三大函数——拷贝构造、拷贝赋值、析构函数
![]()
拷贝构造——接受的是自己这种东西
![]()
ctor和dtor构造函数和析构函数
字符串有两种:
一种是前面有一个常数,用于记录字符串的长度,此字符串的末尾没有结束符号。
另一种是字符串的末尾有结束符号,字符串的开头没有用于记录字符串长度的常数。
![]()
![]() new就是分配内存,分配了一个字符的内存。
new就是分配内存,分配了一个字符的内存。
![]() 分配了一个字符的内存,然后把结束符传进来,这样就形成了一个空字符串
分配了一个字符的内存,然后把结束符传进来,这样就形成了一个空字符串
![]() strlen是一个函数,获取字符串的长度(strlen是计算机C语言函数,计算字符串s的(unsigned int型)长度,不包括'\0'在内)你的class里面有指针,你多半是要做动态分配。所以你要在他生命结束前,调用析构函数,把内存释放掉)
strlen是一个函数,获取字符串的长度(strlen是计算机C语言函数,计算字符串s的(unsigned int型)长度,不包括'\0'在内)你的class里面有指针,你多半是要做动态分配。所以你要在他生命结束前,调用析构函数,把内存释放掉)
拷贝赋值函数
![]()
如图中的红框①②③,是要把右手里面的东西拷贝赋值给左边的步骤:
a)清空左边的东西
b)申请和右边一样大的内存空间
c)拷贝
如果没有上面那句检测自我赋值(![]() ),会出现如下情况:
),会出现如下情况:
![]()
检测是否为自我赋值,不仅仅是为了效率,还是为了安全性。
output 函数
为了打印类中的东西,我们要重载操作符 "<<",由于成员函数有默认this指针,如果将重载"<<"设置成成员函数,那么变量的位置要发生改变,这不符合人们的使用规范,因此,重载"<<"要设置成全局函数。
ostream& operator<<(ostream& os, const String& str)
{
os << str.get_c_str();
return os;
}
任何东西,只要你能直接丢给cout,你就直接丢给他输出好了。先看一下整体代码:
#ifndef __MYSTRING__
#define __MYSTRING__
class String
{
public:
String(const char* cstr=0);
String(const String& str);
String& operator=(const String& str);
~String();
char* get_c_str() const { return m_data; }
private:
char* m_data;
};
#include <cstring>
inline
String::String(const char* cstr)
{
if (cstr) {
m_data = new char[strlen(cstr)+1];
strcpy(m_data, cstr);
}
else {
m_data = new char[1];
*m_data = '\0';
}
}
inline
String::~String()
{
delete[] m_data;
}
inline
String& String::operator=(const String& str)
{
if (this == &str)
return *this;
delete[] m_data;
m_data = new char[ strlen(str.m_data) + 1 ];
strcpy(m_data, str.m_data);
return *this;
}
inline
String::String(const String& str)
{
m_data = new char[ strlen(str.m_data) + 1 ];
strcpy(m_data, str.m_data);
}
#include <iostream>
using namespace std;
ostream& operator<<(ostream& os, const String& str)
{
os << str.get_c_str();
return os;
}
#endif
注意到 get_c_str函数的返回值是char *,刚刚好可以直接给cout进行输出,因此我们写了get_c_str函数来进行输出。
堆栈与内存管理
![]()
stack object 的生命周期
![]()
static local object
![]()
global object 的生命周期
![]()
heap object 的生命期
![]()
new——先分配内存,后调用构造函数
![]()
new的动作分解:
a)调用 operator new 函数来分配内存(operator new 底层调用的是malloc)。对应的,上图分配出![]()
b)第二个动作把我们创建的变量做一个类型转换
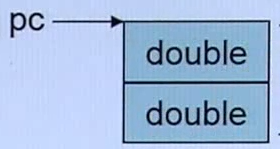
c)通过指针调用构造函数Complex(注意:构造函数在类里面,所以是成员函数,会有this指针。谁调用成员函数,this指针就指向谁。因此,上图中的第三步完整的写法应该是如图所示的形式:![]() 。
。
这里的this指针指向了pc)
delete:先调用析构函数,再释放内存
![]()
动态分配内存块 in VC
![]()
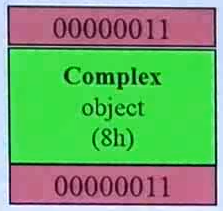
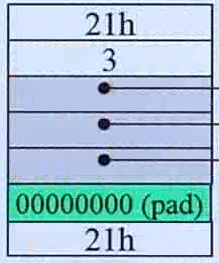
根据上图第一个矩形(debug模式下的情况):
1、new 一个复数会获得的内存是 8 byte(上图中第一个矩形草绿的部分)。
2、在调试模式下,你会得到灰色的部分,上面每一格是4byte(即![]() ),一共 4*8=32个字节。
),一共 4*8=32个字节。
3、还会得到草绿色矩形下面的那一个 4byte(即![]() )
)
4、上下两个砖红色的矩形区域是cookie
内存一共需要 8+(32+4)+(4*2)=52,而VC给你分配的内存块一定是16的倍数(现在不提为什么),因此填补了三个深绿色的填补物pad![]() 。
。
看起来分配很浪费,但是这是必要的浪费,因为回收的时候,操作系统需要依据这里的信息来进行回收。
根据上图中第二个矩形(release 模式):
分配内存8byte,加上上下cookie刚刚好16byte,因此无需调整,无需添加填补物pad。![]()
上下cookie的作用
记录整块给你的内存大小,便于系统回收,让系统知道回收多大内存。
让我们看一下cookie上记录的数字——000000041,对于第一个矩形,内存一共分配了64byte,64的16进制表示是40,而cookie上的数字是41,为什么呢?40借助最后一个bit,最后一位,标志我这块内存是给出去了还是收回来了。这里是给出去了,对于程序来说是获得了,所以最后一位标志位1,因此是41。
同理,对于第二个矩形,系统给出的内存是16byte,16的16进制是10,这里cookie上写的是11,因为这是程序获得的内存。
为什么可以借最后一个bit来标志这一块内存是给出了还是收回了?
因为分配的内存都是16的倍数,16的倍数最后四个bit都是0,我们就可以借一位来表示内存的状态。
为什么array new 要搭配 array delete
![]()
分析上图中第一个矩形(debug模型下的array new分配的内存分析)
1、复数申请的数组长度是3,因此申请了三块内存(![]() )
)
2、在调试模式下要加上那个header,上面是32下面是4(即![]() 和
和![]() )
)
3、加上向下cookIe(![]() )
)
4、在VC中(别的编译器不明),会用一个4byte的内存记录数组的长度,即图中的![]()
因此内存分配为 8*3+32+4+4*2+4=72 ,凑16的倍数,所以分配内存为80。
array new要搭配array delete
否则会造成内存泄漏。让我们看看是哪一种内存泄漏
![]()
内存泄漏的是动态分配的内存。
写不写 [],清空的内存大小是相等的,因为cookie上有记录。但是不写 [] ,编译器不知道要对每一个对象进行分别的析构。析构的时候,先分别析构各个内存对象,然后再析构母体的那个地方(![]() )。发生内存泄漏的是这里(
)。发生内存泄漏的是这里(![]() )
)
设计一个class,我总是要去思考我需要什么样的数据。由于不知道字符串的长度,所以大部分人设计字符串这种类中的数据都是在里面放一根指针,将来要分配多大的字符串内容,就动态地去分配字符串的大小,用new的方式去动态分配一块内存(在32位的平台里面,一根指针占内存是4字节,所以不管你里面字符有多长,字符串本身就4个字节的内存)
![]()
![]()
Class里面带指针,所以我要关注三个重要的函数:
拷贝构造:他是一个构造函数,所以没有返回值。他要有一个拷贝蓝本,蓝本就是他自己(传入reference是可以的,又因为我们不会改变蓝本,所以前面可以加一个const)
![]()
拷贝赋值:赋值是要把来源段的拷贝到目的端,所以涞源段的内容和拷贝构造是相同的(所以他传入的参数和拷贝构造的参数是相同的)
因为传入的值我们不打算去改变他,所以前面加一个const。
拷贝赋值的返回值(要不要return by reference,要看函数执行所返回的结果是不是放在里local object中,只要不是local object,就可以传reference)
![]()
析构函数:
![]()
辅助函数:我们希望把最后的结果丢给cout来输出到屏幕上(加了const是因为不会改变数据)
![]()
![]()
![]()
拷贝赋值函数:
涞源段拷贝到目的端,目的端是已经存在的东西,所以
第一个动作应该是把目的端的内存清空![]()
第二个动作是重新分配一块够大的空间:
![]()
第三个动作是把来源端拷贝到目的端:
![]()
接下来要思考赋值之后的返回值(如果不写返回值的话,连串的赋值行为就会受限)![]()
![]()
&str得到的是一根指针
String&是引用
进一步补充:static
谁调用我,谁就是那个this pointer,所以c的地址就是this pointer
成员函数有一个隐藏的参数this pointer,但是我们不能写进去,这个是编译器帮我们写进去
![]()
![]()
静态数据:加入了static的数据,就跟对象脱离了,他不属于对象,他在内存的某一个区域单独有一份,我们不必知道他在那里,反正后面的代码能够找得到就好了
静态函数:他的身份跟一般的成员函数字内存中是相同的,我们所指的相同指的是他也在内存中只有一份。函数在内存中当然只有一份,不可能因为你创建了好几个对象,就有好几个函数
静态函数跟一般函数的差别就在于,静态函数没有this pointer。因此静态函数如果去处理数据,他只能去处理静态的数据。
例子:
![]()
进一步补充:把ctors(构造函数)放在private区
![]()
![]()
当我们希望写的class只产生一个对象的时候,可以这么用。
把构造函数写在private里面,这样外界就无法再创建对象。
这么写有个缺陷,就是如果外界不需要这个数据,这个数据依然存在,这样会造成内存的浪费。更好的写法如下:
![]()
![]()
进一步补充:cout
为什么cout可以接受任何类型的数据,因为里面重载了很多
![]()
进一步补充:类模板
![]()
模板会造成代码的膨胀,但是这并不是缺点,因为你确实是需要这种类型的函数,即使不用模板,你也要写出来
进一步补充:function template,函数模板
类模板在用的时候要明确指出类型(![]() ),函数模板则不需要,因为编译器会做实参的推导(argument deduction)
),函数模板则不需要,因为编译器会做实参的推导(argument deduction)
![]()
进一步补充:namespace
![]()
namespace等同于你把你的东西都封锁在这个命名空间里了,这样就不会打架。
Using directive(使用命令):等同于你把封锁打开,调用的时候就用写全名(e.g std::cin)了,可以直接写cin
![]()
Using declaration:一行一行的打开,不是全开,因为里面东西可能会很多
![]()
或者是都不打开,就每一步都规规矩矩的写全名




 ),会出现如下情况:
),会出现如下情况:






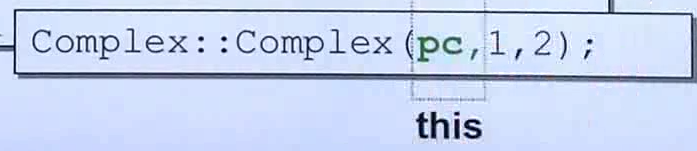 。
。

 。
。

 )
) 和
和

















 ),
),



