一、前言
对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交、并、差、聚合、排序等过程。而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么要想求得某个key对应的全量数据,那就必须把相同key的数据汇集到同一个Reduce任务节点来处理,那么Mapreduce范式定义了一个叫做Shuffle的过程来实现这个效果。
二、编写本文的目的
本文旨在剖析Hadoop和Spark的Shuffle过程,并对比两者Shuffle的差异。
三、Hadoop的Shuffle过程
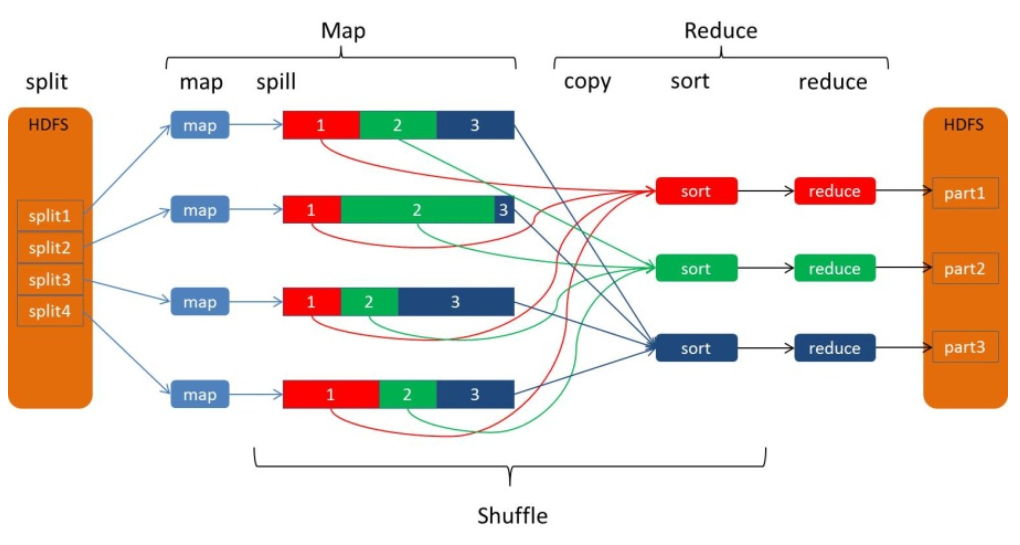
Shuffle描述的是数据从Map端到Reduce端的过程,大致分为排序(sort)、溢写(spill)、合并(merge)、拉取拷贝(Copy)、合并排序(merge sort)这几个过程,大体流程如下:
![]()
上图的Map的输出的文件被分片为红绿蓝三个分片,这个分片的就是根据Key为条件来分片的,分片算法可以自己实现,例如Hash、Range等,最终Reduce任务只拉取对应颜色的数据来进行处理,就实现把相同的Key拉取到相同的Reduce节点处理的功能。下面分开来说Shuffle的的各个过程。
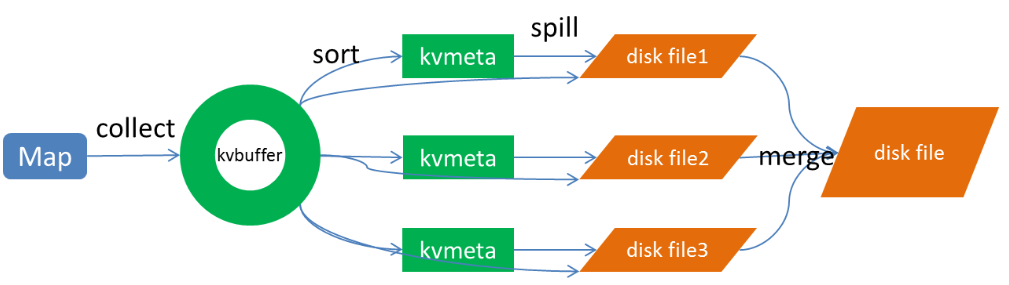
Map端做了下图所示的操作:
![]()
1、Map端sort
Map端的输出数据,先写环形缓存区kvbuffer,当环形缓冲区到达一个阀值(可以通过配置文件设置,默认80),便要开始溢写,但溢写之前会有一个sort操作,这个sort操作先把Kvbuffer中的数据按照partition值和key两个关键字来排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
2、spill(溢写)
当排序完成,便开始把数据刷到磁盘,刷磁盘的过程以分区为单位,一个分区写完,写下一个分区,分区内数据有序,最终实际上会多次溢写,然后生成多个文件
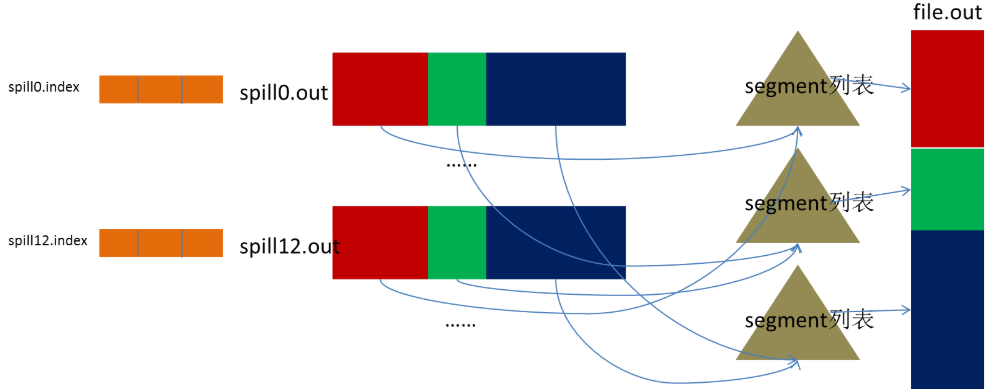
3、merge(合并)
spill会生成多个小文件,对于Reduce端拉取数据是相当低效的,那么这时候就有了merge的过程,合并的过程也是同分片的合并成一个片段(segment),最终所有的segment组装成一个最终文件,那么合并过程就完成了,如下图所示
![]()
至此,Map的操作就已经完成,Reduce端操作即将登场
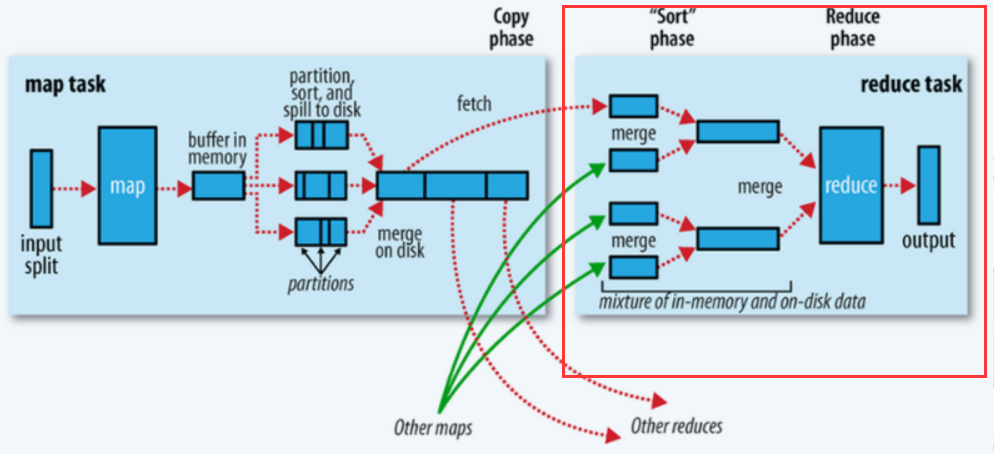
Reduce操作
总体过程如下图的红框处:
![]()
1、拉取拷贝(fetch copy)
Reduce任务通过向各个Map任务拉取对应分片。这个过程都是以Http协议完成,每个Map节点都会启动一个常驻的HTTP server服务,Reduce节点会请求这个Http Server拉取数据,这个过程完全通过网络传输,所以是一个非常重量级的操作。
2、合并排序
Reduce端,拉取到各个Map节点对应分片的数据之后,会进行再次排序,排序完成,结果丢给Reduce函数进行计算。
四、总结
至此整个shuffle过程完成,最后总结几点:
1、shuffle过程就是为了对key进行全局聚合
2、排序操作伴随着整个shuffle过程,所以Hadoop的shuffle是sort-based的