1. 官方文档及参考链接
lÂ
关于词典问题Issue,首先参考:FAQ
lÂ
自定义词典其实是基于规则的分词,它的用法参考这个issue
lÂ
如果有些数量词、字母词需要分词,可参考:P2P和C2C这种词没有分出来,希望加到主词库
lÂ
关于词性标注:可参考词性标注
2. 源码解析
分析 com.hankcs.demo包下的DemoCustomDictionary.java 基于自定义词典使用标准分词HanLP.segment(text)的大致流程(HanLP版本1.5.3)。首先把自定义词添加到词库中:
CustomDictionary.add("攻城狮");
CustomDictionary.insert("白富美", "nz 1024");//指定了自定义词的词性和词频
CustomDictionary.add("单身狗", "nz 1024 n 1")//一个词可以有多个词性
添加词库的过程包括:
lÂ
若启用了归一化HanLP.Config.Normalization = true;,则会将自定义词进行归一化操作。归一化操作是基于词典文件 CharTable.txt 进行的。
lÂ
判断自定义词是否存在于自定义核心词典中
public static boolean add(String word)
{
if (HanLP.Config.Normalization) word = CharTable.convert(word);
if (contains(word)) return false;//判断DoubleArrayTrie和BinTrie是否已经存在word
return insert(word, null);
}
lÂ
当自定义词不在词典中时,构造一个CoreDictionary.Attribute对象,若添加的自定义词未指定词性和词频,则词性默认为 nz,频次为1。然后试图使用DAT树将该 Attribute对象添加到核心词典中,由于我们自定义的词未存在于核心词典中,因为会添加失败,从而将自定义词放入到BinTrie中。因此,不在核心自定义词典中的词(动态增删的那些词语)是使用BinTrie树保存的。
public static boolean insert(String word, String natureWithFrequency)
{
if (word == null) return false;
if (HanLP.Config.Normalization) word = CharTable.convert(word);
CoreDictionary.Attribute att = natureWithFrequency == null ? new CoreDictionary.Attribute(Nature.nz, 1) : CoreDictionary.Attribute.create(natureWithFrequency);
if (att == null) return false;
if (dat.set(word, att)) return true;
//"攻城狮"是动态加入的词语. 在核心词典中未匹配到,在自定义词典中也未匹配到, 动态增删的词语使用BinTrie保存
if (trie == null) trie = new BinTrie<CoreDictionary.Attribute>();
trie.put(word, att);
return true;
}
将自定义添加到BinTrie树后,接下来是使用分词算法分词了。假设使用的标准分词(viterbi算法来分词):
List<Vertex> vertexList = viterbi(wordNetAll);
分词具体过程可参考:
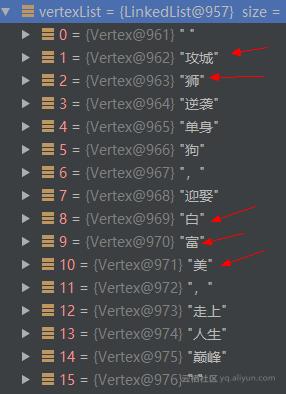
分词完成之后,返回的是一个 Vertex 列表。如下图所示:
![0283ad752cbf0ad1570c2a7fcecb0434feaec4b9]()
然后根据 是否开启用户自定义词典 配置来决定将分词结果与用户添加的自定义词进行合并。默认情况下,config.useCustomDictionary是true,即开启用户自定义词典。
if (config.useCustomDictionary)
{
if (config.indexMode > 0)
combineByCustomDictionary(vertexList, wordNetAll);
else combineByCustomDictionary(vertexList);
}
combineByCustomDictionary(vertexList)由两个过程组成:
lÂ
合并DAT 树中的用户自定义词。这些词是从 词典配置文件 CustomDictionary.txt 中加载得到的。
lÂ
合并BinTrie 树中的用户自定义词。这些词是 代码中动态添加的:CustomDictionary.add("攻城狮")
//DAT合并
DoubleArrayTrie<CoreDictionary.Attribute> dat = CustomDictionary.dat;
....
// BinTrie合并
if (CustomDictionary.trie != null)//用户通过CustomDictionary.add("攻城狮"); 动态增加了词典
{
....
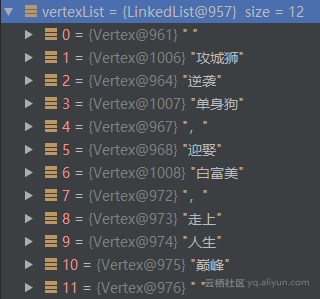
合并之后的结果如下:
![6f9322836db186831c56b7c1dd9fb8abd933315d]()
3. 关于用户自定义词典
总结一下,开启自定义分词的流程基本如下:
lÂ
HanLP启动时加载词典文件中的CustomDictionary.txt 到DoubleArrayTrie中;用户通过 CustomDictionary.add("攻城狮");将自定义词添加到BinTrie中。
lÂ
使用某一种分词算法分词
lÂ
将分词结果与DoubleArrayTrie或BinTrie中的自定义词进行合并,最终返回输出结果
HanLP作者在HanLP issue783:上面说:词典不等于分词、分词不等于自然语言处理;推荐使用语料而不是词典去修正统计模型。由于分词算法不能将一些“特定领域”的句子分词正确,于是为了纠正分词结果,把想要的分词结果添加到自定义词库中,但最好使用语料来纠正分词的结果。另外,作者还说了在以后版本中不保证继续支持动态添加自定义词典。以上是阅读源码过程中的一些粗浅理解,仅供参考。
文章转载自hapjin 的博客