chan的实现却真的没有黑科技,它的性能很普通。
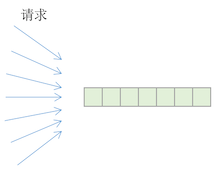
在Dragonboat的旧版中,有大致入下的这样一段核心代码。它在有待处理的读写请求的时候,用以通知执行引擎。名为workReadyCh的channel系统中有很多个,执行引擎的每个worker一个,client用它来提供待处理请求的信息v。而考虑到该channel可能已满且等待的时候系统可能被关闭,一个全局唯一的用于表示系统已被要求关闭的channel会一起被select,用以接收系统关闭的通知。
select {
case <-closeCh:
return
case workReadyCh<-v:
}
这大概是Go最常见的访问channel的pattern之一,实在太常见了!暂且不论千万每秒的写吞吐意味着每秒千万次的channel的写这一问题本身(前文详细分析),数万并发请求的goroutine通过数十个OS thread同时去select一个全局唯一的closeCh就已足够把高性能秒杀成了低性能蜗牛。
![]()
这种大量线程互相踩踏式的select访问一个channel所凸显的chan性能问题Go社群有详细讨论。该Issue讨论里贴出的profiling结果如下,很直观。但很遗憾,runtime层面无解决方案,而无锁channel的实现上虽然众人前赴后继,终无任何突破。现实中的Go runtime没有黑科技,它只提供性能很一般的chan。
![]()
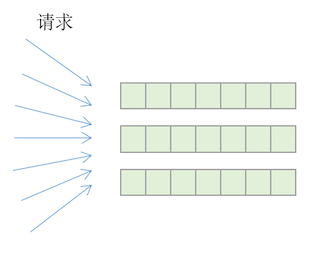
为了绕开该坑,还是得从应用设计出发,把上述单一的closeCh分区做sharding,根据不同的Raft组的组号,由不同的chan来负责做系统已关闭这一情况的通知。此改进立刻大幅度缓解了上述性能问题。更进一步的优化,更能完全排除掉上述访问模式,这也是目前的实现方法,篇幅原因这里不展开。
![]()
sync.RWMutex随核心数升高其性能伸展性不佳
下面是Dragonboat老版本上抓的一段cpu profiling的结果,RWMutex的RLock和RUnlock性能很差,用于保护这个map的RWMutex上的耗时比访问map本身高一个数量级。
![]()
这是因为在高核心数下,大量RLock和RUnlock请求会在锁的同一个内存位置并发的去做atomic write。与上面chan的问题类似,还是高contention。
RWMutex的性能问题是一个困扰Go社区很久但至今没有在标准库层面上解决的问题(#17973)。有用户提出过一种称为Big Reader的变种,在牺牲写锁性能的前提下改善读锁的操作性能。但此时写锁的性能是崩跌的,以Intel LGA3647处理器高端双插服务器为例,Big Reader锁在操作写锁的时候需要对112个RWMutex做Lock/Unlock操作,因此只适用于读写比极大的场景,不具备通用性。
在Dragonboat中,所观察到的上述RWMutex问题,其本质在于在每次对某个Raft组做读写之前都需要反复去查询获取该指定的Raft节点。显然,无论锁的实现本身如何优化,或是改用sync.Map来替代上述需要锁保护的map的使用,试图去避免反复做此类无意义的重复查询,才是从根本上解决问题。本例中,Big Reader变种是适用的,软件后期也改用了sync.Map,但避免反复的getCluster操作则彻底避免锁操作,完全饶开了锁的实现和用法是否高效这点。减少不必要操作,远比把此类多余的操作变得更高效来的直接有效。
Cgo远没那么烂
前两年网上无脑Go黑的四大必选兵器肯定是:GC性能、依赖管理、Cgo性能和错误处理。GC性能这两年已经在停顿方面吊打Java,吞吐的改进也在积极进行中。Go 1.12版Module的引入从官方工具层面关管住了依赖管理,而Go 2对错误处理也将有大改进。种种这些之外,Cgo的性能依旧误解重重。
多吹无意义,先跑个分,看看Cgo究竟多"慢":
![]()
调用一个简单的C实现的函数的开销是60ns级,和一次没有cache的对内存的访问一样。
这是什么概念呢?用个踩过的坑来说明吧。Dragonboat早期版本对RocksDB的WriteBatch的Put操作是一次操作一个Raft Log Entry,一秒该Cgo请求在多个goroutine上共并行操作数百万次。因为听信网上无脑黑对Cgo的评价,起初认为这显然是严重性能问题,于是优化归并后大幅度减少了Cgo调用次数。可结果发现这对延迟、吞吐的性能改进很小很小。事后再跑profiler去看旧的实现,发现旧版的Cgo开销起初便完全不主要。
Go内建了很好的benchmark工具,一切性能的讨论都应该是基于客观有效的benchmark跑分结果,而不是诸如“我认为”、“我感觉”之类的无脑互蒙。
Goroutine泄漏与内存泄漏一样普遍
Goroutine的最大卖点是量大价廉使用方便,一个程序里轻松开启万把个Goroutine基本都不用考虑其本身的代价......一切似乎很美好,直到系统内类型众多的Goroutine开始泄漏。也许是因为Goroutine的特性,它在Go程序里的使用的频度密度远超线程在Java/C++程序中情况,同时用户思维中Goroutine简单易用代价低的概念根深蒂固、与生俱来,无形中更容易放松对资源管理的考虑,因此更容易发生Goroutine泄漏情况。Dragonboat的经验是Goroutine泄漏的概率不比内存泄漏少。
Dragonboat从实现之初就开始使用Goroutine泄漏检查,具体的泄漏检查的实现是来自CockroachDB的一小段代码。效果方面,这个小工具发现过Dragonboat及其依赖的第三方库里多个goroutine泄漏问题,而使用上,在各内建的测试中,只需一行便能完成调用得到结果,绝对是费效比完美。
![]()
实现上它也特别简单,就是前后两次分别抓stacktrace,解析出进程里所有的Goroutine ID并对比是否测试运行结束后产生了多余的滞留在系统中的Goroutine。官方虽然不倡导对Goroutine ID做任何操作,但此类仅在测试中仅针对Goroutine泄漏的特殊场景的使用,应该不拘泥于该约束,这就如同官方不怎么推荐用sync/atomic一个道理。
总结
基于Dragonboat的几个具体例子,本文分享了几个常见的Go性能与使用问题。总结来说:
通过sharding分区减少contention是优化常用手段 做的再快也不可能比什么也不做更快,减少不必要操作比优化这个操作有效 多用Go内建的benchmark功能,数据为导向的做决策 官方提倡的东西肯定有他的道理,但在合适的情况下,需懂得如何无视某些官方的提倡
后续将再推出针对Go内存性能优化的文章,敬请期待。在阅读完此干货软文后,也请大家访问Dragonboat项目并点star支持!谢谢阅读。