背景
自2003年Google的三大核心技术GFS(03)、MapReduce(04)、和BigTable(06)的论文陆续发表至今,以Hadoop为代表的大数据处理框架,开始登上历史的舞台,迎来了一个黄金时代。Apache Hadoop是其中最为成功的开源项目,让企业级的大数据处理能力变得唾手可得。围绕Hadoop的学术研究和工业界的探索在过去的十多年里一直保持着火热。
而在另一条时间线上,容器技术在Docker问世后,终于等来了快速发展的6年。与此同时,Kubernetes作为容器编排的开源系统,在过去几年经过一番混战,并借助CNCF社区的推动以及云原生的兴起,也很快成为了业界容器编排的事实标准。如今,几乎所有的云厂商都有一套围绕Kubernetes的容器生态,例如我们阿里云就有ACK、ASK(Serverless Kubernetes)、EDAS、以及ECI(阿里云弹性容器实例)。

Data from Google Trends
ASF (Apache Software Foundation) 和CNCF(Cloud Native Computing Foundation),两大相对独立的阵营悄然步入到了一个历史的拐点,我们都期待他们之间会碰撞出怎样的火花。显然,Spark2.3.0 开始尝试原生支持on Kubernetes就是一个重要的时间节点。本文就是主要分享最近调研Spark on Kubernetes的一些总结。
从Hadoop说起
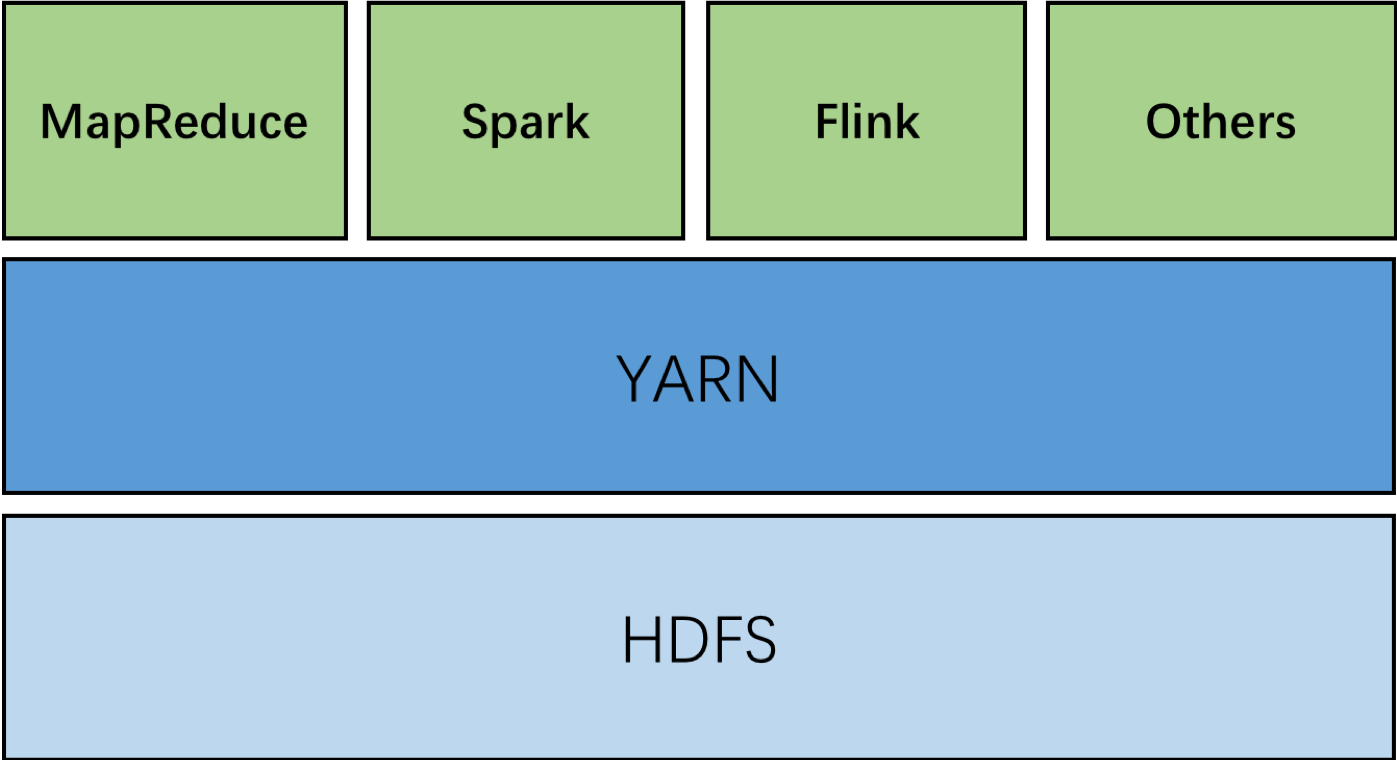
Hadoop主要包含以下两个部分:Hadoop Distributed File System (HDFS) 和一个分布式计算引擎,该引擎就是Google的 MapReduce思想的一个实现 。Hadoop一度成为了大规模分布式数据存储和处理的标椎。
Hadoop to Spark
Hadoop在被业界广泛使用的同时,也一直存在很多的问题:
1、只支持Map和Reduce算子,复杂的算法、业务逻辑很难表达,最终只能将逻辑写入算子里面,除了代码不宜维护,还导致调度上没有任何优化空间,只能根据任务数单一纬度来调度。
2、计算的中间结果也要存入HDFS,不必要的IO开销。
3、 TaskTracker 将资源划分为map slot和reduce slot,不够灵活,当缺少某个stage的时候会严重降低资源利用率。
4、…
关于Hadoop的研究也基本是围绕资源调度、MapReduce计算模式、HDFS存储、以及通用性等方面的优化,Spark便是众多衍生系统中最成功的一个。甚至可以说是里程碑级别的,从此关于Hadoop的研究沉寂了很多。2009年由加州大学伯克利分校的AMPLab开发的Spark问世,便很快成为Apache的顶级开源项目。Apache Spark 是一个基于内存计算、支持远比MapReduce复杂算子、涵盖批流等多种场景的大数据处理框架。

Spark 模块关系图
梳理下Spark中一些主要的概念:
- Application:Spark Application的概念和Hadoop中的 MapReduce类似,指的是用户编写的 Spark 应用程序,相比于Hadoop支持更丰富的算子,而且利用内建的各种库可以很方便开发机器学习、图计算等领域的应用。
- Job:由大量的Task组成的并行计算作业,一个作业通常包含一批RDD及作用于相应RDD上的各种算子。
- Stage:每个作业都会被拆分成很多组Task,每组Task即为一个TaskSet,也被称为Stage,一个作业分为多个Stage。
- Task: 被指定到某个Executor上的执行的任务,Task可以理解为一段逻辑,等待被调度到Excutor的某个线程中执行。
- Operations:即算子,分为1)Action,比如:reduce、collect、count等;2)Transformation,比如:map、join、reduceByKey等。Action会将整个作业切割成多个Stage。
- Executor:Application运行在Worker节点上的一个进程,该进程负责运行Task,每个Application都有各自的一批Executor。Executor的数量可以静态设定好,也可以采用动态资源分配。
- Driver:Spark中的Driver根据提交的Application创建SparkContext,即准备程序的运行环境。SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配等;当所有Executor全部执行完毕后,Driver负责将SparkContext关闭。
- Worker:集群中任何可以运行Application任务的节点。
- Cluster Manager:集群中调度资源的服务。Standalone模式下为Master;Yarn模式下为Yarn中的ResourceManager。
Hadoop to YARN
早期的Hadoop大规模集群也可以达到几千个节点,当数据处理需求不断增长的时候,粗暴的增加节点已经让原生调度系统非常吃力。Application管理和Resource管理的逻辑全部放在Hadoop的 JobTracker中,而 JobTracker又不具备横向扩展的能力,这让JobTracker不负重堪。需要一套方案能将Application管理和Resource管理职责分开,能将计算模式和 JobTracker解耦,YARN就是在这样的背景下诞生的。如今我们常听到的Hadoop其实已经是指Yarn了。
Yarn 在集群的角色

Yarn 模块关系图
Spark调度在最初设计的时候,就是开放式的,而且调度模块之间的关系跟YARN的概念非常吻合。
Spark Master和ResourceManager对应,Spark Worker和NodeManager对应,Spark Driver和Application Master对应,Spark Executor和Container对应。每个Executor能并行运行Task的数量就取决于分配给它的Container的CPU核数。
Client提交一个应用给 Yarn ResourceManager后, Application Manager接受请求并找到一个Container创建该应用对应的Application Master,Application Master会向ResourceManager注册自己,以便client访问。Application Master上运行的就是Spark Driver。Application Master申请 Container并启动,Spark Driver然后在Container里启动 Spark Executor,并调度Spark Task到Spark Executor上的线程执行。等到所有的Task执行完毕后,Application Master取消注册并释放资源。
带来的好处
1、YARN作为集群统一的资源调度和应用管理层,降低了资源管理的复杂性的同时,对所有应用类型都是开放的,即支持混部MapReduce、Spark等,能提高整个集群的资源利用率。
2、两级调度方式,大大降低了ResourceManager的压力,增加了集群的扩展能力。
3、计算模式和资源调度解耦。在调度层,屏蔽了MapReduce、Spark、Flink等框架的计算模式的差异,让这些框架都只用专注于计算性能的优化。
4、可以使用YARN的高级功能,比如:1)原生FIFO之外的调度策略: CapacityScheduler & FairScheduler;2)基于队列的资源隔离与分配等。
YARN to Kubernetes
Hadoop和Spark能成为现在使用最广泛的大数据处理框架,离不开Yarn的强大。虽然也有人诟病它的悲观锁导致并发粒度小、二层调度资源可见性等问题,但是除此之外,Yarn就本身来说并没有什么大的缺陷,依然是大数据领域的调度底座的首选。历史往往就是如此,霸主都不是被对手干到,而是被那些一开始看似其他领域的新兴力量淘汰。这就是如今谷歌主导的kubernetes生态发展到一定的程度之后,Yarn必然要去面对的挑战:如果未来,一家公司80%的业务都已经统一在Kubernetes上跑,它还会原意为剩下的20%的大数据的业务单独维护一个Yarn集群么?
Kubernetes的优势
Spark on kubernetes相比于on YARN等传统部署方式的优势:
1、统一的资源管理。不论是什么类型的作业都可以在一个统一kubernetes的集群运行。不再需要单独为大数据作业维护一个独立的YARN集群。
2、弹性的集群基础设施。资源层和应用层提供了丰富的弹性策略,我们可以根据应用负载需求选择 ECS 虚拟机、神龙裸金属和 GPU 实例进行扩容,除了kubernetes集群本生具备的强大的扩缩容能力,还可以对接生态,比如virtual kubelet。
3、轻松实现复杂的分布式应用的资源隔离和限制,从YRAN复杂的队列管理和队列分配中解脱。
4、容器化的优势。每个应用都可以通过docker镜像打包自己的依赖,运行在独立的环境,甚至包括Spark的版本,所有的应用之间都是隔离的。
5、大数据上云。目前大数据应用上云常见的方式有两种:1)用ECS自建YARN(不限于YARN)集群;2)购买EMR服务。如今多了一个选择——Kubernetes。既能获得完全的集群级别的掌控,又能从复杂的集群管理、运维中解脱,还能享受云所带来的弹性和成本优势。
Spark自2.3.0开始试验性支持Standalone、on YARN以及on Mesos之外的新的部署方式:Running Spark on Kubernetes ,并在后续的发行版中不断地加强。
后文将是实际的操作,分别让Spark应用在普通的Kubernetes集群、Serverless Kubernetes集群、以及Kubernetes + virtual kubelet等三种场景中部署并运行。
Spark on Kubernetes
准备数据以及Spark应用镜像
参考:
在ECI中访问HDFS的数据
在ECI中访问OSS的数据
创建kubernetes集群
如果已经有阿里云的ACK集群,该步可以忽略。
具体的创建流程参考:创建Kubernetes 托管版集群。
提交作业
为Spark创建一个RBAC的role
创建账号(默认namespace)
kubectl create serviceaccount spark
绑定角色
kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
直接使用spark-submit提交(不推荐的提交方式)
liumihustdeMacBook-Pro:spark-on-k8s liumihust$ ./spark-2.3.0-bin-hadoop2.6/bin/spark-submit
--master k8s://121.199.47.XX:6443
--deploy-mode cluster
--name WordCount
--class com.aliyun.liumi.spark.example.WordCount
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark
--conf spark.executor.instances=2
--conf spark.kubernetes.container.image=registry.cn-beijing.aliyuncs.com/liumi/spark:2.4.4-example
local:///opt/spark/jars/SparkExampleJava-1.0-SNAPSHOT.jar
参数解释
--master :k8s集群的apiserver,这是决定spark是在k8s集群跑,还是在yarn上跑。
--deploy-mode:driver可以部署在集群的master节点(client)也可以在非master(cluster)节点。
spark.executor.instances: executor的数量
spark.kubernetes.container.image spark打包镜像(包含driver、excutor、应用,也支持单独配置)
提交基本流程

Running Spark on Kubernetes
- Spark先在k8s集群中创建Spark Driver(pod)。
- Driver起来后,调用k8s API创建Executors(pods),Executors才是执行作业的载体。
- 作业计算结束,Executor Pods会被自动回收,Driver Pod处于Completed状态(终态)。可以供用户查看日志等。
- Driver Pod只能被用户手动清理,或者被k8s GC回收。
结果分析
执行过程中的截图如下:

我们30G的数据用2个1C1G的Excutor处理了大约20分钟。
作业运行结束后查看结果:
[root@liumi-hdfs ~]# $HADOOP_HOME/bin/hadoop fs -cat /pod/data/A-Game-of-Thrones-Result/*
(142400000,the)
(78400000,and)
(77120000,)
(62200000,to)
(56690000,of)
(56120000,a)
(43540000,his)
(35160000,was)
(30480000,he)
(29060000,in)
(26640000,had)
(26200000,her)
(23050000,as)
(22210000,with)
(20450000,The)
(19260000,you)
(18300000,I)
(17510000,she)
(16960000,that)
(16450000,He)
(16090000,not)
(15980000,it)
(15080000,at)
(14710000,for)
(14410000,on)
(12660000,but)
(12470000,him)
(12070000,is)
(11240000,from)
(10300000,my)
(10280000,have)
(10010000,were)
至此,已经能在kubernetes集群部署并运行spark作业。
Spark on Serverless Kubernetes
Serverless Kubernetes (ASK) 相比于普通的kubernetes集群,比较大的一个优势是,提交作业前无需提前预留任何资源,无需关心集群的扩缩容,所有资源都是随作业提交自动开始申请,作业执行结束后自动释放。作业执行完后就只剩一个SparkApplication和终态的Driver pod(只保留管控数据)。原理图如下图所示:

Running Spark on Serverless Kubernetes
ASK通过virtual kubelet调度pod到阿里云弹性容器实例。虽然架构上跟ACK有明显的差异,但是两者都是全面兼容kubernetes标准的。所以on ASK跟前面的spark on kubernetes准备阶段的基本是一致的,即HDFS数据准备,spark base镜像的准备、spark应用镜像的准备等。主要就是作业提交方式稍有不同,以及一些额外的基本环境配置。
创建serverless kubernetes集群
选择标准serverless集群:

基本参数:
1、自定义集群名。
2、选择地域、以及可用区。
3、专有网络可以用已有的也可以由容器服务自动创建的。
4、是否公网暴露API server,如有需求建议开启。
5、开启privatezone,必须开启。
6、日志收集,建议开启。

注:
1、提交之前一定要升级集群的集群的virtual kubelet的版本(新建的集群可以忽略),只有目前最新版的VK才能跑Spark作业。
2、ASK集群依赖privatezone做服务发现,所以集群不需要开启privatezone,创建的时候需要勾选。如果创建的时候没有勾选,需要联系我们帮开启。不然Spark excutor会找不到driver service。
*制作镜像cache
由于后面可能要进行大规模启动,为了提高容器启动速度,提前将Spark应用的镜像缓存到ECI本地,采用k8s标准的CRD的方式,具体的流程参考:使用CRD加速创建Pod
提交:
由于spark submit目前支持的参数非常有限,所以ASK场景中不建议使用spark submit直接提交,而是使用Spark Operator 。在Spark Operator出现之前,也可以采用kubernetes原生的yaml方式提交。后面会分别介绍这两种不同的方式。
方式一:原生的方式,编写yaml
编写自定义的标准的kubernetes yaml创建资源。
我所测试的完整的yaml文件如下(基于Spark 2.3.0):
wordcount-spark-driver-svc.yaml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark-serverless
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: spark-serverless-role
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: edit
subjects:
- kind: ServiceAccount
name: spark-serverless
namespace: default
---
apiVersion: v1
kind: Service
metadata:
name: wordcount-spark-driver-svc
namespace: default
annotations:
service.beta.kubernetes.io/alibaba-cloud-private-zone-enable: "true"
spec:
clusterIP: None
ports:
- name: driver-rpc-port
port: 7078
protocol: TCP
targetPort: 7078
- name: blockmanager
port: 7079
protocol: TCP
targetPort: 7079
selector:
spark-app-selector: spark-9b7952456a86413b94c70fe2b3f8496c
spark-role: driver
sessionAffinity: None
type: ClusterIP
---
apiVersion: v1
kind: Pod
metadata:
annotations:
spark-app-name: WordCount
k8s.aliyun.com/eci-image-cache: "true"
labels:
spark-app-selector: spark-9b7952456a86413b94c70fe2b3f8496c
spark-role: driver
name: wordcount-spark-driver
namespace: default
spec:
containers:
- args:
- driver
env:
- name: SPARK_DRIVER_MEMORY
value: 1g
- name: SPARK_DRIVER_CLASS
value: com.aliyun.liumi.spark.example.WordCount
- name: SPARK_DRIVER_ARGS
- name: SPARK_DRIVER_BIND_ADDRESS
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: SPARK_MOUNTED_CLASSPATH
value: >-
/opt/spark/jars/SparkExampleJava-1.0-SNAPSHOT.jar:/opt/spark/jars/SparkExampleJava-1.0-SNAPSHOT.jar
- name: SPARK_JAVA_OPT_0
value: '-Dspark.submit.deployMode=cluster'
- name: SPARK_JAVA_OPT_1
value: '-Dspark.driver.blockManager.port=7079'
- name: SPARK_JAVA_OPT_2
value: '-Dspark.master=k8s://https://47.99.132.xxx:6443'
- name: SPARK_JAVA_OPT_3
value: '-Dspark.app.id=spark-9b7952456a86413b94c70fe2b3f8496c'
- name: SPARK_JAVA_OPT_4
value: '-Dspark.kubernetes.authenticate.driver.serviceAccountName=spark'
- name: SPARK_JAVA_OPT_5
value: >-
-Dspark.kubernetes.driver.pod.name=wordcount-spark-driver
- name: SPARK_JAVA_OPT_6
value: '-Dspark.app.name=WordCount'
- name: SPARK_JAVA_OPT_7
value: >-
-Dspark.kubernetes.container.image=registry.cn-beijing.aliyuncs.com/liumi/spark:2.3.0-hdfs-1.0
- name: SPARK_JAVA_OPT_8
value: '-Dspark.executor.instances=10'
- name: SPARK_JAVA_OPT_9
value: >-
-Dspark.jars=/opt/spark/jars/SparkExampleJava-1.0-SNAPSHOT.jar,/opt/spark/jars/SparkExampleJava-1.0-SNAPSHOT.jar
- name: SPARK_JAVA_OPT_10
value: >-
-Dspark.driver.host=wordcount-spark-driver-svc.default.svc.cluster.local.c132a4a4826814d579c14bf2c5cf933af
- name: SPARK_JAVA_OPT_11
value: >-
-Dspark.kubernetes.executor.podNamePrefix=wordcount-spark
- name: SPARK_JAVA_OPT_12
value: '-Dspark.driver.port=7078'
- name: SPARK_JAVA_OPT_13
value: >-
-Dspark.kubernetes.executor.annotation.k8s.aliyun.com/eci-image-cache=true
- name: SPARK_JAVA_OPT_14
value: >-
-Dspark.kubernetes.allocation.batch.size=10
image: 'registry.cn-beijing.aliyuncs.com/liumi/spark:2.3.0-hdfs-1.0'
imagePullPolicy: IfNotPresent
name: spark-kubernetes-driver
resources:
limits:
memory: 16384Mi
requests:
cpu: '8'
memory: 16Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: None
dnsConfig:
nameservers:
- 100.100.2.136
- 100.100.2.138
searches:
- default.svc.cluster.local.c132a4a4826814d579c14bf2c5cf933af
- svc.cluster.local.c132a4a4826814d579c14bf2c5cf933af
- cluster.local.c132a4a4826814d579c14bf2c5cf933af
- c132a4a4826814d579c14bf2c5cf933af
options:
- name: ndots
value: "5"
hostAliases:
- ip: "47.99.132.xxx"
hostnames:
- "kubernetes.default.svc"
priority: 0
restartPolicy: Never
serviceAccount: spark-serverless
serviceAccountName: spark-serverless
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
yaml文件里定义了四个资源:
ServiceAccount:spark-serverless,Driver需要在pod里面访问集群的api server,所以需要创建一个ServiceAccount。不用每次提交都创建。
ClusterRoleBinding:spark-serverless-role,将RBAC的role绑定到这个ServiceAccount,赋予操作资源的权限。不用每次提交都创建。
Service:Driver service,暴露Driver pod。Excutor 就是通过这个service访问Driver的。
Pod:Driver pod,不用定义Excutor pod yaml,Excutor pod的参数通过Driver的环境变量来设置Dspark.kubernetes.*实现。
kubectl 提交:
liumihustdeMacBook-Pro:spark-on-k8s liumihust$ kubectl create -f wordcount-spark-driver-svc.yaml
serviceaccount/spark-serverless created
clusterrolebinding.rbac.authorization.k8s.io/spark-serverless-role created
service/wordcount-spark-driver-svc created
pod/wordcount-spark-driver created
方式二:Spark Operator
前面直接通过k8s yaml申明的方式,也能直接利用kubernetes的原生调度来跑Spark的作业,在任何集群只要稍加修改就可以用,但问题是:1)不好维护,涉及的自定义参数比较多,且不够直观(尤其对于只熟悉Spark的用户);2)没有了Spark Application的概念了,都是裸的pod和service,当应用多的时候,维护成本就上来了,缺少统一管理的机制。
Spark Operator 就是为了解决在Kubernetes集群部署并维护Spark应用而开发的,Spark Operator是经典的CRD + Controller,即Kubernetes Operator的实现。Kubernetes Operator诞生的故事也很具有传奇色彩,有兴趣的同学可以了解下 。Operator的出现可以说给有状态的、特定领域的复杂应用 on Kubernetes 打开了一扇窗,Spark Operator便是其中具有代表性的一个。

Spark Operator几个主要的概念:
SparkApplication:标准的k8s CRD,有CRD就有一个Controller 与之对应。Controller负责监听CRD的创建、更新、以及删除等事件,并作出对应的Action。
ScheduledSparkApplication:SparkApplication的升级,支持带有自定义时间调度策略的作业提交,比如cron。
Submission runner:对Controller发起的创建请求提交spark-submit。
Spark pod monitor:监听Spark pods的状态和事件更新并告知Controller。
安装Spark Operator
推荐用 helm 3.0
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
helm install incubator/sparkoperator --namespace default --set operatorImageName=registry.cn-hangzhou.aliyuncs.com/eci_open/spark-operator --set operatorVersion=v1beta2-1.0.1-2.4.4 --generate-name --set enableWebhook=true
安装完成后可以看到集群多了个spark operator pod。

选项说明:
1、--set operatorImageName:指定operator镜像,默认的google的镜像阿里云ECI内拉不下来,可以先拉取到本地然后推到ACR。
2、--set operatorVersion operator:镜像仓库名和版本不要写在一起。
3、--generate-name 可以不用显式设置安装名。
4、--set enableWebhook 默认不会打开,对于需要使用ACK+ECI的用户,会用到nodeSelector、tolerations这些高级特性,Webhook 必须要打开,后面会讲到。
注:
创建spark operator的时候,一定要确保镜像能拉下来,推荐直接使用eci_open提供的镜像,因为spark operator卸载的时候也是用相同的镜像启动job进行清理,如果镜像拉不下来清理job也会卡主,导致所有的资源都要手动清理,比较麻烦。
申明wordcount SparkApplication:
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: wordcount
namespace: default
spec:
type: Java
mode: cluster
image: "registry.cn-beijing.aliyuncs.com/liumi/spark:2.4.4-example"
imagePullPolicy: IfNotPresent
mainClass: com.aliyun.liumi.spark.example.WordCount
mainApplicationFile: "local:///opt/spark/jars/SparkExampleJava-1.0-SNAPSHOT.jar"
sparkVersion: "2.4.4"
restartPolicy:
type: OnFailure
onFailureRetries: 2
onFailureRetryInterval: 5
onSubmissionFailureRetries: 2
onSubmissionFailureRetryInterval: 10
timeToLiveSeconds: 36000
sparkConf:
"spark.kubernetes.allocation.batch.size": "10"
driver:
cores: 2
memory: "4096m"
labels:
version: 2.4.4
spark-app: spark-wordcount
role: driver
annotations:
k8s.aliyun.com/eci-image-cache: "true"
serviceAccount: spark
executor:
cores: 1
instances: 100
memory: "1024m"
labels:
version: 2.4.4
role: executor
annotations:
k8s.aliyun.com/eci-image-cache: "true"
注:大部分的参数都可以直接通过SparkApplication CRD已经支持的参数设置,目前支持的所有参数参考:SparkApplication CRD,此外还支持直接以sparkConf形式的传入。
提交:
kubectl create -f wordcount-operator-example.yaml
结果分析
我们是100个1C1G的Excutor并发启动,应用的镜像大小约为 500 MB。
作业执行过程截图:


可以看到并发启动的100个pod基本在30s内可以完成全部的启动,其中93%可以在20秒内完成启动。
看下作业执行时间(包括了vk调度100个Excutor pod时间、每个Excutor pod资源准备的时间、以及作业实际执行的时间等):
exitCode: 0
finishedAt: '2019-11-16T07:31:59Z'
reason: Completed
startedAt: '2019-11-16T07:29:01Z'
可以看到总共只花了178S,时间降了一个数量级。
ACK + ECI
在Spark中,Driver和Excutor之间的启动顺序是串行的。尽管ECI展现了出色的并发创建Executor pod的能力,但是ASK这种特殊架构会让Driver和Excutor之间的这种串行体现的比较明显,通常情况下在ECI启动一个Driver pod需要大约20s的时间,然后才是大规模的Excutor pod的启动。对于一些响应要求高的应用,Driver的启动速度可能比Excutor执行作业的耗时更重要。这个时候,我们可以采用ACK+ECI,即传统的Kubernetes集群 + virtual kubelet的方式:

对于用户来说,只需如下简单的几步就可以将excutor调度到ECI的virtual node。
1、在ACK集群中安装ECI的virtual kubelet。
进入容器服务控制台的应用目录栏,搜索"ack-virtual-node":

点击进入,选择要安装的集群。

必填参数参考:
virtualNode:
image:
repository: registry.cn-hangzhou.aliyuncs.com/acs/virtual-nodes-eci
tag: v1.0.0.1-aliyun
affinityAdminssion:
enabled: true
image:
repository: registry.cn-hangzhou.aliyuncs.com/ask/virtual-node-affinity-admission-controller
tag: latest
env:
ECI_REGION: "cn-hangzhou" #集群所在的地域
ECI_VPC: vpc-bp187fy2e7l123456 # 集群所在的vpc,和创建集群的时候保持一致即可,可以在集群概览页查看
ECI_VSWITCH: vsw-bp1bqf53ba123456 # 资源所在的交换机,同上
ECI_SECURITY_GROUP: sg-bp12ujq5zp12346 # 资源所在的安全组,同上
ECI_ACCESS_KEY: XXXXX #账号AK
ECI_SECRET_KEY: XXXXX #账号SK
ALIYUN_CLUSTERID: virtual-kubelet
2、修改应用的yaml
为excutor增加如下参数即可:
nodeSelector:
type: virtual-kubelet
tolerations:
- key: virtual-kubelet.io/provider
operator: Exists
完整的应用参数如下:
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: wordcount
namespace: default
spec:
type: Java
mode: cluster
image: "registry.cn-beijing.aliyuncs.com/liumi/spark:2.4.4-example"
imagePullPolicy: IfNotPresent
mainClass: com.aliyun.liumi.spark.example.WordCount
mainApplicationFile: "local:///opt/spark/jars/SparkExampleJava-1.0-SNAPSHOT.jar"
sparkVersion: "2.4.4"
restartPolicy:
type: OnFailure
onFailureRetries: 2
onFailureRetryInterval: 5
onSubmissionFailureRetries: 2
onSubmissionFailureRetryInterval: 10
timeToLiveSeconds: 36000
sparkConf:
"spark.kubernetes.allocation.batch.size": "10"
driver:
cores: 2
memory: "4096m"
labels:
version: 2.4.4
spark-app: spark-wordcount
role: driver
annotations:
k8s.aliyun.com/eci-image-cache: "true"
serviceAccount: spark
executor:
cores: 1
instances: 100
memory: "1024m"
labels:
version: 2.4.4
role: executor
annotations:
k8s.aliyun.com/eci-image-cache: "true"
#nodeName: virtual-kubelet
nodeSelector:
type: virtual-kubelet
tolerations:
- key: virtual-kubelet.io/provider
operator: Exists
这样就可以将Driver调度到ACK,Excutor调度到ECI上,完美互补。
3、提交
效果如下:

看下作业执行时间:
exitCode: 0
finishedAt: '2019-11-16T07:25:05Z'
reason: Completed
startedAt: '2019-11-16T07:22:40Z'
总共花了145秒,更重要的是Driver直接在本地起,只花了约2秒的时间就启动了。
总结:
作业执行时间不是Kubernetes + ECI的绝对优势,如果在ACK上准备好足够的节点资源,也是可以达到这个水平的。
我们的优势是:
1)弹性和成本
对于不管是采用ACK + ECI还是ASK+ECI的方式,提交作业前无需提前预留任何资源,无需关心集群的扩缩容,所有资源都是随作业提交自动开始申请,作业执行结束后自动释放。作业执行完后就只剩一个SparkApplication和终态的Driver pod(只保留管控数据)。除此之外,ACK + ECI的方式还提供了更丰富的调度选择:1)可以将Driver和Excutor分开调度;2)考虑作业类型、成本等因素选择不同的调度资源,以满足更广泛的使用场景。
2)计算与存储分离
在Kubernetes中跑大数据一直很困扰的问题就是数据存储的问题,到了Serverless kubernetes这个问题就更突出。我们连节点都没有,就更不可能去搭建HDFS/Yarn集群。而事实上,在HDFS集群上跑Spark,已经不是必需的了,见引用[1, 2]。阿里云的HDFS存储也正解了我们这个痛点问题,经测试读写性能也非常不错。我们可以将计算和存储分离,即kubernetes集群中的作业可以直接原生访问HDFS的数据。除了HDFS,阿里云的NAS和OSS也是可选的数据存储。
3)调度
调度通常可以分为以YARN为代表的两级调度和集中式调度。两级调度有一个中央调度器负责宏观层面的资源调度,而应用的细粒度调度则由下层调度器来完成。集中式调度则对所有的资源请求进行统一调度,Kubernetes的调度就是典型的代表,Kubernetes通过将整个集群的资源信息缓存到本地,利用本地的数据进行乐观调度,进而提高调度器的性能。
当前kubernetes集群的达到一定规模的时候,性能会到达瓶颈,引用[3]。YARN可以说是历经了大数据领域多年锤炼的成果,采用kubernetes原生调度器来调度Spark作业能否hold住还是一个问号。
而对于Serverless Kubernetes,就变成了类两级调度:对于kubernetes来说调度其实进行了极大的简化,调度器只用将资源统一调度到virtual kubelet,而实际的细粒度调度就下沉到了阿里云强大的弹性计算的调度。
当处理的数据量越大,突发启动Excutor pod规模越大的时候,我们的优势会越明显。
参考
[1] HDFS vs. Cloud Storage: Pros, cons and migration tips
[2] New release of Cloud Storage Connector for Hadoop: Improving performance, throughput and more
[3] Understanding Scalability and Performance in the Kubernetes Master , Xingyu Chen, Fansong Zeng Alibaba Cloud
附录
Spark Base 镜像:
本样例采用的是谷歌提供的 gcr.io/spark-operator/spark:v2.4.4
ECI已经帮拉取到ACR仓库,各地域地址如下:
公网地址:registry.{对应regionId}.aliyuncs.com/eci_open/spark:2.4.4
vpc网络地址:registry-vpc.{对应regionId}.aliyuncs.com/eci_open/spark:2.4.4
Spark Operator 镜像
本样例采用的是谷歌提供的 gcr.io/spark-operator/spark-operator:v1beta2-1.0.1-2.4.4
ECI已经帮拉取到ACR仓库,各地域地址如下:
公网地址:registry.{对应regionId}.aliyuncs.com/eci_open/spark-operator:v1beta2-1.0.1-2.4.4
vpc网络地址:registry-vpc.{对应regionId}.aliyuncs.com/eci_open/spark-operator:v1beta2-1.0.1-2.4.4