1.1.1
关于blktrace
我们知道,在iostat工具中,await表示单个I/O所需的平均时间,但它同时包含了I/O Scheduler所消耗的时间和硬件所消耗的时间,所以不能作为硬件性能的指标,至于iostat的svctm更是一个废弃的指标。而blktrace可以在这种场合就能派上用场,从中可以分析是IO Scheduler慢还是硬件响应慢。
Blktrace是一个用户态的工具,用来收集磁盘IO信息中当IO进行到块设备层(block层,所以叫blk trace)时的详细信息(如IO请求提交,入队,合并,完成等等一些列的信息)。使用者可以获取I/O请求队列的各种详细的情况,包括进行读写的进程名称、进程号、执行时间、读写的物理块号、块大小等等,是一个Linux下分析I/O相关内容的很好的工具。
目前已经集成到内核2.6.17及其之后的内核版本中。
1.1.2
关于blktrace源码
blktrace代码下载地址:
git clone git://git.kernel.dk/blktrace.git
或者从快照站点下载:
http://brick.kernel.dk/snaps/
可以直接执行make 命令。
PS:需要安装libaio-dev包。
1.1.3
blktrace原理即io栈
一个I/O请求进入block layer之后,会经历下面的过程:
l Â
Remap: 可能被DM(Device Mapper)或MD(Multiple Device, Software RAID) remap到其它设备
l Â
Split: 可能会因为I/O请求与扇区边界未对齐、或者size太大而被分拆(split)成多个物理I/O
l Â
Merge: 可能会因为与其它I/O请求的物理位置相邻而合并(merge)成一个I/O
l Â
被IO Scheduler依照调度策略发送给driver
l Â
被driver提交给硬件,经过HBA、电缆(光纤、网线等)、交换机(SAN或网络)、最后到达存储设备,设备完成IO请求之后再把结果发回。
l
blkparse显示的各指标点示意:
Q – 即将生成IO请求
G – IO请求生成
I – IO请求进入IO Scheduler队列
D – IO请求进入driver
C – IO请求执行完毕
根据以上步骤对应的时间戳就可以计算出I/O请求在每个阶段所消耗的时间:
Q2G – 生成IO请求所消耗的时间,包括remap和split的时间;
G2I – IO请求进入IO Scheduler所消耗的时间,包括merge的时间;
I2D – IO请求在IO Scheduler中等待的时间;
D2C – IO请求在driver和硬件上所消耗的时间;
Q2C – 整个IO请求所消耗的时间(Q2I + I2D + D2C = Q2C),相当于iostat的await。
D2C可以作为硬件性能的指标;
I2D可以作为IO Scheduler性能的指标。
其他见下表:
| Act |
Description |
| A |
IO was remapped to a different device |
| B |
IO bounced |
| C |
IO completion |
| D |
IO issued to driver |
| F |
IO front merged with request on queue |
| G |
Get request |
| I |
IO inserted onto request queue |
| M |
IO back merged with request on queue |
| P |
Plug request |
| Q |
IO handled by request queue code |
| S |
Sleep request |
| T |
Unplug due to timeout |
| U |
Unplug request |
| X |
Split |
1.1.4
btrecord、btreplay
btrecord用于记录由blktrace产生的I/O负载。其将会解析由blktrace产生的每一个文件,提取出将会用于I/O回放的I/O描述信息。
#blktrace /dev/vda -w 100
用blktrace产生负载文件,生成文件在当前目录下,默认文件名为vda.blktrace.0,vda为被测试设备。
btrecored -d ./ vda -v
注意命令中的空格,记录当前目录下,文件名为vda.blktrace.0 的Trace文件数据,输出文件名默认为:vda.replay.0。
btreplay -d ./ vda -W -v
btreplay用于重放I/O。其基于btrecord产生的数据文件。回放当前目录下的trace文件,默认为:vda.replay.0文件,-W表示允许写操作。
1.1.5
blkiomon
使用blkiomon来动态显示IO栈情况,命令如下:
./blktrace /dev/vda -a issue -a complete -w 10 -o - | ./blkiomon -I 1 -h -
1.1.6
btt
#blktrace -w 100 /dev/vda
blkparse查看的数据量比较大,不利于查看,通过btt可以对blktrace数据进行自动分析。先用blkparse可以把原本按CPU分别保存的文件合并成一个,文件名为vda.bin:
./blkparse -i vda -d vda.bin
执行btt对vda.bin进行分析:
#btt -i vdb.bin
1.1.7
blktrace工具使用
可以直接使用如下命令进行监控:
blktrace -d /dev/nvme0n1 -o test1
注意的是文件里面存的是二进制数据,需要blkparse来解析。
或者直接如下命令,实时解析输出,不过这个存在一个风险就是需要实时的将大量的事件进行排序:
blktrace -d /dev/nvme0n1 -o - | blkparse -i –
另外,blktrace也能使用C/S模式,
被测机器SUT上运行blktrace -l,然后在客户机上运行:
blktrace -d /dev/sda -h <server hostname>
此外还有工具verify_blkparse,用于检测blkparse工具输出的文件在时间上是否是正确的。Blkrawverfity用于blktrace工具输出的文件数据是否正确。
1.1.8
参考
使用README
1.2
(可)blktrace工具源码——下篇
上篇中介绍了blktrace工具,以及工具的使用和原理。
接下来我们一起剖析下blktrace工具源码。
直接来看main函数,调用setlocale函数设置地域化信息。调用getpagesize函数来获取页大小,继而获取在线CPU数量。
接着调用signal来设置信号处理函数:
signal(SIGINT, handle_sigint);
signal(SIGHUP, handle_sigint);
signal(SIGTERM, handle_sigint);
signal(SIGALRM, handle_sigint);
signal(SIGPIPE, SIG_IGN);
信号处理函数主要作用是快速停止跟踪,说白了就是调用ioctl来修改配置:
(void)ioctl(dpp->fd, BLKTRACESTOP);
然后通过函数handle_args来处理参数,根据执行参数设置相关静态变量.当然如果没有参数就调用show_usage函数来显示使用帮助。
最后调用run_tracers函数来启动磁盘跟踪.
1.2.1
工作模式
blktrace支持3中工作模式,代码中定义如下,主要参数是-l和-h来激活后面两个,默认就是第一个模式。
enum {
Net_none = 0,
Net_server,
Net_client,
};
1.2.2
blktrace架构
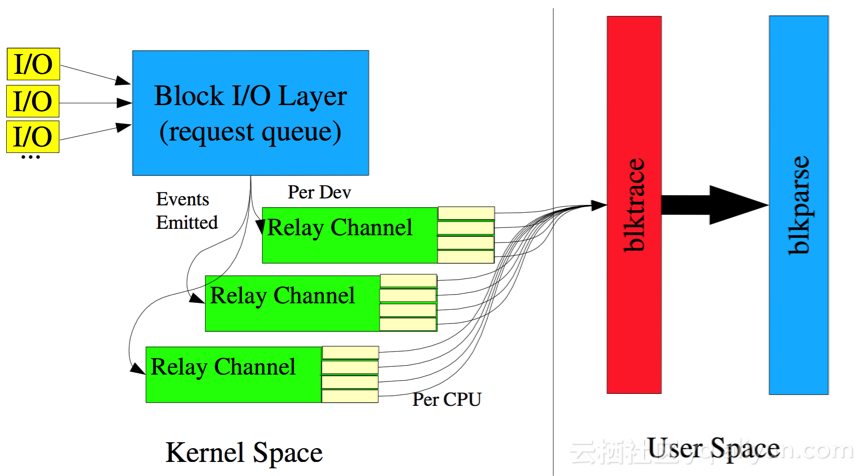
其实很多时候代码只是实现,虽然其中包含了架构的思想,但是在代码这层,架构看上去非常的扁平,缺少立体感。来看下blktrace的架构图,大体如下:
![2884caae58252acc199fcf28f2bbe0da22664f1f]()
整体架构比较清晰,在IO栈中将相关事件给blktrace进行记录,最后由blkparse进行翻译成可读。
因为blktrace工具的作者本身就是内核中块I/O的maintainer.
重要的数据结构有blk_io_trace,位于blktrace_api.h文件中:
/*
* The trace itself
*/
struct blk_io_trace {
__u32 magic; /* MAGIC << 8 | version */
__u32 sequence; /* event number */
__u64 time; /* in nanoseconds */
__u64 sector; /* disk offset */
__u32 bytes; /*
__u32 action; /* what happened */
__u32 pid; /* who did it */
__u32 device; /* device identifier (dev_t) */
__u32 cpu; /* on what cpu did it happen */
__u16 error; /* completion error */
__u16 pdu_len; /* length of data after this trace */
};
其他的,待大家自己去挖掘发现了,祝玩得开心。