开始
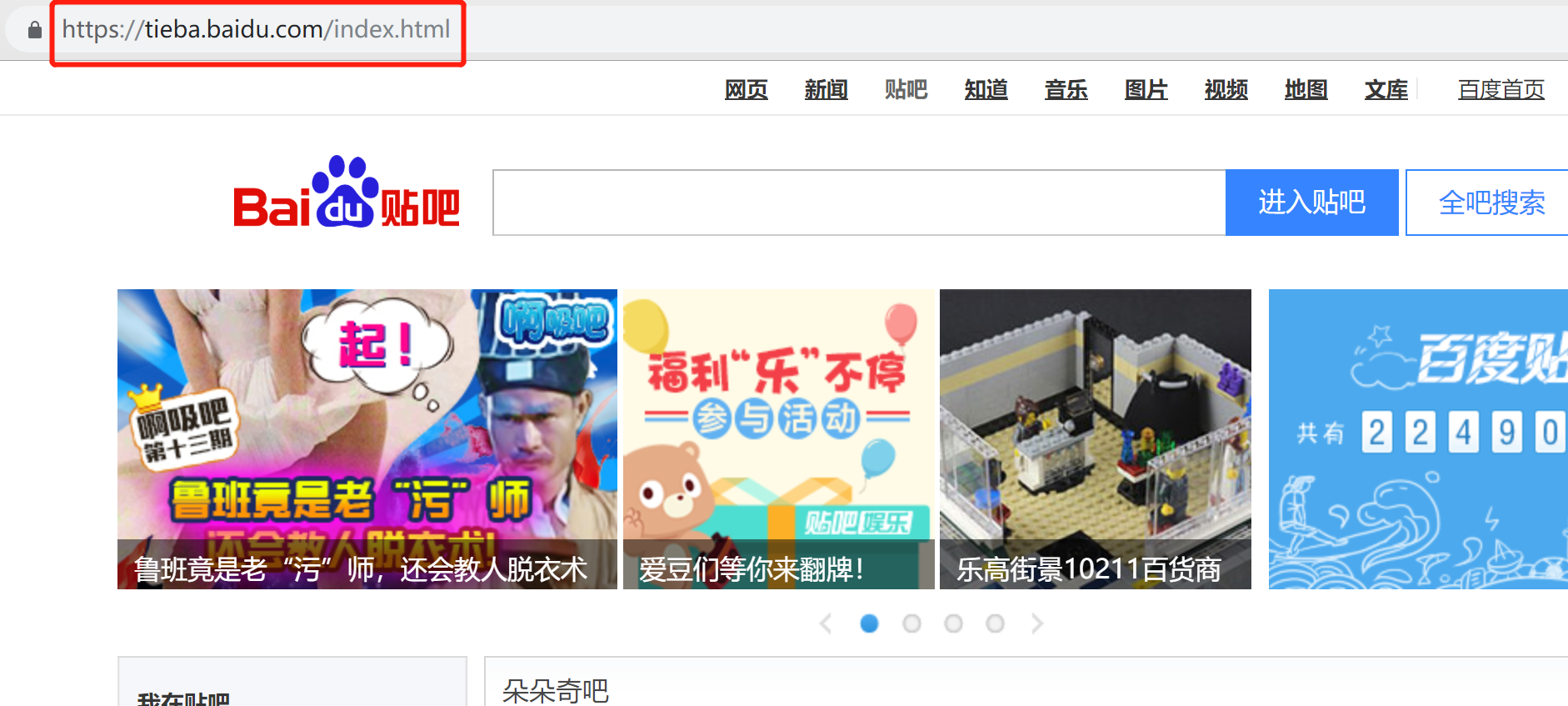
首先使用chrome浏览器,进入百度贴吧
注意输入框中的url
分析
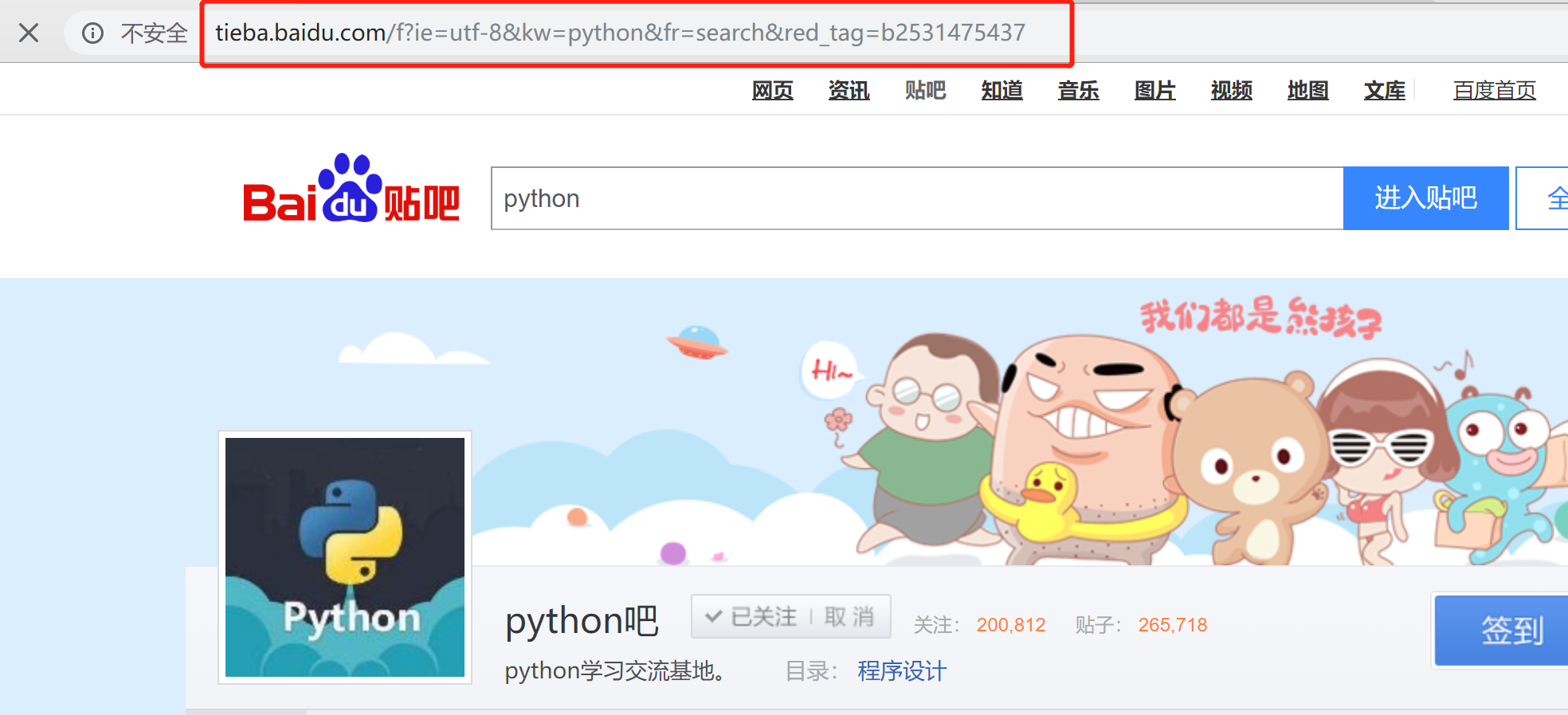
为了进行具体的url分析,我在搜索框中输入"Python",看一下url的变化
这时url变成了:
http://tieba.baidu.com/f?ie=utf-8&kw=python&fr=search&red_tag=b2531475437
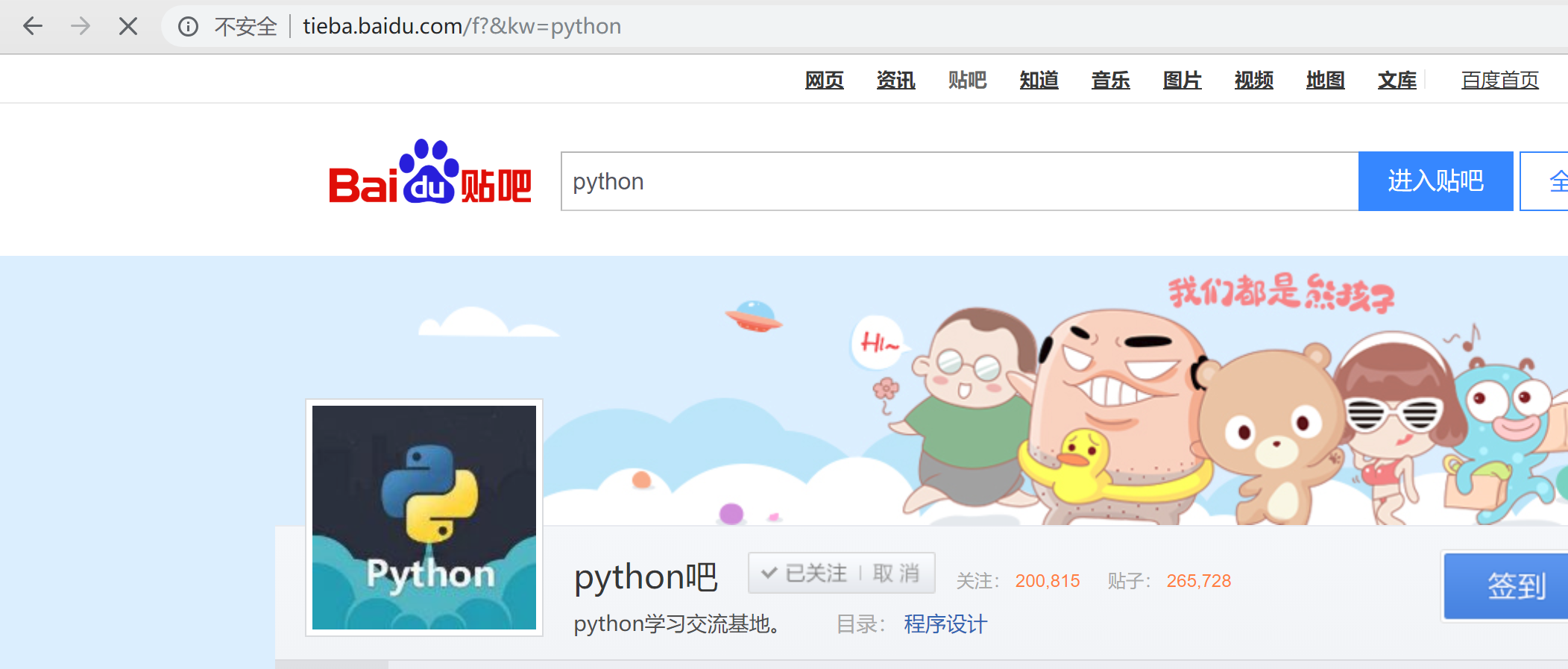
通过分析,做一个测试, 删除url一些东西:
http://tieba.baidu.com/f?&kw=python
依旧可以得到正常的页面
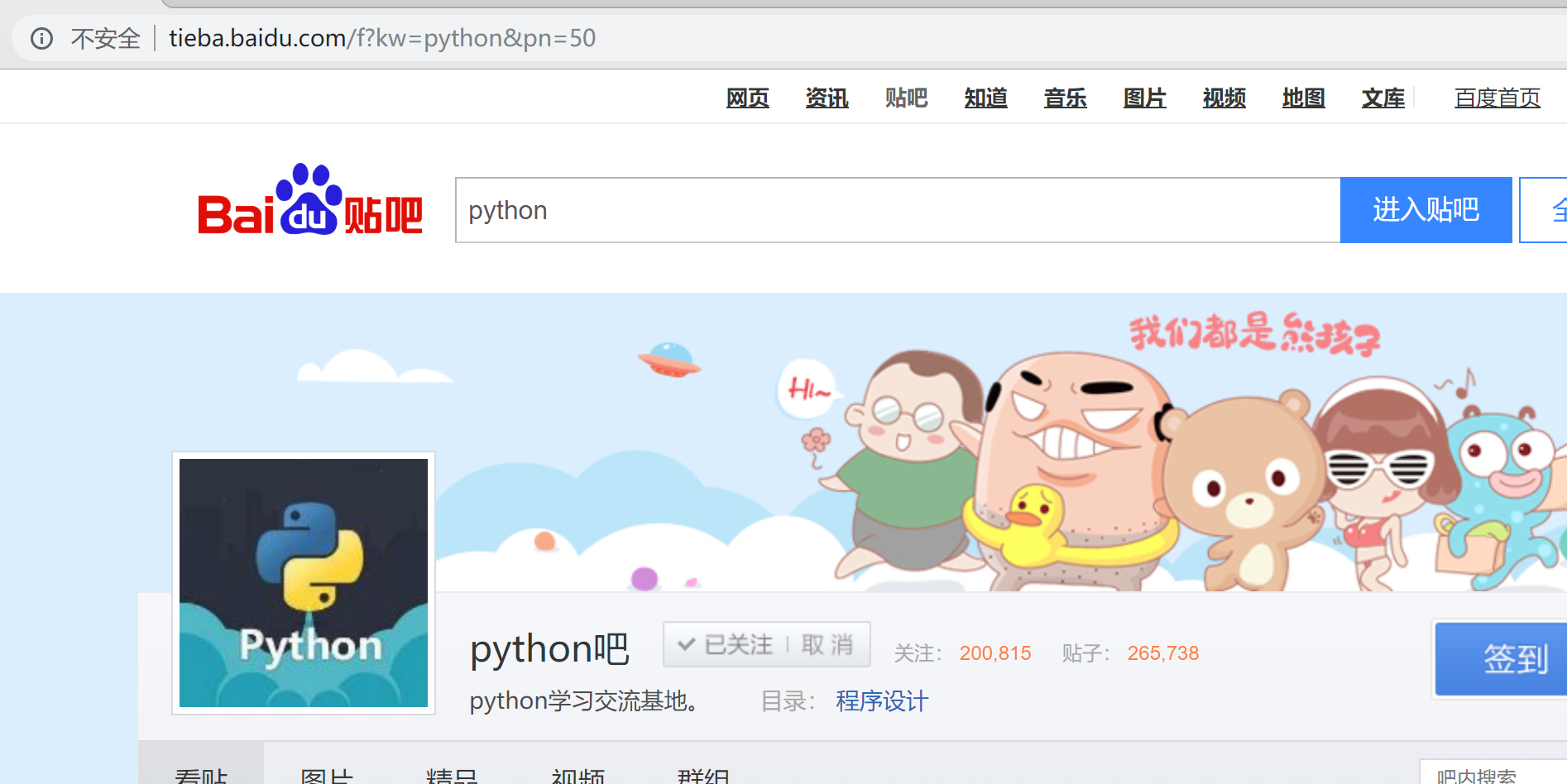
下面进行翻页测试:
得到这样的一条url:
http://tieba.baidu.com/f?kw=python&ie=utf-8&pn=50
通过分析,再进行一次测试,删除url中的一些东西:
得到下面的url
http://tieba.baidu.com/f?kw=python&pn=50
依旧可以得到相应的页面,因此可以得出结论:
kw 和 pn 是这个页面中最重要的关键词,kw控制关键词(其实就是keyword的缩写), pn(其实就是page_number的缩写)控制翻页,每翻一页,pn增加50,也就是说一页有50条数据。
分析结束,开始代码
初始url先用这个,之后再慢慢修改: http://tieba.baidu.com/f?kw=python&pn=50
直接上代码,注意看代码中的注释
# 爬取百度贴吧
import requests
class BdTieba():
def __init__(self, name, pn):
# 保存贴吧名
self.name = name
# 初始url
self.base_url = "http://tieba.baidu.com/f?kw={}&pn=".format(name)
# 构造请求头
self.headers = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/69.0.3497.100Safari/537.36"
}
# 2. 批量生成url
# 使用列表推导式生成了url列表
self.url_list = [self.base_url + str(i*50) for i in range(pn)]
# 打印测试
# print(self.url_list)
# 3. 批量发送请求,封装发送请求
def get_data(self, url):
response = requests.get(url, headers=self.headers)
return response.content
def save_data(self, data, index):
filename = self.name + "_{}.html".format(index)
with open(filename, "wb") as f:
f.write(data)
def run(self):
# 1.请求初始url,测试使用
# response = requests.get(url=self.base_url, headers=self.headers)
# 打印测试,测试成功返回结果
# print(response.text)
# 2.批量生成url
for url in self.url_list:
data = self.get_data(url)
# 3.批量发送请求
# 4.保存网页,为了保存的网页名字不重复,且有顺序,这里使用index进行区分
# 获取当前url的index
index = self.url_list.index(url)
# 保存
self.save_data(data, index)
if __name__ == '__main__':
bdspider = BdTieba("python", 10)
bdspider.run()
这里我只通过批量生成url,并批量获取url响应,并保存了url响应数据,这里测试了10页数据,如果想要爬取每个url中的数据,还需要进行页面分析和提取,这里就需要使用xpath,作为新手入门的一个教程,后续我会拿这个项目继续改进,增加xpath解析,爬取每页的文字信息,这里就先到这了。
后面我会写一篇关于xpath的简单快速上手文章,然后再对这个实战进行下一步的更新
over~
peace~
个人博客: www.limiao.tech
微信公众号:TechBoard