抗击疫情,众志成城,人工智能技术正被应用到疫情防控中来。
2月13日,百度宣布免费开源业内首个口罩人脸检测及分类模型。该模型可以有效检测在密集人流区域中携带和未携戴口罩的所有人脸,同时判断该者是否佩戴口罩。目前已通过飞桨PaddleHub开源出来,广大开发者用几行代码即可快速上手,免费调用。
![]()
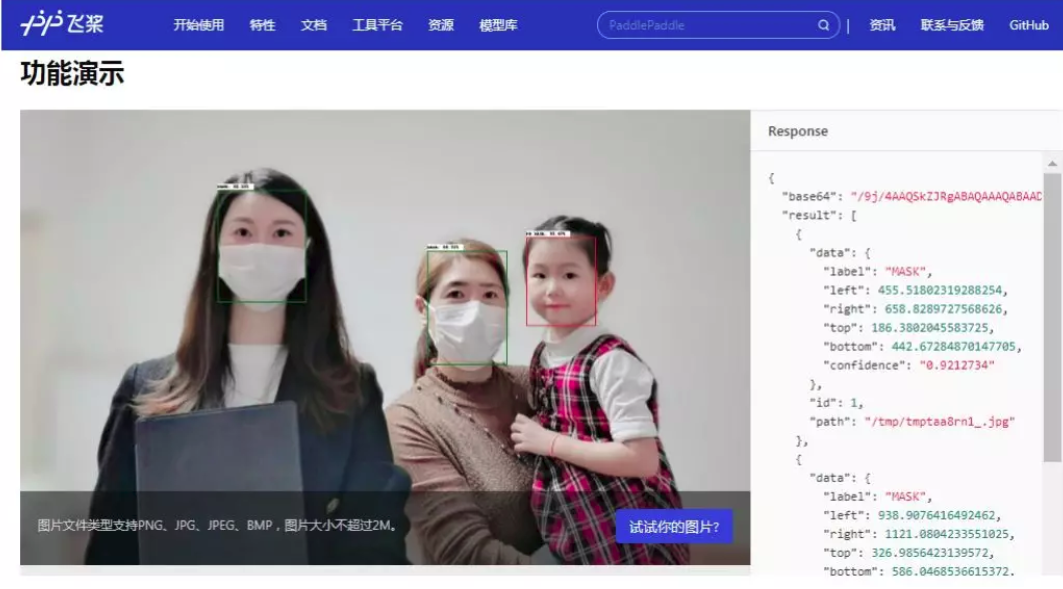
模型可视化效果:绿框为佩戴口罩标注,红框为未佩戴口罩标注
随着本周各企业相继复工,节后经济开始逐渐恢复,人脸口罩检测方案成为返工潮中众多社区、大型厂商、央企的重要需求。如判断工区员工是否佩戴口罩、人流密集的关口运输中心如何识别戴口罩的人脸并测温、佩戴口罩是否也能完成日常刷脸打卡等等……都是新冠肺炎疫情下需要解决的真实痛点。
此次宣布免费开源的自研口罩人脸检测及分类模型,是基于2018年百度收录于国际顶级计算机视觉会议ECCV的论文PyramidBox研发,可以在人流密集的公共场景检测海量人脸的同时,将佩戴口罩和未佩戴口罩的人脸快速识别标注。基于此预训练模型,开发者仅需使用少量自有数据,便可快速完成自有场景的模型开发。
百度研发工程师介绍,口罩人脸检测及分类模型,由两个功能单元组成,可以分别完成口罩人脸的检测和口罩人脸的分类。经测试,模型的人脸检测算法基于faceboxes的主干网络加入了超过10万张口罩人脸数据训练,可在准确率98%的情况下,召回率显著提升30%。而人脸口罩判断模型可实现对人脸是否佩戴口罩的判定,口罩判别准确率达到96.5%,满足常规口罩检测需求。开发者基于自有场景数据还可进行二次模型优化,可进一步提升模型准确率和召回率。
如此高的准确率的背后是大量数据训练的结果,新模型采用了超过十万张图片的训练数据,确保样本量足够且有效。另一方面,人脸检测模型基于百度自研的冠军算法,整个研发过程都是基于百度开源的飞桨深度学习平台,能够进行高效、便捷的模型开发、训练、部署。
在线演示效果:绿色边界框为戴口罩人脸、红色边界框为不戴口罩人脸。感兴趣的开发者可自己上传图片测试模型的效果。
![]()
在线演示地址:
https://www.paddlepaddle.org.cn/hub/scene/maskdetect
对于实际场景中的光照、口罩遮挡、表情变化、尺度变化等问题,模型具有鲁棒性,并且能够在多种不同端、边、云设备上实时检测,在落地过程中做到真正实用。
预训练模型,立即部署
为了最大程度方便开发者应用,百度深度学习平台飞桨通过简单易用的预训练模型管理工具PaddleHub将人脸口罩检测模型开源出来,只需基本的python编程能力,即可快速上手调用,如果具有一定的移动端APP开发能力,也可以快速将模型部署到移动端上。
顶尖算法与数据
这一方案中,用于识别人脸的模型基于 2018 年百度在国际顶级计算机视觉会议 ECCV 2018 的论文 PyramidBox 而研发,基于自研的飞桨开源深度学习平台进行训练,并通过PaddleSlim 等模型小型化技术使得算法能够高效运行在一些算力有限的设备上。
此外飞桨还将提供海量二次开发的工具组件,以及更多的人脸相关检测算法,以上所有技术及工具都是开源且免费的。
实践过程
只要五行代码,就可以在自己的计算机处理口罩人脸检测。实际在采用 CPU 的情况下,检测基本是实时的,推断速度非常快。以下为调用预训练模型的核心代码,其中在当前文件夹下放了一张测试图像:
import paddlehub as hub
# 加载模型,本例为服务器端模型pyramidbox_lite_server_mask# 移动端模型参数可以换成pyramidbox_lite_mobile_maskmodule = hub.Module(name="pyramidbox_lite_server_mask")
# 设置输入数据input_dict = {"image": ["test.jpg"]}for data in module.face_detection(data=input_dict): print(data)
更重要的是,作为一项完善的开源工作,除了本地推断以外,其还需要考虑如何将模型部署到服务器或移动设备中。若能快速部署到各平台,那么才真正意味着它可以作为「战疫」的基础工具。
目前,百度提供了两个预训练模型,即服务器端口罩人脸检测及分类模型「pyramidbox_lite_server_mask」、以及移动端口罩人脸检测及分类模型「pyramidbox_lite_mobile_mask」,这两者能满足各种下游任务。
1. 一步部署服务器
借助 PaddleHub,服务器端的部署也非常简单,直接用一条命令行在服务器启动口罩人脸检测与分类模型就行了:
hub serving start -m pyramidbox_lite_server_mask -p 8866
2. 部署到移动端
Paddle Lite 是飞桨的端侧推理引擎,专门面向移动端的模型推理部署。如果需要把口罩人脸检测及分类模型嵌入到手机等移动设备,那么 Paddle Lite 这样的端侧推理引擎能够帮助节省很多工作。
在移动端部署口罩人脸检测及分类模型,也只需要三步:
①下载预测库,Paddle Lite 会提供编译好的预测库;
②优化模型,使用 model_optimize_tool 工具实现模型优化;
③通过预测 API 实现调用。
开发者可以通过PaddleHub下载人脸口罩识别模型。在正常安装PaddleHub以后,可以通过python执行以下代码下载并保存模型,以下载保存移动端人脸口罩识别模型为例:
import paddlehub as hub
module = hub.Module(name="pyramidbox_lite_mobile_mask")
# 将模型保存在test_program文件夹之中
module.processor.save_inference_model(dirname="test_program")
通过以上代码,可以获得人脸检测和口罩佩戴判断模型,分别存储在test_program 目录下的pyramidbox_lite和mask_detector子文件夹之中。文件夹中的__model__是模型结构文件,__param__文件是权重文件。
Paddle Lite 介绍:
https://github.com/PaddlePaddle/Paddle-Lite
其中比较重要的是移动端 API 调用方法,具体实现请参考下文给出的 Paddle Lite 的示例地址。
// 读取图片
cv::Mat img = imread(img_path, cv::IMREAD_COLOR);
// 加载人脸检测或者口罩佩戴判别模型
MobileConfig config;
config.set_model_dir(model_dir);
PaddlePredictor* predictor =
CreatePaddlePredictor<MobileConfig>(config);
// 设置输入
Tensor* input_tensor = predictor->GetInput(0);
input_tensor->Resize({1, 3, img.rows,img.cols});
set_input(img, input_tensor); //调用自定义函数
// 执行
predictor->Run();
// 输出结果
Tensor* output_tensor = predictor->GetOutput(0);
show_output(img, output_tensor); //调用自定义函数
人脸识别和佩戴口罩判断在移动端部署的示例地址为:
https://github.com/PaddlePaddle/Paddle-Lite/tree/develop/lite/demo/cxx