前言
之前写过一个关于Elastic Search的文章,当时的我还不会使用markdown,还不知道怎么好好把自己所想的,总结成一个有条理的文章,所以我就想写下了这一篇新文章,帮助自己消化所学的东西,也可以把知识分享给大家。
| 使用 |
版本 |
| 操作系统 |
MacOS |
| ES版本 |
6.3.0 |
| 可视化插件 |
Head |
安装
1.单实例安装
elasticSearch 的安装我觉得相对简单一些,我们可以在官网或者是别的途径,下载到它,官网的下载地址为https://www.elastic.co/downloads/elasticsearch,当前最新的版本为6.4.2。而我使用的版本是6.3.0,如果想要下载到原来版本的ES,可以进入以下网址进行下载https://www.elastic.co/downloads/past-releases。
下载好后,执行bin目录下的elasticsearch即可。
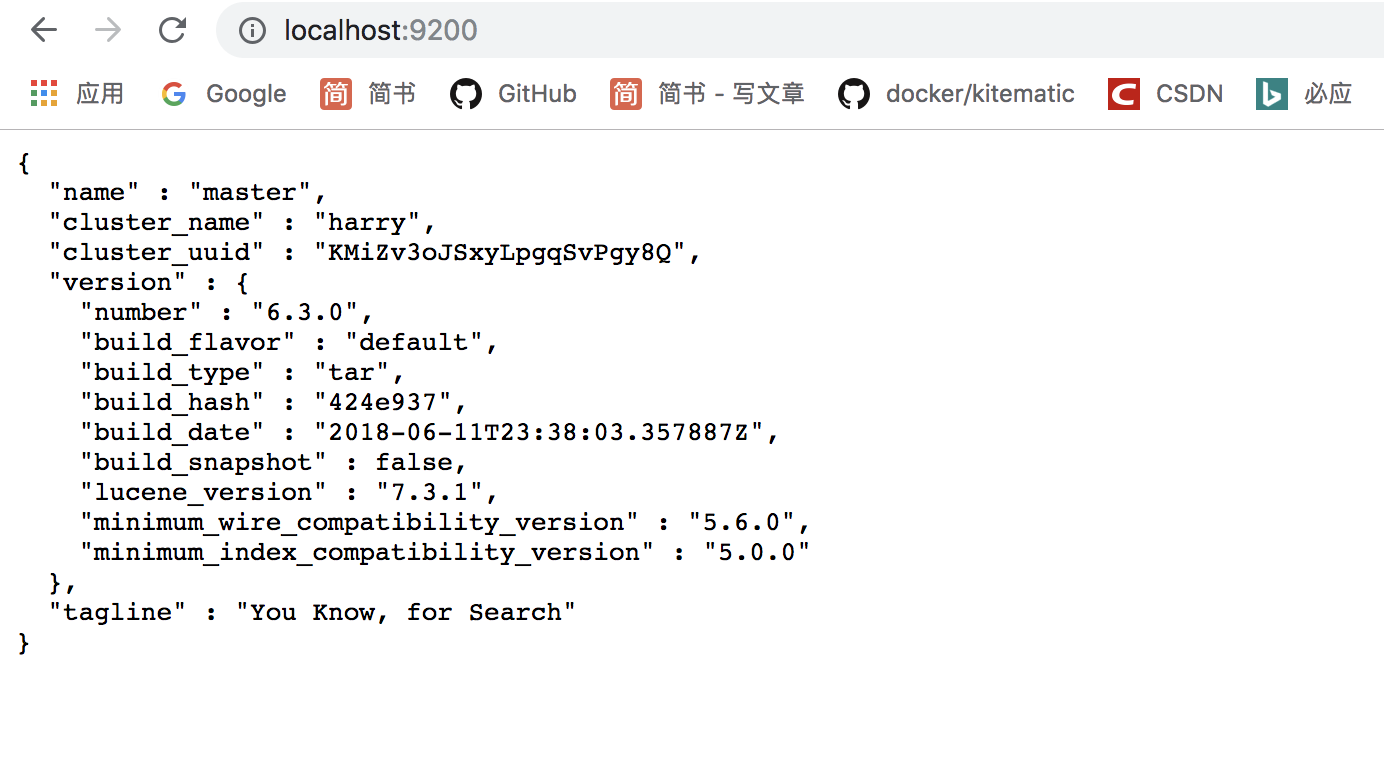
启动后,在浏览器输入http://localhost:9200/即可,效果如下:
2.Head插件安装
Head插件是依托于node环境的,我们在使用插件之前需要先下载node.js。node.js下载好后,通过node -v 查看是否安装成功,然后就可以通过以下网址下载Head插件。Head 插件地址。下载好Head插件以及elasticsearch后,需要修改在elasticsearch 中的config的elasticsearch.yml中加上以下配置内容:
http.cors.enabled: true
http.cors.allow-original: "*"
保证了Es以及Head插件的连通性。
Head插件的启动
1.npm install phantomjs-prebuilt@2.1.15 --ignore-scripts(之所以不使用npm install 是因为这个包,一直都取不到,但是它也不怎么影响使用。)
2.npm install
3.npm run start
启动后,在浏览器输入http://localhost:9100,如果显示了相关内容即可。
3.分布式安装
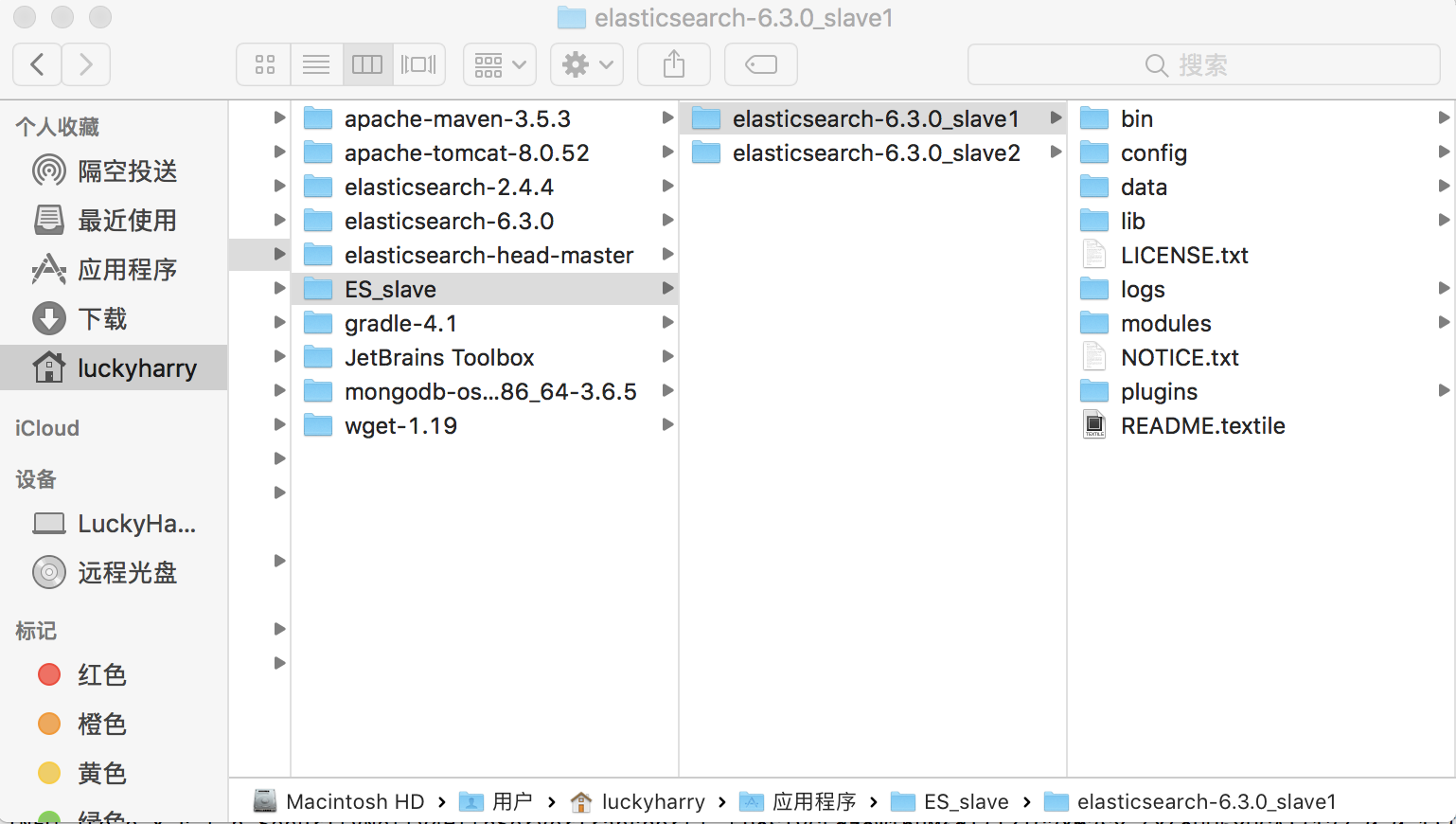
分布式的安装和单实例安装大同小异,把下载下来的ElasticSearch复制两个副本,放在新创建的目录ES_slave(slave为随从奴隶的意思,在这里把我们之前安装好的当做一个master,然后其他的slave配合master形成一套分布式)中,如下图所示:
这里是创建了两个,如果有需求,可以根据需求继续拓展。
然后把两个slave中的elasticsearch.yml文件进行修改,加入以下配置:
#配置ElasticSearch的集群名称
cluster.name: harry
#节点的名称(另一个节点名称可以使用slave2)
node.name: slave1
#设置绑定的IP地址
network.host: 127.0.0.1
#设置对外服务的端口号,默认情况下为9200(这里只要使用没被使用的端口号即可)
http.port: 8200
#设置是否打开多播发现节点,如果不进行配置,不会被主节点发现。
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
配置好后,启动slave的elasticsearch即可。
Tips:我启动的时候报了一个错误。
[2018-10-07T11:57:44,907][INFO ][o.e.d.z.ZenDiscovery ] [slave1] failed to
send join request to master [{master}{dLNpAPsSTvCFgzow1nuM6g}
{lZIG2Xm3Sx-4Y4eHU5x9CA}{127.0.0.1}{127.0.0.1:9300}
{ml.machine_memory=8589934592, ml.max_open_jobs=20,
xpack.installed=true, ml.enabled=true}], reason
[RemoteTransportException[[master][127.0.0.1:9300]
[internal:discovery/zen/join]]; nested: IllegalArgumentException[can't add node
{slave1}{dLNpAPsSTvCFgzow1nuM6g}{4NUyj79cSxuaJL8BMtGejw}{127.0.0.1}
{127.0.0.1:9301}{ml.machine_memory=8589934592, ml.max_open_jobs=20,
xpack.installed=true, ml.enabled=true}, found existing node {master}
{dLNpAPsSTvCFgzow1nuM6g}{lZIG2Xm3Sx-4Y4eHU5x9CA}{127.0.0.1}
{127.0.0.1:9300}{ml.machine_memory=8589934592, xpack.installed=true,
ml.max_open_jobs=20, ml.enabled=true} with the same id but is a different
node instance]; ]
因为我是把master的Es复制过来,作为slave,但是data中还有原来的数据,所以报了这个错,只要把,Es中的data文件夹中的东西都删除就行。
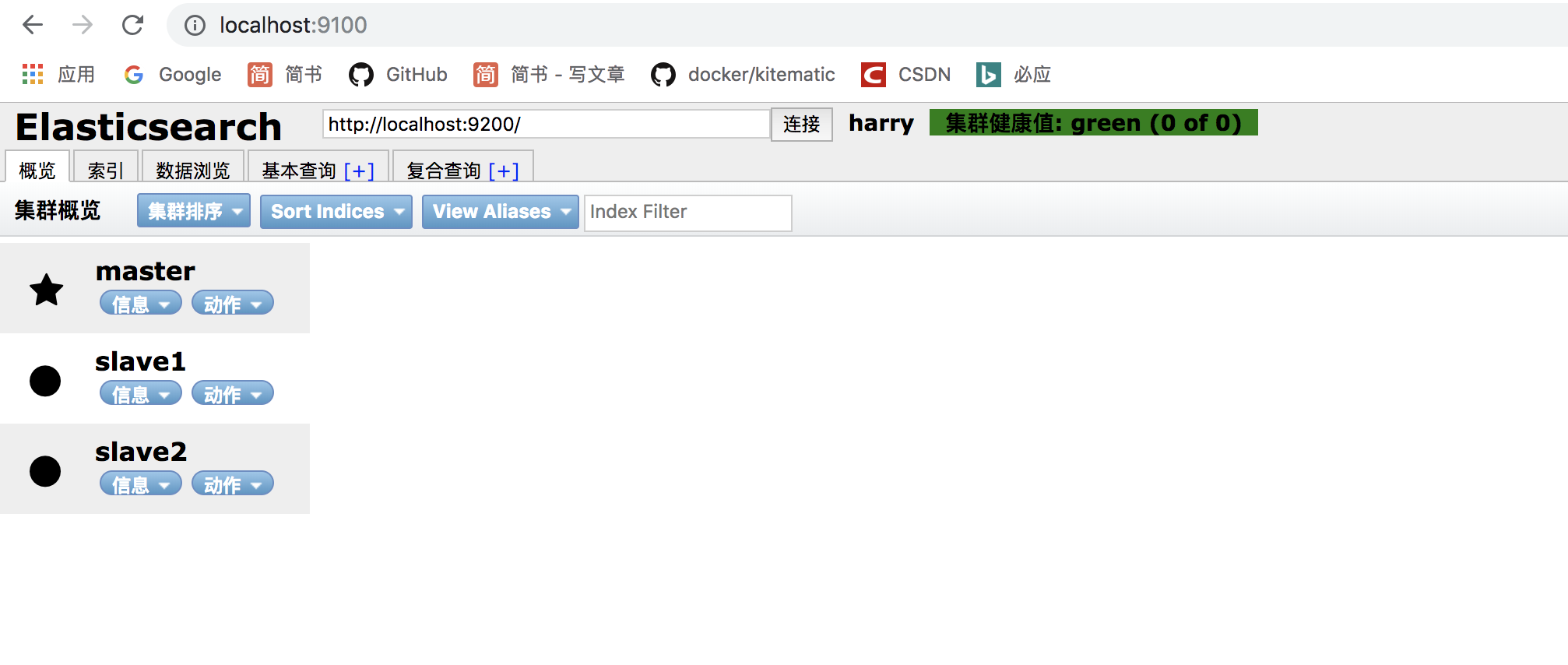
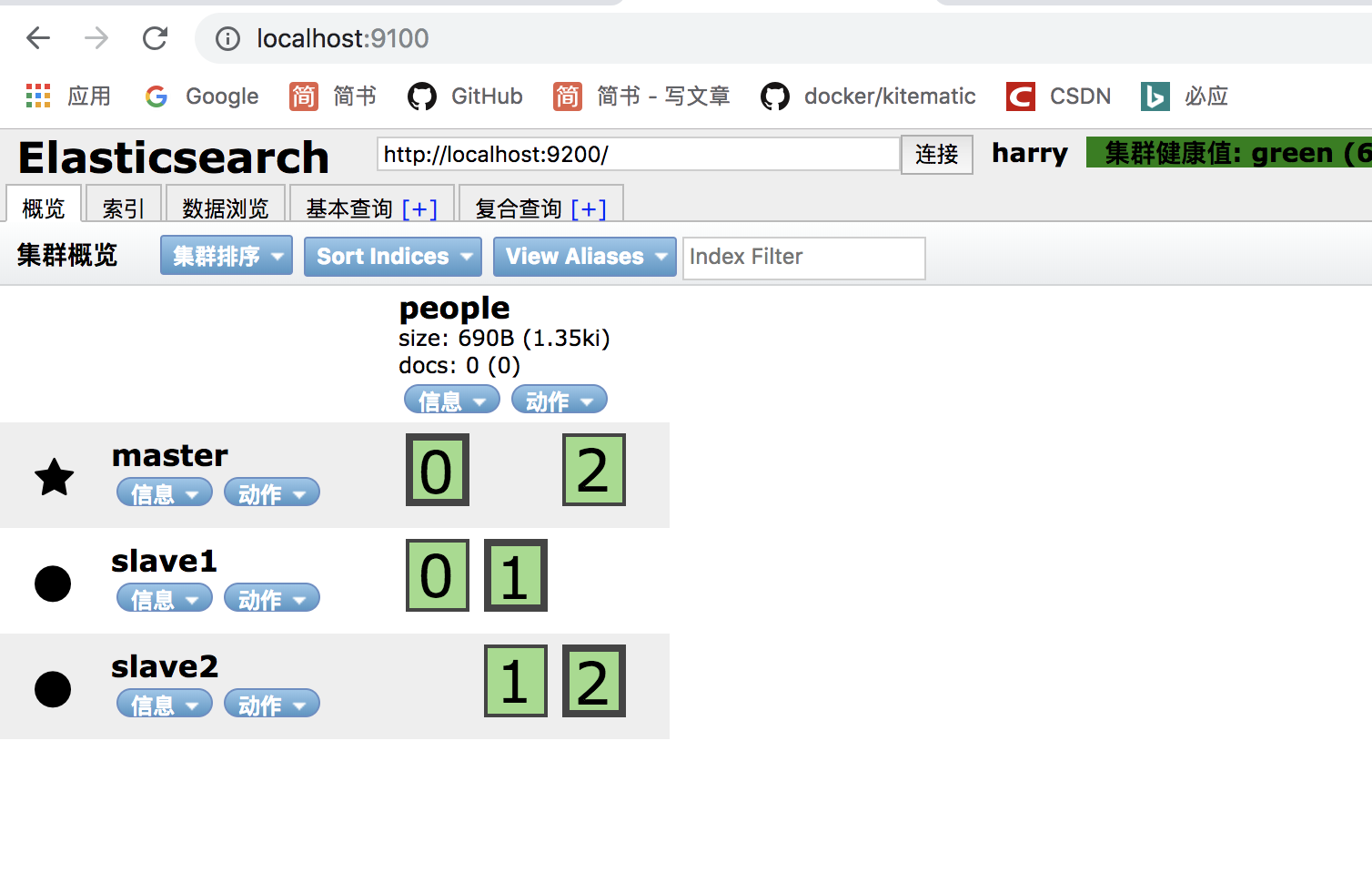
我们现在把master 的ES启动,slave1的ES启动,slave2的ES启动,最后把Head也启动起来,然后浏览器输入http://localhost:9100,效果如下,证明成功。
基本概念
1.索引,类型,文档
Elastic Search 与关系型数据库对比
| Elastic Search |
关系型数据库 |
| 索引 |
数据库 |
| 类型 |
表 |
| 文档 |
行 |
这里的Elastic Search 泛指的是全文检索。一个索引中,包含多个类型,一个类型中包含着多个文档。
在刚接触的时候,我想过这样一个问题,在关系型数据库mysql的like进行模糊查询的效果,与Elastic Search这样的全文检索,效果几乎就是一样的,那为什么还要用全文检索呢?
原因我觉得一共有两个:
第一个是查询的速度特别快。在关系型数据库中,数据是结构化的,我们当要进行模糊查询的时候,会从想要查询的表的第一条数据开始比对,如果不是,继续下一条,如果再不是,继续去查,就这样一直查下去,直到查到了,自己想要的那条数据。而Elastic Search呢?它其实使用了倒排索引。大概意思其实是这样的:现在一个有三篇文章
| id |
content |
| 文章1 |
Java是世界上最好的 . |
| 文章2 |
人生苦短,快学python |
| 文章3 |
C++是世界上最难的 . |
这也是存储在关系型数据库中的存储形式,查询的话,他会一行行的进行查询。而如果存在了Elastic Search 中会变成什么样子呢?在全文检索中存在这分词器这么个东西,分词器会把输入的句子自动的进行一定规律进行分割,例如过空格分割,下划线分割,等等。如果是中文,也有插件可以对其进行语义分割。分割后的效果如下所示(只是举例子,真实情况未必如此)
| 关键词 |
文章号 |
| 世界 |
1,3 |
| 人生苦短 |
2 . |
| Java |
1 . |
| python |
2 |
| C++ |
3 |
当我们输入世界,立刻就知道出现在了第一个,和第三个文章中。
第二个是因为我们在做全文检索的时候,根本用不到那么复杂的逻辑,我们用到基础的增删改查就行,使用了Elastic Search 之后,我们在也不用折腾数据库那么多的数据了。
2.分片与索引
每一个索引包含了多个分片,每个分片是一个lucene索引(lucene是Elasticsearch的底层引擎。)只需要将分片拷贝一份,就完成了分片的备份。
3.集群和节点
每一个集群都有一个集群的名字,一个集群包含多个节点。我们只需要知道集群的名称,便可以拓展集群中的节点。
4.elasticsearch.yml
我上面在启动head插件和设置分布式集群的时候,有修改过这个文件,但是这个文件还有别的可配置属性,我在这里说明一下,以备不时之需。
cluster.name: elasticsearch
#设置集群名称,一个集群只可以有一个名称,ElasticSearch会自己去查找同一个网段下的所有节点
node.name: node-1
#设置节点名称
node.master: true
#设置该节点是否是master节点,默认为true
node.data: true
#设置该节点,是否存储索引数据,默认为true
index.number_of_shards: 5
#设置分片的数量,默认为5个,这个配置只在5.0版本之前好用
index.number_of_replicas: 1
#设置索引副本数量,默认为一个,同样也是只在5.0之前好用。
path.data: /path/to/data
#设置索引数据的存储路径,默认在data文件夹下,可以设置多个文件存储路径,用逗号分隔。
path.logs: /path/to/logs
#设置log日志的存储路径,默认情况下是在logs文件夹下。
bootstrap.mlockall: true
#设置为true来锁住内存
network.host: 0.0.0.0
#设置绑定的Ip地址,默认为0.0.0.0
http.port: 9200
#设置对外服务的HTTP端口号
transport.tcp.port: 9300
#设置节点间交互的TCP端口号,也是给Java API使用的端口号,默认是9300。
transport.tcp.compress: false
#是否压缩TCP传输的数据,默认为false
http.cors.enabled:true
#是否使用http提供对外的服务,默认为true
http.max_content_length: 100mb
#http传输内容的最大容量。
discovery.zen.minimum_master_nodes: 1
#发现master节点的数量,默认为1个。
discovery.zen.ping.timeout: 3s
#发现其他节点,超时的时间。
discovery.zen.ping.multicast.enabled:true
#是否打开多播发现节点。
discovery.zen.ping.unicast.hosts:["host1","host2:port","host3:[portX-portY]"]
#设置集群master几点的初始列表。
script.engine.groovy.inline.update: on
#开启groovy脚本的支持
script.inline: true
#开始所有脚本语言行内执行所有的操作。
基本用法
Elastic Search 我们可以使用REST API与其进行交互,说白了就是使用url地址,通过不同的method(get,post,put,delete)传入不同的json数据。
head插件虽然很好,但是也并不是万能的,我比较习惯用Post man进行api交互。下面讲讲具体的操作。
1.创建索引
| url地址 |
method |
用途 |
| localhost:9200/索引名称 |
put |
创建索引 |
在创建索引之前,我要先说两个概念分别是静态映射和动态映射。
动态映射是在创建索引之初,不添加索引的类型和文档中属性的格式,而是在添加文档的时候,格式会被自动转化。两种不同映射的设置,是由dynamic参数来决定的一共有三个可选值:
- true 动态映射自动添加字段
- false 静态映射,不会自动添加字段
- strict 静态映射,如果添加了新字段会报错
动态转换内容如下:
| JSON格式的数据 |
自动推测的字段类型 |
| null |
没有字段被添加 |
| true or false |
boolean |
| 浮点类型数字 |
float |
| 数字 |
long |
| JSON对象 |
object |
| 数组 |
有数组中第一个非空值决定 |
| string |
有可能是date类型(开启日企检测),double,long,text,keyword |
动态映射json体:
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}
number_of_shards是用来设置分片数量的
number_of_replicas是用来设置副本数量的
静态映射Json体:
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
},
"mappings":{
"it": {
"dynamic":"strict",
"properties":{
"title":{
"type":"text"
},
"content":{
"type":"text"
},
"create_date":{
"type":"date"
}
}
}
}
}
这里的it指的就是类型,在properties中添加自己的字段,并且指定属性的类型。
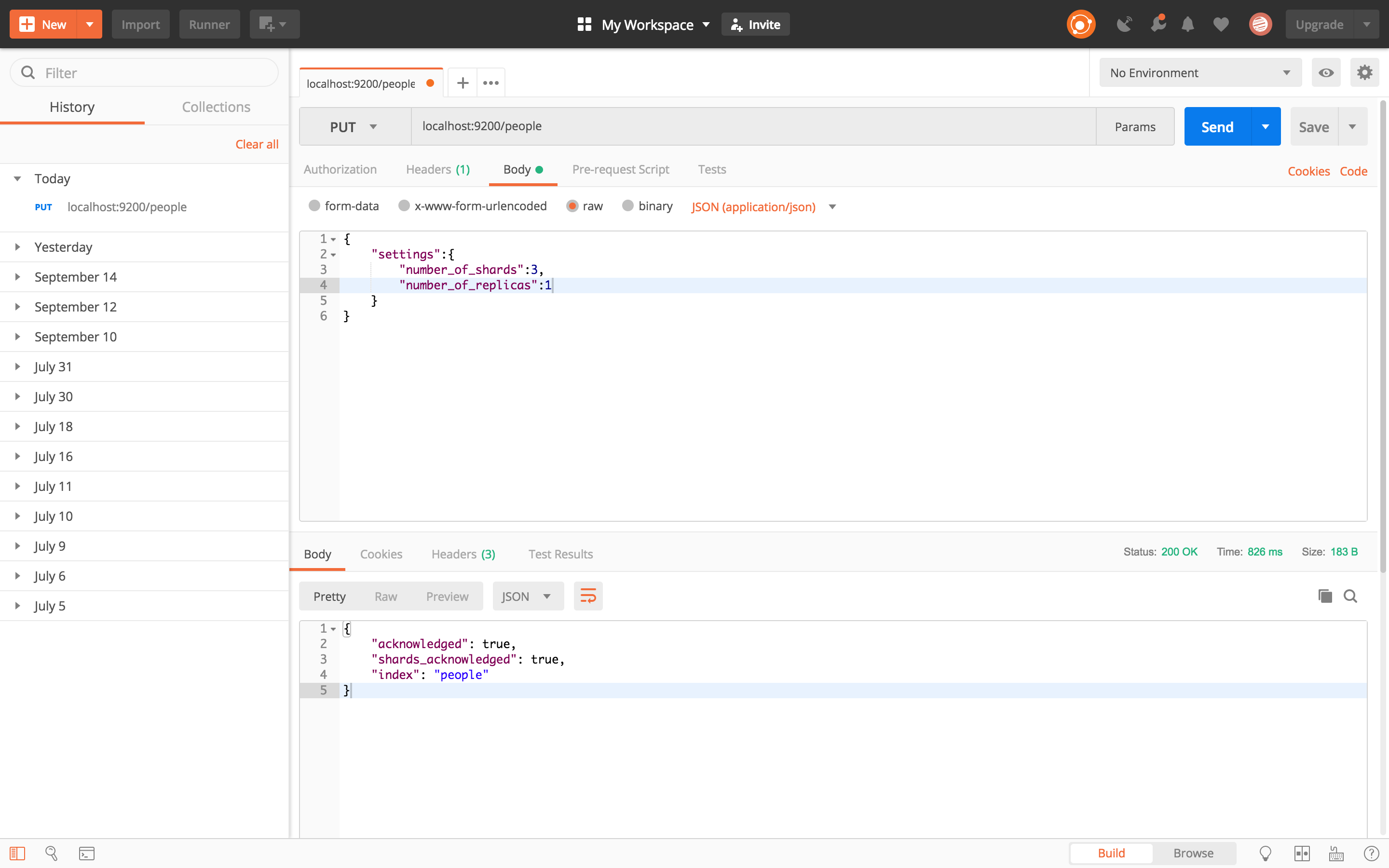
另外发送请求的content-type一定得是application/json,这个值得注意,成功后,会返回一个属性acknowledged 是true的,就说明创建成功,其他的如下图(Tips:几个更换 json体,这里的截图只是一个示范):
查看head插件,如下图
我们可以看到这里创建了三个分片(细线为粗线的副本)。
2.插入文档
| url地址 |
method |
用途 |
| localhost:9200/索引名称/类型名称/文档id |
put |
创建文档(指定文档id) |
| localhost:9200/索引名称/类型名称 |
post |
创建文档(随机文档id) |
3.修改文档
| url地址 |
method |
用途 |
| localhost:9200/索引名称/类型名称/文档id/_update |
post |
修改文档 |
json体:
{
"doc":{
"修改字段名称": "想要修改成的值"
}
}
4.删除文档
| url地址 |
method |
用途 |
| localhost:9200/索引名称/类型名称/文档id |
delete |
删除文档 |
5.查询文档
这里先介绍简单的查询,复杂的地方,会在后面说到。
| url地址 |
method |
用途 |
| localhost:9200/索引名称/类型名称/文档id |
get |
查询文档通过文档id |
| localhost:9200/索引名称/类型名称/_search |
post |
查询所有数据 |
简单查询数据结构体为
{
"query":{
"match_all":{},(通过该属性查询所有数据)
"match":{
"需要查询的字段名称":"查询的值"
}
},
"from": "从第几个开始"(可选),
"size": "要查询多少个"(可选) ,
"sort": [
{"字段名称":{"order": "desc 或者是 asc"}}(自定义排序,默认通过score元字段进行排序)
]
}
聚合查询结构体为:
(可以定义多个聚合条件,放在不同的聚合名称中)
{
"aggs":{
"聚合名称1(自定义)": {
"terms":{
"field": "通过该字段进行聚合"
},
"status":{
"field": "通过该字段进行聚合"(status key可以计算这个聚合的相关参数)
}
},
"聚合名称2(自定义)": {
"terms":{
"field": "通过该字段进行聚合"
}
}
}
}
后记
这篇文章是学习了慕课网上瓦力老师的教程并参考《从lucene到Elasticsearch全文检索实战》所写,课程地址为https://www.imooc.com/learn/889,在此感谢你们的分享,我会在后续的文章中继续总结elasticsearch的更多查询语法,以及Spring Boot 集成 Elastic Search 的相关知识。