=== DataFrame 简介 ===
定义:数据帧 (DataFrame) 是二维数据结构,即数据以行和列的表格方式排列。
特点:
1、 潜在的列是不同的类型
2、 大小可变
3、 标记轴是行和列 (行、列索引)
4、 可以对行和列进行算数运算
=== 创建DataFrame ===
将多个Series合并到一起,形成DataFrame
1、使用列表创建[]
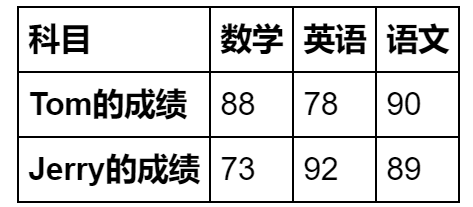
Tom_dict = {'语文':90,'数学':88,'英语':78}
Jerry_dict = {'语文':89,'数学':73,'英语':92}
Tom = pd.Series(Tom_dict,name='Tom的成绩')
Jerry = pd.Series(Jerry_dict,name='Jerry的成绩')
Tom.index.name='科目'
Jerry.index.name='科目'
# 用DataFrame合并Series
# pd.DataFrame(data,index)
# 如果Series表示的是一个人的一行数据,那么生成DataFrame的时候使用[]
pd.DataFrame([Tom,Jerry])
2、使用字典创建{}
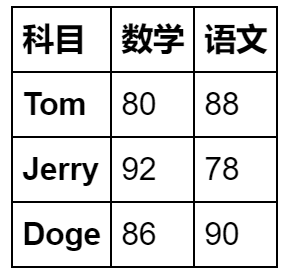
Chinese = pd.Series([88,78,90],index=['Tom','Jerry','Doge'])
Maths = pd.Series([80,92,86],index=['Tom','Jerry','Doge'])
# 如果Series表示的是一列数据,那么使用{}
stu_info = pd.DataFrame({"语文":Chinese,"数学":Maths})
stu_info.columns.name = '科目'
stu_info
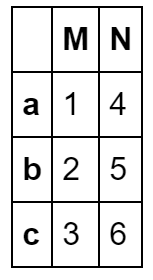
pd.DataFrame({"M":[1,2,3],"N":[4,5,6]},index=list("abc"))
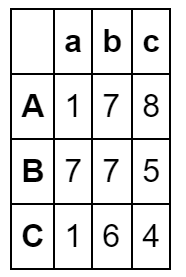
3、 使用数组创建 column行索引,index列索引
pd.DataFrame(np.random.randint(0,9,[3,3]),columns=list("abc"),index=list("ABC"))
=== 从文件里获取数据 ===
Excel文件
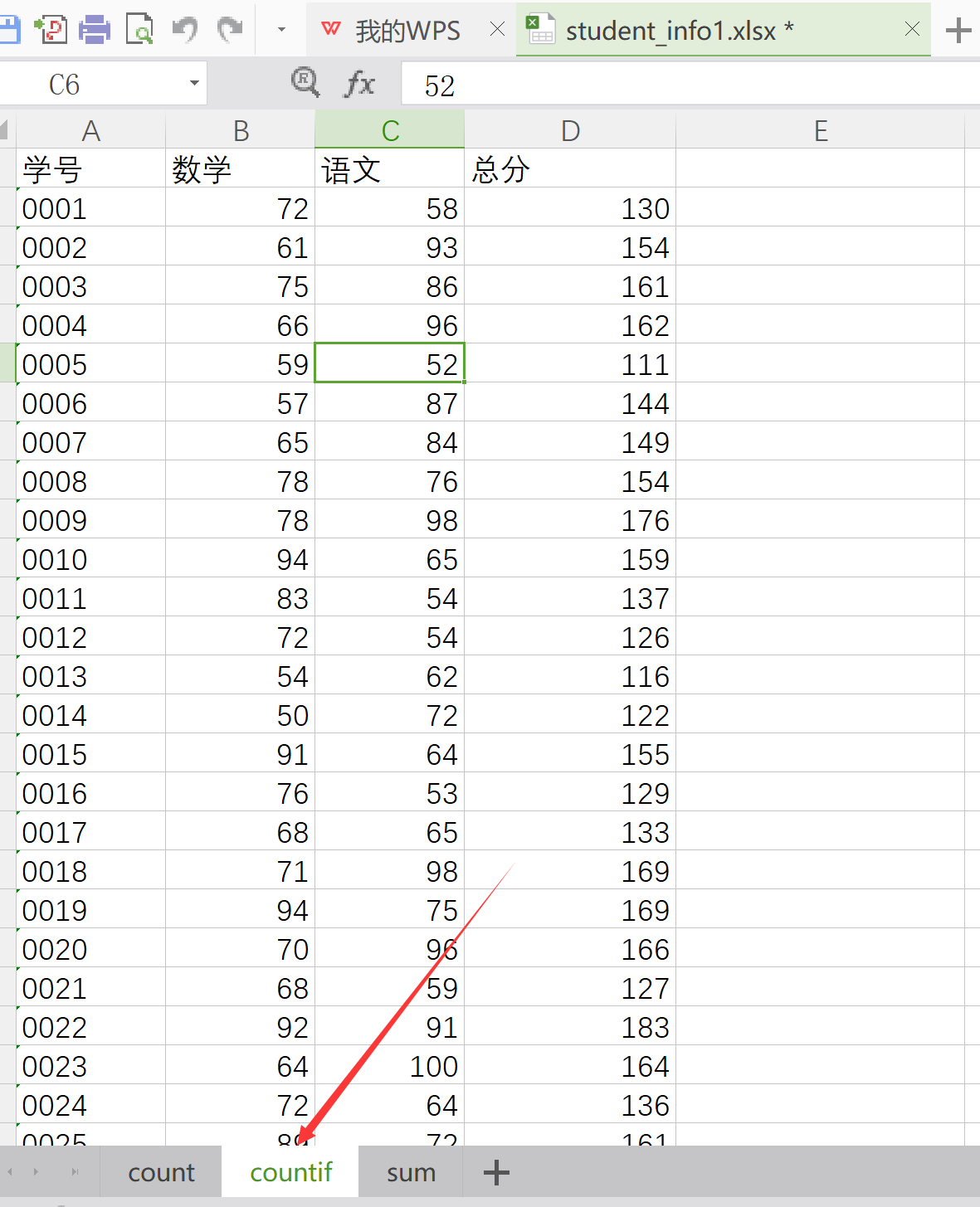
1、sheet_name 表格的小表名
stu_info = pd.read_excel('student_info1.xlsx',sheetname='countif').head(2)
stu_info.columns.name='学科'
stu_info
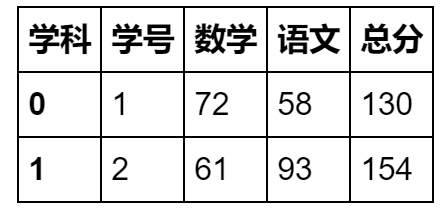
2、 把哪一列当作行索引 index_col
stu_info = pd.read_excel('student_info1.xlsx',sheetname='countif',index_col=0).head(2)
stu_info.columns.name='学科'
stu_info
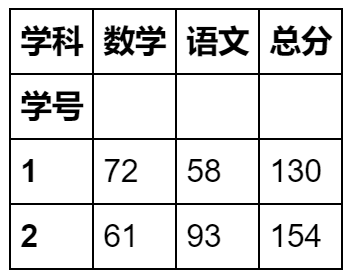
3、 set_index("列名") 更改某一列为行索引
stu_info.set_index='学号'
stu_info
4、 reset_index(drop=True) 重置行索引,并把行索引转换为数据列
drop=True 不想要学号,即把行索引数据删除
stu_info.reset_index(drop=True)
csv文件
1、读取csv文件
stu_info = pd.read_csv('student_info1.csv')
stu_info
2、 从第I行开始作为列索引
header=None或数字
NONE 说明文件里面没有设置列索引,不把第一行当索引了
0,1 行当索引。默认是第0行
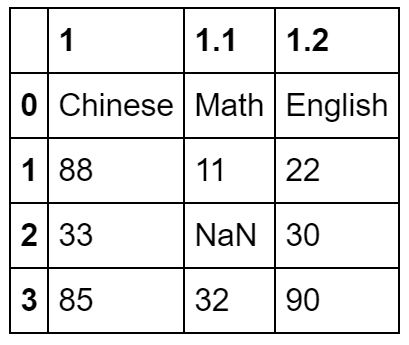
stu_info = pd.read_csv('student_info1.csv',header=1)
stu_info
3、 加列索引
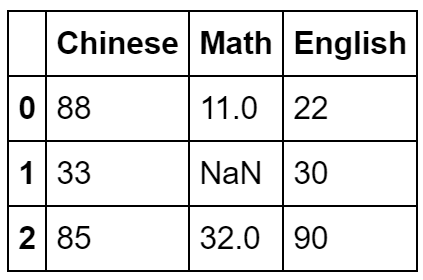
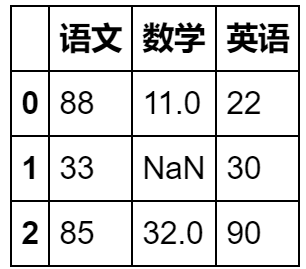
stu_info = pd.read_csv('student_info1.csv',header=1,names=['语文','数学','英语'])
stu_info
4、编码 、解析引擎
encoding 编码 默认utf-8 Windows新建文件,gb2312,gbk
engine 解析引擎 c比较快 python支撑更多方法
stu_info = pd.read_csv('student_info1.csv',encoding='utf-8',engine='python')