在上一篇我们搭建flutter环境之后,并且创建了一个HelloFlutter我们的第一个demo,接下来让我们看一看flutter的工程目录以及创建项目运行代码的部分解析。
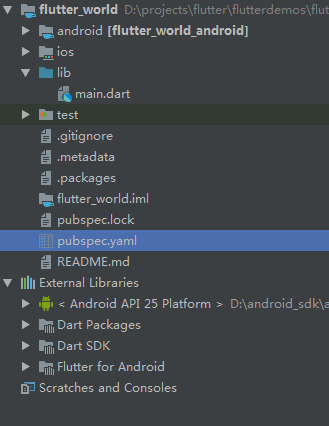
首先工程目录如下:
![]()
主要分为四个部分,第一个部分是Android,第二个部分是iOS,第三个部分是类似build.gradle的配置文件pubspec.yaml,第四个部分是lib文件夹,里面存放我们编写的基于dart语言的源代码,前两个部分不会涉及到,我们主要是写dart来实现跨平台。
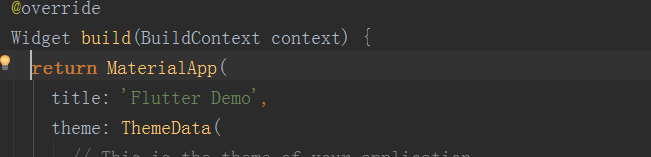
那我们接下来看一下lib下面有一个main.dart的文件,打开之后如下:
![]()
首先看
void main() => runApp(MyApp());
这是程序的入口函数,进来首先会调用runApp方法,这里用到了=>箭头函数和如下格式类似:
main(){
return new MyApp();
}
Dart中的箭头函数,跟kotlin很像。
其实=> runApp(MyApp()); 等同于
{
return new MyApp();
}
那说到这里就要说一下dart的匿名函数和=>箭头函数是怎么声明的,说白了匿名的含义就是没有名字的函数,格式如下:
([[Type] param1[, …]]) {
codeBlock;
};
其实上面如果用箭头函数来表示,如下:
([[Type] param1[, …]]) => codeBlock;
所以{codeBlock}等同于 =>codeBlock,举个例子:
var list = ['apples', 'bananas', 'oranges'];
list.forEach((item) {
print('${list.indexOf(item)}: $item');
});
箭头函数如下:
list.forEach((item) => print('${list.indexOf(item)}: $item'));
上面的示例定义了一个具有无类型参数的匿名函数item,该函数被list中的每个item调用,输出一个字符串,该字符串包含指定索引处的值。
接着说main函数返回一个widget,MyApp就是我们要展示的启动界面。
这里的MyApp类中返回了一个MaterialApp widget,MaterialApp可以理解为ui的风格,Android上就是这种风格的UI. ios上我们可以使用CupertinoApp。这个可以自己修改尝试在MaterialApp中我们可以配置主题颜色,控件的样式等等。
![]()
这里相当于Android中的Application类, StatelessWidget表示无状态控件。
![]()
MaterialApp表明app的风格是Material Design风格的,这里我们可以配置app的主题相关属性比如颜色,
按钮风格等等,类似于Android中的style文件。
![]()
主题相关配置,这里我们可以配合app整体的主题样式,比如整体颜色,控件默认的样式等。
这个地方就类似于Android中的style文件配置,主要就是主题的配置。
home指定了启动后显示的页面,类似于我们在AndroidManifest中配置启动页面,也就是Android里面的MainActivity。
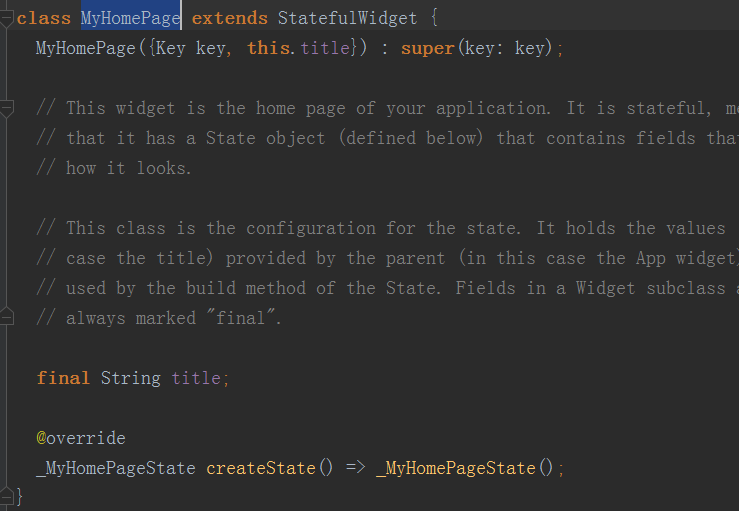
接下来我们看一下MyHomePage这个类
![]()
StatefulWidget是一个有状态的控件,如果你的页面需要更新ui,那么该页面就要继承自StatefulWidget,所以这个类基本上是必须要继承的,
跟Android我们要继承activity的意义差不多,如果只是一个纯展示的页面,只需要继承自StatelessWidget即可,也就是一些静态页面
MyHomePage在上面已经被指定为启动页面,该页面有一个计数的逻辑,会更新ui,所以需要继承自StatefulWidget。
这里我们看一下它的构造函数的格式跟Java不一样吧,这是dart语言特有的可选参数,举个例子:
//◦可选的命名参数, 定义函数时,使用{param1, param2, …},用于指定命名参数。例如
//设置[bold]和[hidden]标志
void enableFlags({bool bold, bool hidden}) {
// ...
print(bold.toString()+"、"+hidden.toString());
}
//这里可以随便改变传入参数的顺序
enableFlags(bold: true, hidden: false);
我们可以随意更改传参的顺序。
还有一种可选的位置参数,举个例子:、
//◦可选的位置参数,用[]它们标记为可选的位置参数:
String say(String from, String msg, [String device]) {
var result = '$from says $msg';
if (device != null) {
result = '$result with a $device';
}
print(result);
return result;
}
//可以传也可以不传,相当于Java重载
say('Bob', 'Howdy'); //结果是: Bob says Howdy
say('Bob', 'Howdy', 'smoke signal'); //结果是:Bob says Howdy with a smoke signal
这里就看到了,我们可以传也可以不传,个人感觉跟Java的 重载类似。
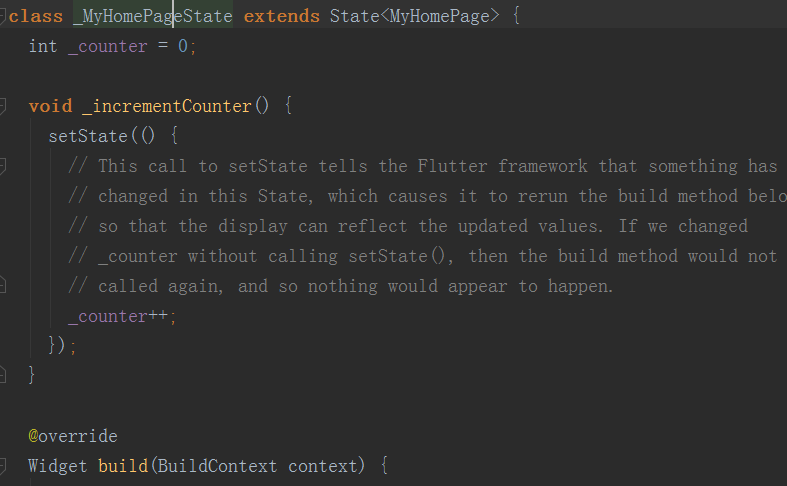
接着说,所有继承自StatefulWidget的控件都要重写createState()这个方法,可以理解为指定该页面的状态是由谁来控制的,
在Dart中下划线开头声明的变量和方法,其默认访问权限就是私有的, 类似于java中用private关键字修饰,只能在类的内部访问。
这里我们需要指出的是我们需要_MyHomePageState这个类的对象来控制这个界面,所以我们重写createState()这个方法,并且返回了_MyHomePageState对象,并且大家有注意到么,这里用到了箭头函数,我们之前说的,所以这里如果不用箭头函数的话可以如下代替:
@override
_MyHomePageState createState() {
return _MyHomePageState();
}
看到这里是不是觉得这不就是Java的方法重写并且return么,其实箭头函数后面指向的就是我们要rerun的代码。
![]()
State是一个状态对象,<>里面是表示该状态是跟谁绑定的,我们修改状态时就是在该类中进行编写。
我们主要看一下build方法:
![]()
Scaffold可以看作是Material Design中的一个模板,看源码发现它继承自StatefulWidget,包含了appBar,body,drawer等控件。
appBar 相当于Android中的ToolBar。
其实看起来就是return一个Scaffold对象,这个对象的实例化需要我们传入一些参数,传参数的格式跟Java不一样而已,我们需要传递appBar、body、floatingActionButton这个浮动按钮,然后每个参数也是个对象,我们看代码很容易看到比如appBar需要传递title这个参数即可,这个title也是一个对象Text,它也需要一个参数widget.title,这里的widget实际上就是MyHomePage。
建议初学flutter的同学还是不要急着先弄工程,先把dart语言的基本api的使用弄清楚了,再来敲代码就会快很多了。