在美国的大学课程中,101是所有课程中的第一门,是新生入学后的必修课程。阿里巴巴中间件技术专家刘振东在上周的Apache RocketMQ开发者沙龙北京站的活动上,进行了主题为《ApacheRocketMQ 101》的分享,帮助开发者从0开始学习 Apache RocketMQ,除了一些基础的入门内容外,还有很多是在社区未发表过的个人所感所悟,首次对外分享。分享内容包括RocketMQ的起源、RocketMQ概念模型、存储模型、部署模型和最佳实践总结,其中最佳实践的内容是阿里中间件技术类岗位的必考面试题。
![40f3d63cd76ab8dcd612cb17d70a758438356922]()
嘉宾介绍:刘振东,阿里巴巴中间件技术专家,Apache RocketMQ PMC/Committer,2016年中间件性能挑战赛亚军,具有丰富的分布式系统设计和优化经验,目前负责Apache RocketMQ新航道探索和创新。
一、RocketMQ的起源
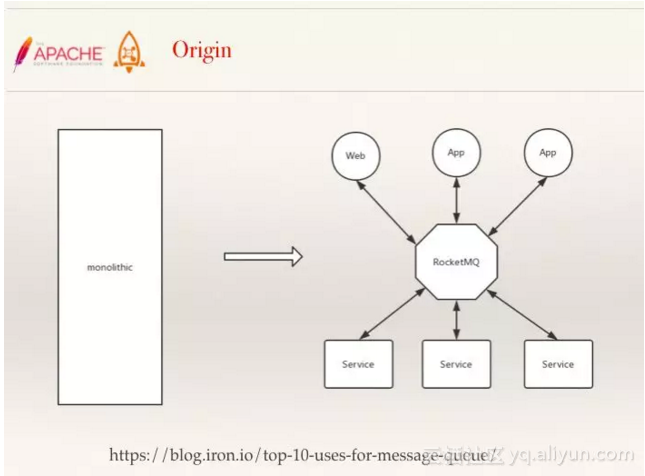
通常,每个产品的诞生都源于一个具体的需求或问题,RocketMQ也不例外。起初,产品的原型像一个巨石,把所有需要实现的程序和接口都罗列到一起。但随着公司业务的发展,所有的系统和功能都在这个巨石上开发,当覆盖几百上千名开发人员的时候,瓶颈就出来了。这时候,就需要我们把系统进行分解。
![313d680e8fbada085584497679620eefa477bcd8]()
图释:巨石 -> 分布式
分解后,就出现了上图中的分布式架构,这类架构最大的特点就是解耦,而RocketMQ的异步解耦意味着底层的重构不会影响到上层应用的功能。RocketMQ另一个优势是削峰填谷,在面临流量的不确定性时,实现对流量的缓冲处理。此外,RocketMQ的顺序设计特性使得RocketMQ成为一个天然的排队引擎,例如,三个应用同时对一个后台引擎发起请求,排队引擎的特性可以确保不会引起“撞车”事故。
二、RocketMQ的概念模型
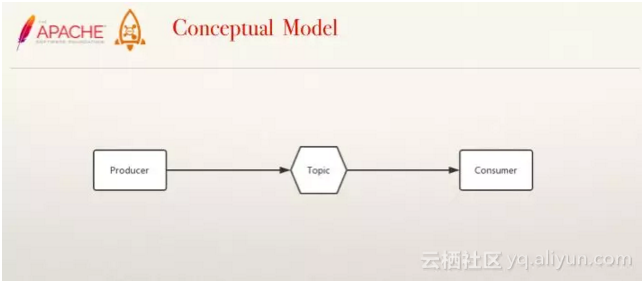
对于任何一款中间件产品而言,清晰的概念模型是帮助开发者正确理解使用它的关键。从RocketMQ的概念模型来看:Topic是用于存储逻辑的地址的,Producer是信息的发送,Consumer是信息的接收者。
![6573a1b1ed3b184ce36bfe5285634c06b1d94995]()
图释:最基本的概念模型
这只是一个基础的概念模型,在实际的生产中,结构会更复杂,例如我们需要对中间的Topic进行分区,出现多个有关联的Topic,再如同一个信息的发送方会有多个订阅者,同一个需求方会有多个发送方,出现一对多、多对一的情况。
![0b7ee0279854deb8bb17bc9e07d43563a628b754]()
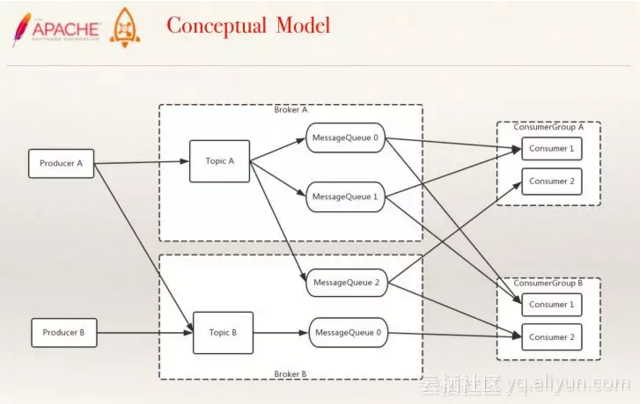
图释:扩展后的概念模型
上图就是对Topic、Producer、Consumer扩展后的概念模型。RocketMQ中可以接触到的所有概念都可以在这个概念模型图中找到。左边有两个Producer,中间就是两个分布式的Topic,用于存储逻辑地址的两个Topic中分别有两个用于存储物理存储地址的Message Queue,Broker是实际部署过程的对应的一台设备,右边则是两个Consumer,Consumer Group是代表两个Consumer可共享相互之间的订阅。不同的Consumer Group相互独立。一句话总结就是不同的Group是广播订阅的,同一个Group则是负载订阅的。图中的连线表示各模块之间的关系,例如Consumer Group A中的Consumer1对应着Message Queue0和Message Queue1的两个队列,分布在BrokerA这一台设备上。
三、RocketMQ的存储模型
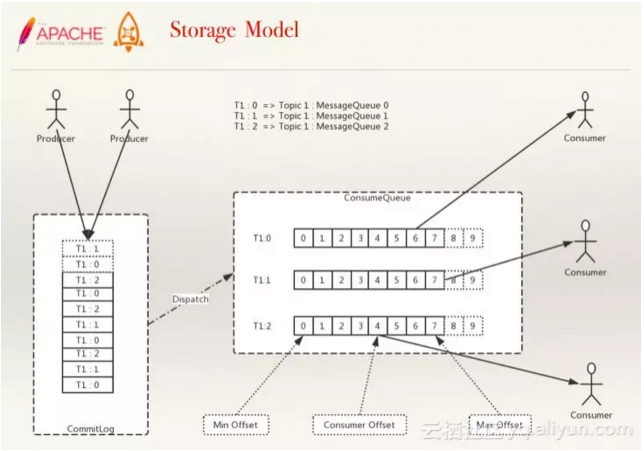
RocketMQ的消息的存储是由ConsumeQueue和CommitLog 配合来完成的,ConsumeQueue中只存储很少的数据,消息主体都是通过CommitLog来进行读写。
![c5057b7fd9f044f04cf3b34bf2b58d2bf1f6fb97]()
图释:存储模型
CommitLog:是消息主体以及元数据的存储主体,对CommitLog建立一个ConsumeQueue,每个ConsumeQueue对应一个(概念模型中的)MessageQueue,所以只要有Commit Log在,Consume Queue即使数据丢失,仍然可以恢复出来。
Consume Queue:是一个消息的逻辑队列,存储了这个Queue在CommitLog中的起始offset,log大小和MessageTag的hashCode。每个Topic下的每个Queue都有一个对应的ConsumerQueue文件,例如Topic中有三个队列,每个队列中的消息索引都会有一个编号,编号从0开始,往上递增。并由此一个位点offset的概念,有了这个概念,就可以对Consumer端的消费情况进行队列定义。
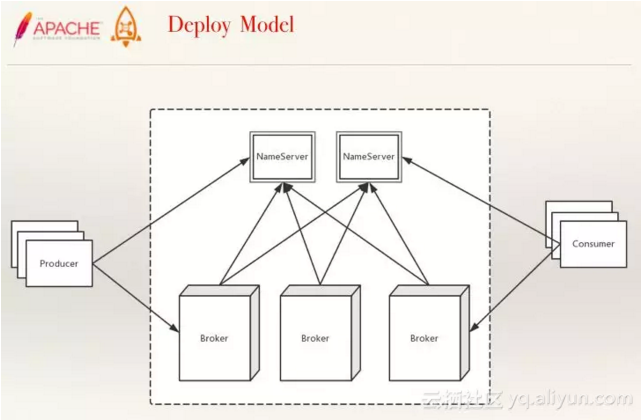
四、RocketMQ的部署模型
在实际的部署过程中,Broker是实际存储消息的数据节点,Nameserver则是服务发现节点,Producer发送消息到某一个Topic,并给到某个Consumer用于消费的过程中,需要先请求Nameserver拿到这个Topic的路由信息,即Topic在哪些Broker上有,每个Broker上有哪些队列,拿到这些请求后再把消息发送到Broker中;相对的,Consumer在消费的时候,也会经历这个流程。
![c9fda620c8b299c63349e615df810716d02bab57]()
图释:部署模型
五、RocketMQ最佳实践总结
这是我们在实践过程的总结,同时我们也把其中一些普适性的总结作为阿里中间件技术岗的面试题,目的是帮助大家更深刻的理解我们在设计分布式消息系统的一些思考和探索。
Q1:分布式消息系统中,如何避免消息重复?
造成消息重复的根本原因是:网络不可靠。只要通过网络交换数据,就无法避免这个问题。所以解决这个问题的办法就是绕过这个问题。那么问题就变成了:如果消费端收到两条一样的消息,应该怎样处理?
a. 消费端处理消息的业务逻辑保持幂等性;
b. 保证每条消息都有唯一编号且保证消息处理成功与去重表的日志同时出现。
通过幂等性,不管来多少条重复消息,可以实现处理的结果都一样。再利用一张日志表来记录已经处理成功的消息的ID,如果新到的消息ID已经在日志表中,那么就可以不再处理这条消息,避免消息的重复处理。
Q2:顺序消息扩容的过程中,如何在不停写的情况下保证消息顺序?
1. 成倍扩容,实现扩容前后,同样的key,hash到原队列,或者hash到新扩容的队列;
2. 扩容前,记录旧队列中的最大位点;
3. 对于每个Consumer Group,保证旧队列中的数据消费完,再消费新队列,也即:先对新队列进行禁读即可;
Q3:分布式消息系统中,如何对消息进行重放?
消费位点就是一个数字,把Consumer Offset改一下就可以达到重放的目的了。
![a5a3aa4ddf245f1a5e5daaabdea170e6658570b7]()
Apache RocketMQ部分开发者合影
原文发布时间为:2018-11-05
本文作者:刘振东
本文来自云栖社区合作伙伴“技术琐话”,了解相关信息可以关注“技术琐话”。