Hanlp作为一款重要的中文分词工具,在GitHub的用户量已经非常之高,应该可以看得出来大家对于hanlp这款分词工具还是很认可的。本篇继续分享一篇关于hanlp的使用实例即Python调用hanlp进行中文实体识别。
想要在python中调用hanlp进行中文实体识别,Ubuntu 16.04的系统环境
1.安装jpype1,在cmd窗口输入
pip install jpype1
2.下载hanlp的安装包
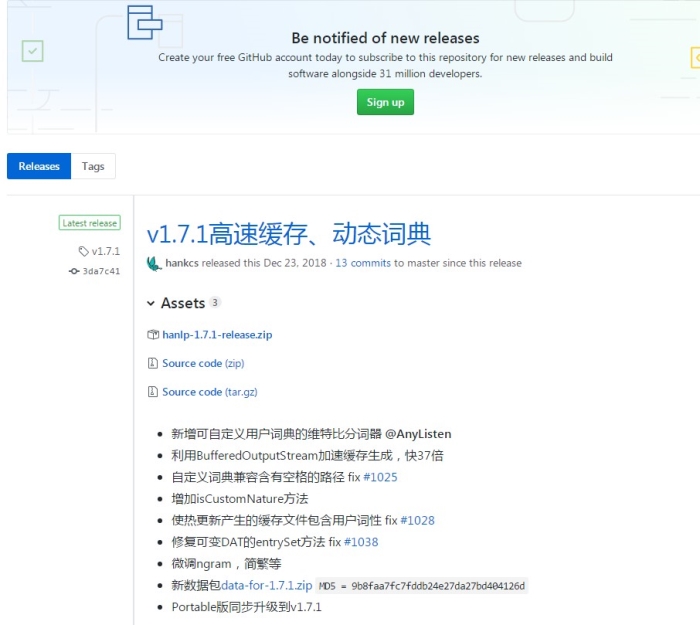
在github.com/hankcs/HanLP/releases
(1)下载新的 hanlp-1.7.1-release.zip文件,里面包含hanlp-1.7.1.jar , hanlp-1.7.1-sources.jar , hanlp.properties
(2)点击data-for-1.7.1.zip下载。(底下第8条)
![e2bf8c4b16d0594b06cef1a25ab902d9416929f6]()
注:如果你在hanlp.linrunsoft.com/services.html点击下载hanlp.jar,下载下来的是hanlp-1.2.8.jar。之后在使用过程中可能会出现“字符类型对应表加载失败”的错误,查看相应路径下也没有CharType.dat.yes文件。原因可能是hanlp-1.2.8版本过低,使用新版本应该不会出现这个问题。
![3bb06fc143cb24f9572834df371c65ca83f8fc7c]()
3.新建一个文件夹Hanlp,放文件hanlp-1.7.1.jar和hanlp.properties文件
新建一个文件夹hanlp,放data-for-1.7.1.zip解压后的文件
配置hanlp.properties中的第一行的root为hanlp文件夹的位置,也就是data-for-1.7.1.zip解压后的文件放的位置。
4.写py文件调用hanlp进行中文分析。
用法可参考这个博客 blog.csdn.net/u011961856/article/details/77167546。
另,查看HanLP关于实体识别的文档hanlp.linrunsoft.com/doc.html
里面介绍说中文人名标注为“nr”,地名标注为“ns”,机构名标注为“nt”,所以使用用法参考链接里的NLPTokenizer.segment就可以标注出中文句子中的人名,地名和机构名。
比较使用jieba进行词性标注时,也可以标注出中文句子中的人名,地名和机构名。jieba分词的词性说明:
![84b31c43c3732b6300dfc0af6710db4e9770aa82]()