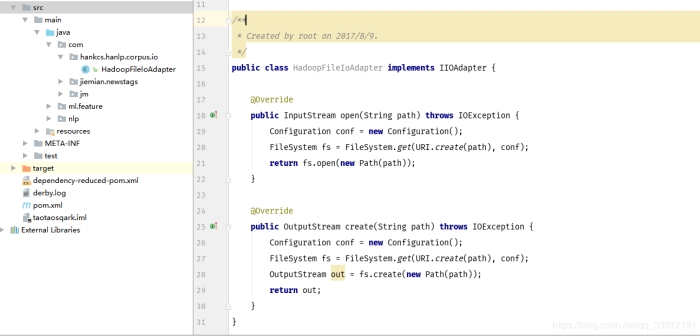


Elasticsearch实例磁盘占用率高排查及解决
开源 ES 实例健康状态 首先,先介绍下开源 Elasticsearch 的三种健康状态:绿色、黄色和红色。 在分片层面, 绿色:所有的主分片和副本分片都已分配。你的集群是 100% 可用的。 黄色:所有主分片都已经分配,但至少有一个副本分片未被分配。此时,搜索结果是正确、完整的,不会有数据丢失。但高可用性已经被弱化,有丢失数据的风险。应尽快介入处理。 红色:集群中至少有一个主分片(以及它的所有副本)未被分配,意味着搜索时将缺少数据,至返回部分数据;同时,要写入该分片的请求会返回异常。 这时候您可能会问:“如果集群中有的索引是绿色,有的是黄色,这时候该怎么决定集群的健康度呢?” 集群的健康状态由最差的索引决定,索引的健康状态由最差的分片决定。 阿里云 ES 实例的健康状态 本文主要从磁盘占用达到高水位问题来谈谈 ES 集群健康状态。 大家都知道,阿里云 ES 在一定前提下,重启时是可以持续提供服务的。 前提是: 1.阿里云ES实例健康度必须确保是绿色状态 2.至少包含1个副本 注意:不排除节点在重启期间,对应CPU和内存使用率会存在临时突增,服务可能会出现抖动,正常情况下过一段时间后会...