ThreadLocal介绍
ThreadLocal是JDK1.2提供的,作用是给单个线程内的共享变量提供载具。每个线程之间的ThreadLocal里的数据是相互隔离的,并随着线程的消亡而消亡。
使用
ThreadLocal提供了get(),set(T value),remove()3个对外方法。
- 1.调用get()获取值
- 2.调用set(T value)设置值
- 3.调用remove()删除值
使用中的坑
ThreadLocal常被用来做登入状态信息的存储。但是如果当前线程操作完不对状态信息做remove()可能会出现坑。我们拿购买商品举个例子:
-
- A用户已经登入,请求购买
-
- ThreadLocal存储A用户信息。
-
- 获取ThreadLocal里A用户信息调用去请求购买接口,并返回成功。
-
- A用户线程未被系统回收,待重复利用。
-
- B用户也发起请求购买请求,并重用了A用户使用过的线程,此时B用户并未登入,所以跳过ThreadLocal存储B用户信息的逻辑。
-
- 正常情况下B用户会返回需要登入的提示,但此时ThreadLocal存储A用户信息并未被清除,获取A用户信息并调用去请求购买接口,并返回成功。
可以看到B用户使用了A用户的信息去购买了商品,正确的做法应该是每个线程使用结束后去remove()。
ThreadLocal原理
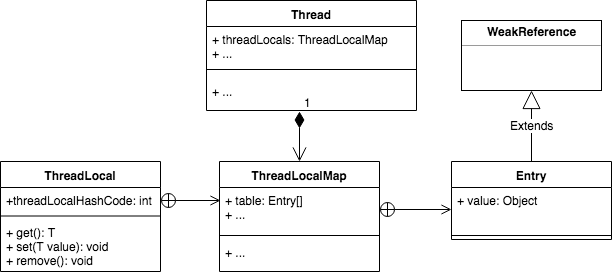
ThreadLocal的UML图如下
![]()
调用set方法真正的数据是存在ThreadLocalMap里的,而ThreadLocalMap是线程Thread的成员变量,所以说线程Thread被jvm回收后ThreadLocalMap也会被回收。ThreadLocalMap的实现是采用顺序存储结构哈希表,它跟HashMap不同,每个hash地址只能存一个数据。它key存的是ThreadLocal本身而且它的Entry继承至WeakReference,所以它的key如果没被强引用会在GC的触发的时候回收掉。
set(T value)源码分析
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//根据当前线程获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//如果map不为空设置值
if (map != null)
map.set(this, value);
//如果map为空说明线程中成员变量ThreadLocalMap还没被创建,则创建map
else
createMap(t, value);
}
这个方法主要根据当前线程获取ThreadLocalMap,如果还没初始化则调用createMap(t, value)初始化,反之调用map.set(this, value)设置值。
下面看下getMap(t)的实现
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
很简单就是获取Thread的成员变量threadLocals
先来看下map为空调用createMap(t, value)去创建ThreadLocalMap的情况:
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
createMap(t, value)直接是new的ThreadLocalMap,ThreadLocalMap构造方法如下:
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
//1.创建和初始化table容量
table = new Entry[INITIAL_CAPACITY];
//2.快速hash获取下标地址
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//3.创建Entry,存放第一个数据
table[i] = new Entry(firstKey, firstValue);
//4.设置存储个数
size = 1;
//5.设置扩容阀值
setThreshold(INITIAL_CAPACITY);
}
- 1.先创建和初始化table容量,table就是存放数据的容器,容器初始容量为16。
- 2.使用快速hash获取下标地址,这里看下获取firstKey.threadLocalHashCode的代码:
private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode =
new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
nextHashCode()的方法每次创建ThreadLocal都会加HASH_INCREMENT重新计算threadLocalHashCode的值,HASH_INCREMENT这个魔数的选取与斐波那契散列有关为了让哈希码能均匀的分布在2的N次方的数组里,这里指table数组。
- 3.创建Entry,存放第一个数据,这里以ThreadLocal自己本身key,Entry继承至WeakReference,代码如下:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
由于key是弱引用,所以它的key如果没被强引用会在GC的触发的时候回收掉。
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
扩容阀值的计算是容量大小的2/3是,这里结果是10。
下面看下map.set(this, value)实现
private void set(ThreadLocal<?> key, Object value) {
//调用set之前已经做过判断,所以table已经初始化了
Entry[] tab = table;
//获取tab的长度
int len = tab.length;
//1.快速hash获取下标地址
int i = key.threadLocalHashCode & (len-1);
//2.用线性探测法解决冲突
for (Entry e = tab[i];
e != null;
//取下个下标值
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
//3.如果这个key已经存在,重新设置值
if (k == key) {
e.value = value;
return;
}
//4.如果key已经过期,则替换这个脏槽
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
//5.创建Entry
tab[i] = new Entry(key, value);
//6.存储个数加1
int sz = ++size;
//7.清理key已经过期清理的脏槽,如果没脏槽并且存储个数已经大于扩容阀值,则扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
- 1.快速hash获取下标地址。
- 2.用线性探测法解决冲突,调用nextIndex(i, len)遍历table。我们看下nextIndex(i, len)的源码
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
遍历的实现其实设计了一个环,从i开始遍历到达len长度后又开始从0开始。实际上这里用线性探测法解决冲突不会到达len长度,因为在到达之前已经进行了扩容。
- 3.如果找到的这个key已经存在,重新设置值。
- 4.如果找到的key已经过期,则替换这个脏槽。
- 5.创建Entry。
- 6.存储个数加1。
- 7.清理key已经过期清理的脏槽,如果未清理到脏槽并且存储个数已经大于扩容阀值,则调用rehash()重hash。
下面来看下replaceStaleEntry(key, value, i)的源码
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
int slotToExpunge = staleSlot;
//1.向前查找,找到第一个key过期的脏槽
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
//2.从staleSlot位置开始向后查找,如果找到key,交换至staleSlot位置的脏槽
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
//找到key
if (k == key) {
//交换至staleSlot位置的脏槽
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
//如果slotToExpunge == staleSlot,说明前面没有脏槽,直接从i位置开始清理
if (slotToExpunge == staleSlot)
slotToExpunge = i;
//清理脏槽
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
//如果slotToExpunge == staleSlot,说明前面没有脏槽,直接从i位置开始清理
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
//3.如果没有找到key,则创建一个新的Entry放至staleSlot位置的脏槽
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
//4.如果运行过程中有找到脏槽,清理之
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
- 1.从staleSlot位置向前查找,找到第一个key过期的脏槽
- 2.从staleSlot位置开始向后查找,如果找到key,交换至staleSlot位置的脏槽
- 3.如果没有找到key,则创建一个新的Entry放至staleSlot位置的脏槽
- 4.如果运行过程中有找到脏槽,清理之,这里slotToExpunge != staleSlot 成立说明slotToExpunge已经改变说明找到了脏槽。
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len)的作用主要是清理脏槽expungeStaleEntry(slotToExpunge)方法作用的从slotToExpunge位置(包括slotToExpunge)开始清理临近的脏槽。
下面来看下expungeStaleEntry(slotToExpunge)的源码
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 1.清理槽
tab[staleSlot].value = null;
tab[staleSlot] = null;
//存储个数减一
size--;
// 2.重hash或清理staleSlot之后的槽,直到空值
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
//2.1如果轮询到的k为空,则清理之
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
//2.2重hash,重新设置hash已经改变的Entry的位置
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
//3.返回清理遍历的最后位置i
return i;
}
- 1.清理staleSlot位置的槽。这里清理的逻辑就是将value设置为null并将整个Entry设置为null,以便后续新Entry覆盖使用。
- 2.重hash或清理staleSlot之后的槽,直到空值。
- 2.1 如果轮询到的k为空,则清理之。
- 2.2 重hash,重新设置hash已经改变的Entry的位置。这里i地址有可能是经过线性探测解决的冲突的方式找到的地址,因为前面的槽已经被清理过所以线性探测解决的冲突方法找到的地址可能已经不是i,所以这边需要重新用线性探测解决的冲突方法查找新地址。
- 3 .返回清理遍历的最后位置i。 总结下expungeStaleEntry(slotToExpunge)逻辑其实不仅仅清理传的slotToExpunge地址的槽也会清理它临近的槽。
拿到清理遍历的最后位置i后会调用cleanSomeSlots(int i, int n)继续从i开始清理脏槽下面来看下的源码:
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
//环形遍历
i = nextIndex(i, len);
Entry e = tab[i];
//如果是脏槽,则清理之
if (e != null && e.get() == null) {
n = len;
removed = true;
//最终调用expungeStaleEntry(i)去清理
i = expungeStaleEntry(i);
}
//log2(n)清理次数
} while ( (n >>>= 1) != 0);
return removed;
}
cleanSomeSlots(int i, int n)主要功能就是从i位置开始遍历log2(n)次去清理槽,为什么是log2(n)次官方给的原因是简单,快速。所以这个方法可能不是清理所有的脏槽,而是简单快速的清理几个脏槽。
下面来看下rehash()方法
private void rehash() {
//1.清理所有的脏槽
expungeStaleEntries();
//2.如果清理过后存储个数还是大于扩容阀值的3/4,则扩容
if (size >= threshold - threshold / 4)
resize();
}
- 1.调用expungeStaleEntries()清理所有的脏槽。
- 2.如果清理过后存储个数还是大于扩容阀值的3/4,则扩容。
下面看下expungeStaleEntries()方法源码
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
代码很简单就是遍历所有的table并清理脏槽。
下面看下resize()方法源码
private void resize() {
Entry[] oldTab = table;
//获取老table容量
int oldLen = oldTab.length;
//新table容量扩大2倍
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
//遍历老的table,对所有Entry重hash定位
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
//如果遇到脏槽,清理之帮助GC
if (k == null) {
e.value = null; // Help the GC
} else {
//重hash
int h = k.threadLocalHashCode & (newLen - 1);
//线性探测法解决冲突
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
//重新计算扩容阀值
setThreshold(newLen);
//重新设置存储个数
size = count;
//重新设置table
table = newTab;
}
resize()实现也比较简单,先创建比原来大2倍的Entry数组,并遍历老的table,对所有Entry重hash定位,如果冲突就是采用线性探测法解决冲突。
get()源码分析
看下get()的源码
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//根据当前线程获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//如果不为空获取Entry
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//为空获取初始化的值
return setInitialValue();
}
这个方法主要根据当前线程获取ThreadLocalMap,如果还没初始化则调用setInitialValue()初始化并返回值,反之调用map.getEntry(this)获取值。
先来看下map不为空调用map.getEntry(this)的源码:
private Entry getEntry(ThreadLocal<?> key) {
//1.快速hash获取hash地址
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
//2.如果找到Entry,则返回
if (e != null && e.get() == key)
return e;
//3.如果未快速找到,则去遍历查找
else
return getEntryAfterMiss(key, i, e);
}
- 1.快速hash获取hash地址
- 2.如果找到Entry,则返回
- 3.如果未快速找到,则调用getEntryAfterMiss(key, i, e)去遍历查找,由于用线性探测法解决冲突,
来看下getEntryAfterMiss(key, i, e)的源码:
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
//从i位置开始遍历table
while (e != null) {
ThreadLocal<?> k = e.get();
//如果找到直接返回
if (k == key)
return e;
//如果是脏槽清理之
if (k == null)
expungeStaleEntry(i);
//获取下个地址
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
实现很简单就是从i位置开始遍历table,找到就返回Entry,遍历过程中顺便清理脏槽。
再来看下setInitialValue()的源码:
private T setInitialValue() {
//1.获取默认初始化值
T value = initialValue();
Thread t = Thread.currentThread();
//2.根据当前线程获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//3.不为空,设置值
if (map != null)
map.set(this, value);
//4.反之初始化map
else
createMap(t, value);
return value;
}
- 1.获取默认初始化值,这里initialValue()是默认返回null的,源码如下:
protected T initialValue() {
return null;
}
这个可以自己实现覆盖原来的方法。
- 2.根据当前线程获取ThreadLocalMap。
- 3.不为空,则调用map.set(this, value)设置值。
- 4.反之则调用createMap(t, value)初始化map。
remove()源码分析
直接看下remove()源码
public void remove() {
//1.根据当前线程获取ThreadLocalMap
ThreadLocalMap m = getMap(Thread.currentThread());
//2.如果map已经存在则调用m.remove(this)删除值
if (m != null)
m.remove(this);
}
- 1.根据当前线程获取ThreadLocalMap
- 2.如果map已经存在则调用m.remove(this)删除key为本身的Entry
下面来看下m.remove(this)的源码:
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
//快速hash到地址
int i = key.threadLocalHashCode & (len-1);
//向后查找
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
//如果找到
if (e.get() == key) {
//清理key
e.clear();
//清理脏槽
expungeStaleEntry(i);
return;
}
}
}
实现很简单,先快速hash到地址i,然后从这个地址i往后查找key(包括地址i)直到槽为空,如果找到则清理之。