无论是在早期的负载均衡器中,还是当前微服务基于客户端的负载均衡中,都有一个最基础的轮询算法,即将请求平均分布给多台机器,今天聊聊在此基础上, kube proxy是如何实现亲和性轮询的核心数据结构. 了解亲和性策略实现,失败重试等机制
1. 基础筑基
1.1 Service与Endpoints
![image.png]() Service和Endpoint是kubernetes中的概念,其中Service代表一个服务,后面通常会对应一堆pod,因为pod的ip并不是固定的,用Servicel来提供后端一组pod的统一访问入口, 而Endpoints则是一组后端提供相同服务的IP和端口集合 在这节内容中大家知道这些就可以来,
Service和Endpoint是kubernetes中的概念,其中Service代表一个服务,后面通常会对应一堆pod,因为pod的ip并不是固定的,用Servicel来提供后端一组pod的统一访问入口, 而Endpoints则是一组后端提供相同服务的IP和端口集合 在这节内容中大家知道这些就可以来,
1.2 轮询算法
![image.png]() 轮询算法可能是最简单的算法了,在go里面大多数实现都是通过一个slice存储当前可以访问的后端所有地址,而通过index来保存下一次请求分配的主机在slice中的索引
轮询算法可能是最简单的算法了,在go里面大多数实现都是通过一个slice存储当前可以访问的后端所有地址,而通过index来保存下一次请求分配的主机在slice中的索引
1.3 亲和性
![image.png]() 亲和性实现上也相对简单,所谓亲和性其实就是当某个IP重复调用后端某个服务,则将其转发到之前转发的机器上即可
亲和性实现上也相对简单,所谓亲和性其实就是当某个IP重复调用后端某个服务,则将其转发到之前转发的机器上即可
2. 核心数据结构实现
2.1 亲和性实现
![image.png]()
2.1.1 亲和性之亲和性策略
亲和性策略设计上主要是分为三个部分实现: affinityPolicy:亲和性类型,即根据客户端的什么信息来做亲和性依据,现在是基于clientip affinityMap:根据Policy中定义的亲和性的类型作为hash的key, 存储clientip的亲和性信息 ttlSeconds: 存储亲和性的过期时间, 即当超过该时间则会重新进行RR轮询算法选择
type affinityPolicy struct {
affinityType v1.ServiceAffinity // Type字段只是一个字符串不需要深究
affinityMap map[string]*affinityState // map client IP -> affinity info
ttlSeconds int
}
2.1.2 亲和性之亲和性状态
上面提到会通过affinityMap存储亲和性状态, 其实亲和性状态里面关键信息有两个endpoint(后端要访问的endpoint)和lastUsed(亲和性最后被访问的时间)
type affinityState struct {
clientIP string
//clientProtocol api.Protocol //not yet used
//sessionCookie string //not yet used
endpoint string
lastUsed time.Time
}
2.2 Service数据结构之负载均衡状态
![image.png]() balancerState存储当前Service的负载均衡状态数据,其中endpoints存储后端pod的ip:port集合, index则是实现RR轮询算法的节点索引, affinity存储对应的亲和性策略数据
balancerState存储当前Service的负载均衡状态数据,其中endpoints存储后端pod的ip:port集合, index则是实现RR轮询算法的节点索引, affinity存储对应的亲和性策略数据
type balancerState struct {
endpoints []string // a list of "ip:port" style strings
index int // current index into endpoints
affinity affinityPolicy
}
2.3 负载均衡轮询数据结构
![image.png]() 核心数据结构主要通过services字段来保存服务对应的负载均衡状态,并通过读写锁来进行service map进行保护
核心数据结构主要通过services字段来保存服务对应的负载均衡状态,并通过读写锁来进行service map进行保护
type LoadBalancerRR struct {
lock sync.RWMutex
services map[proxy.ServicePortName]*balancerState
}
2.4 负载均衡算法实现
我们只关注负载均衡进行轮询与亲和性分配的相关实现,对于感知service与endpoints部分代码,省略更新删除等逻辑, 下面章节是NextEndpoint实现
2.4.1 加锁与合法性效验
合法性效验主要是检测对应的服务是否存在,并且检查对应的endpoint是否存在
lb.lock.Lock()
defer lb.lock.Unlock() // 加锁
// 进行服务是否存在检测
state, exists := lb.services[svcPort]
if !exists || state == nil {
return "", ErrMissingServiceEntry
}
// 检查服务是否有服务的endpoint
if len(state.endpoints) == 0 {
return "", ErrMissingEndpoints
}
klog.V(4).Infof("NextEndpoint for service %q, srcAddr=%v: endpoints: %+v", svcPort, srcAddr, state.endpoints)
2.4.2 亲和性类型支持检测
通过检测亲和性类型,确定当前是否支持亲和性,即通过检查对应的字段是否设置
sessionAffinityEnabled := isSessionAffinity(&state.affinity)
func isSessionAffinity(affinity *affinityPolicy) bool {
// Should never be empty string, but checking for it to be safe.
if affinity.affinityType == "" || affinity.affinityType == v1.ServiceAffinityNone {
return false
}
return true
}
2.4.3 亲和性匹配与最后访问更新
亲和性匹配则会优先返回对应的endpoint,但是如果此时该endpoint已经访问失败了,则就需要重新选择节点,就需要重置亲和性
var ipaddr string
if sessionAffinityEnabled {
// Caution: don't shadow ipaddr
var err error
// 获取对应的srcIP当前是根据客户端的ip进行匹配
ipaddr, _, err = net.SplitHostPort(srcAddr.String())
if err != nil {
return "", fmt.Errorf("malformed source address %q: %v", srcAddr.String(), err)
}
// 亲和性重置,默认情况下是false, 但是如果当前的endpoint访问出错,则需要重置
// 因为已经连接出错了,肯定要重新选择一台机器,当前的亲和性就不能继续使用了
if !sessionAffinityReset {
// 如果发现亲和性存在,则返回对应的endpoint
sessionAffinity, exists := state.affinity.affinityMap[ipaddr]
if exists && int(time.Since(sessionAffinity.lastUsed).Seconds()) < state.affinity.ttlSeconds {
// Affinity wins.
endpoint := sessionAffinity.endpoint
sessionAffinity.lastUsed = time.Now()
klog.V(4).Infof("NextEndpoint for service %q from IP %s with sessionAffinity %#v: %s", svcPort, ipaddr, sessionAffinity, endpoint)
return endpoint, nil
}
}
}
2.4.4 根据clientIP构建亲和性状态
// 获取一个endpoint, 并更新索引
endpoint := state.endpoints[state.index]
state.index = (state.index + 1) % len(state.endpoints)
if sessionAffinityEnabled {
// 保存亲和性状态
var affinity *affinityState
affinity = state.affinity.affinityMap[ipaddr]
if affinity == nil {
affinity = new(affinityState) //&affinityState{ipaddr, "TCP", "", endpoint, time.Now()}
state.affinity.affinityMap[ipaddr] = affinity
}
affinity.lastUsed = time.Now()
affinity.endpoint = endpoint
affinity.clientIP = ipaddr
klog.V(4).Infof("Updated affinity key %s: %#v", ipaddr, state.affinity.affinityMap[ipaddr])
}
return endpoint, nil
好了,今天的分析就到这里,希望能帮组到大家,了解亲和性轮询算法的实现, 学习到核心的数据结构设计,以及在产生中应对故障的一些设计,就到这里,感谢大家分享关注,谢谢大家
> 微信号:baxiaoshi2020 ![]() > 关注公告号阅读更多源码分析文章
> 关注公告号阅读更多源码分析文章 ![21天大棚]() > 更多文章关注 www.sreguide.com > 本文由博客一文多发平台 OpenWrite 发布
> 更多文章关注 www.sreguide.com > 本文由博客一文多发平台 OpenWrite 发布
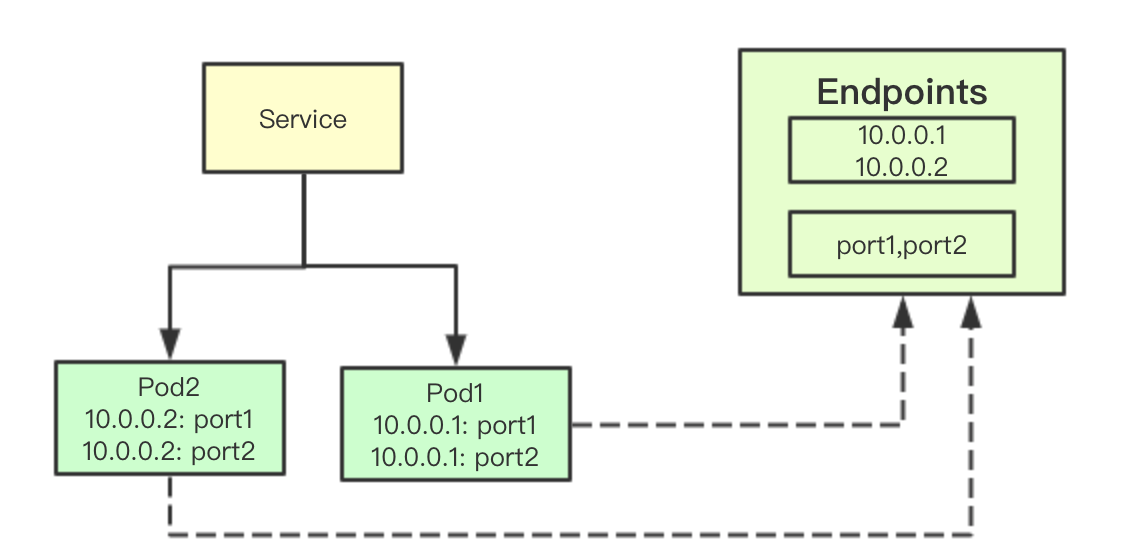 Service和Endpoint是kubernetes中的概念,其中Service代表一个服务,后面通常会对应一堆pod,因为pod的ip并不是固定的,用Servicel来提供后端一组pod的统一访问入口, 而Endpoints则是一组后端提供相同服务的IP和端口集合 在这节内容中大家知道这些就可以来,
Service和Endpoint是kubernetes中的概念,其中Service代表一个服务,后面通常会对应一堆pod,因为pod的ip并不是固定的,用Servicel来提供后端一组pod的统一访问入口, 而Endpoints则是一组后端提供相同服务的IP和端口集合 在这节内容中大家知道这些就可以来,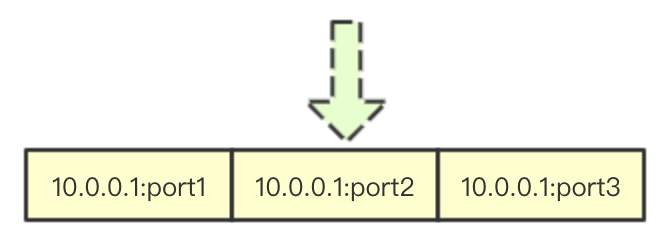 轮询算法可能是最简单的算法了,在go里面大多数实现都是通过一个slice存储当前可以访问的后端所有地址,而通过index来保存下一次请求分配的主机在slice中的索引
轮询算法可能是最简单的算法了,在go里面大多数实现都是通过一个slice存储当前可以访问的后端所有地址,而通过index来保存下一次请求分配的主机在slice中的索引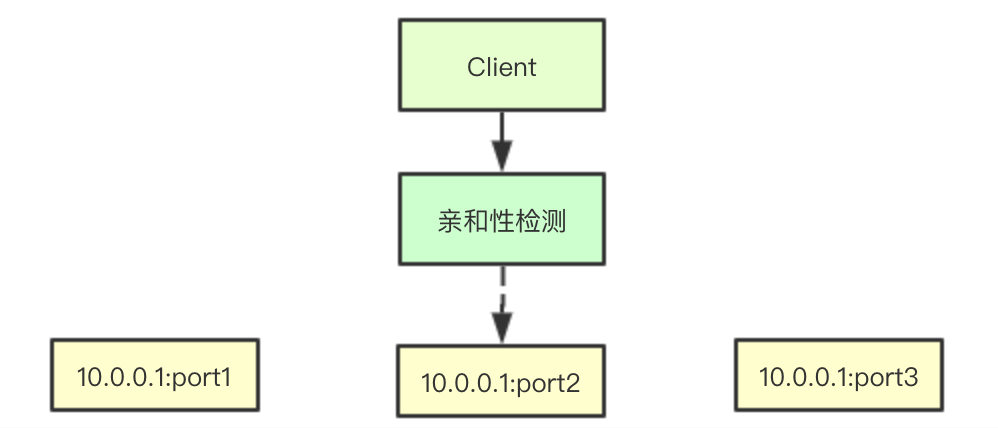 亲和性实现上也相对简单,所谓亲和性其实就是当某个IP重复调用后端某个服务,则将其转发到之前转发的机器上即可
亲和性实现上也相对简单,所谓亲和性其实就是当某个IP重复调用后端某个服务,则将其转发到之前转发的机器上即可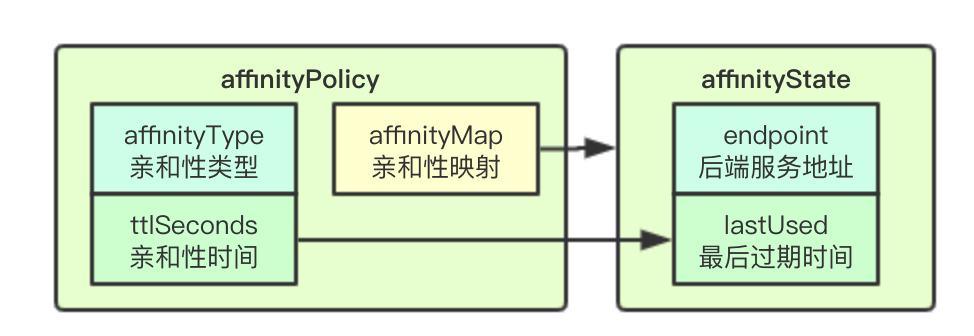
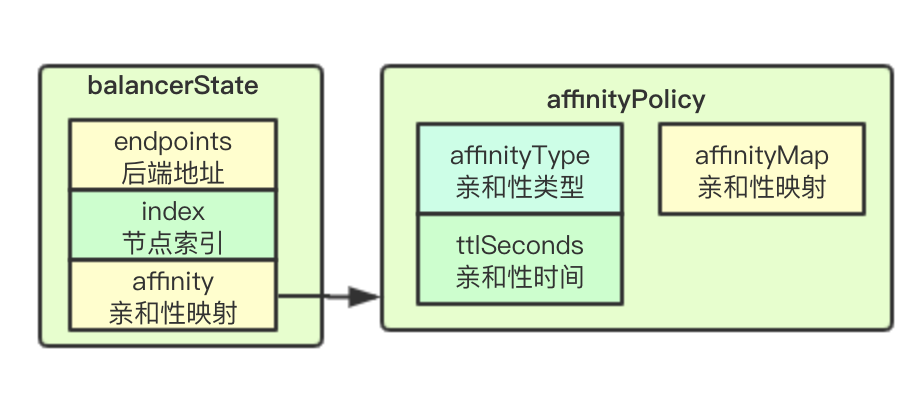 balancerState存储当前Service的负载均衡状态数据,其中endpoints存储后端pod的ip:port集合, index则是实现RR轮询算法的节点索引, affinity存储对应的亲和性策略数据
balancerState存储当前Service的负载均衡状态数据,其中endpoints存储后端pod的ip:port集合, index则是实现RR轮询算法的节点索引, affinity存储对应的亲和性策略数据 核心数据结构主要通过services字段来保存服务对应的负载均衡状态,并通过读写锁来进行service map进行保护
核心数据结构主要通过services字段来保存服务对应的负载均衡状态,并通过读写锁来进行service map进行保护 > 关注公告号阅读更多源码分析文章
> 关注公告号阅读更多源码分析文章  > 更多文章关注
> 更多文章关注 