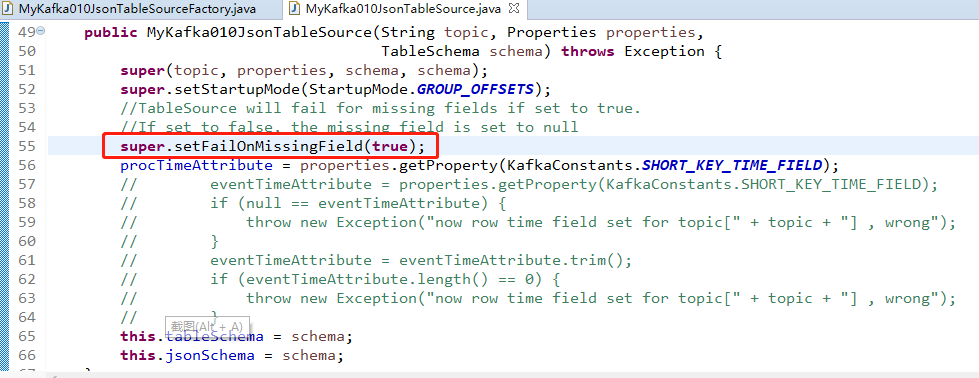
首先,我们故意制造一个异常
![]()
然后,发送一个JSON数据,并且缺失了一些字段,看看报什么错!
顺利抓到调用栈
[2018-11-23 13:24:32,877] INFO Source: MyKafka010JsonTableSource -> from: (pro, throwable, level, ip, SPT) -> where: (AND(IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(level), IS NOT NULL(ip))), select: (pro, throwable, level, ip, SPT) (3/3) (7da5fcb7cd77ff35b64d8bbe367a84d7) switched from RUNNING to FAILED. org.apache.flink.runtime.taskmanager.Task.transitionState(Task.java:927)
java.io.IOException: Failed to deserialize JSON object.
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:97)
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:50)
at org.apache.flink.streaming.util.serialization.KeyedDeserializationSchemaWrapper.deserialize(KeyedDeserializationSchemaWrapper.java:44)
at org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop(Kafka09Fetcher.java:142)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:721)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:87)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:56)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:99)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.IllegalStateException: Could not find field with name 'ip'.
at org.apache.flink.formats.json.JsonRowDeserializationSchema.convertRow(JsonRowDeserializationSchema.java:189)
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:95)
... 10 more
[2018-11-23 13:24:32,877] INFO Source: MyKafka010JsonTableSource -> from: (pro, throwable, level, ip, SPT) -> where: (AND(IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(level), IS NOT NULL(ip))), select: (pro, throwable, level, ip, SPT) (2/3) (f68577aede6953de859c636d9d3b6f3e) switched from RUNNING to FAILED. org.apache.flink.runtime.taskmanager.Task.transitionState(Task.java:927)
java.io.IOException: Failed to deserialize JSON object.
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:97)
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:50)
at org.apache.flink.streaming.util.serialization.KeyedDeserializationSchemaWrapper.deserialize(KeyedDeserializationSchemaWrapper.java:44)
at org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop(Kafka09Fetcher.java:142)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:721)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:87)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:56)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:99)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.IllegalStateException: Could not find field with name 'ip'.
at org.apache.flink.formats.json.JsonRowDeserializationSchema.convertRow(JsonRowDeserializationSchema.java:189)
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:95)
... 10 more
[2018-11-23 13:24:32,877] INFO Source: MyKafka010JsonTableSource -> from: (pro, throwable, level, ip, SPT) -> where: (AND(IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(level), IS NOT NULL(ip))), select: (pro, throwable, level, ip, SPT) (1/3) (8a2c89aa3a2ea8f4c4423c69b22b2522) switched from RUNNING to FAILED. org.apache.flink.runtime.taskmanager.Task.transitionState(Task.java:927)
java.io.IOException: Failed to deserialize JSON object.
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:97)
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:50)
at org.apache.flink.streaming.util.serialization.KeyedDeserializationSchemaWrapper.deserialize(KeyedDeserializationSchemaWrapper.java:44)
at org.apache.flink.streaming.connectors.kafka.internal.Kafka09Fetcher.runFetchLoop(Kafka09Fetcher.java:142)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:721)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:87)
at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:56)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.run(SourceStreamTask.java:99)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:306)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:703)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.IllegalStateException: Could not find field with name 'ip'.
at org.apache.flink.formats.json.JsonRowDeserializationSchema.convertRow(JsonRowDeserializationSchema.java:189)
at org.apache.flink.formats.json.JsonRowDeserializationSchema.deserialize(JsonRowDeserializationSchema.java:95)
... 10 more
[2018-11-23 13:24:32,892] INFO Freeing task resources for Source: MyKafka010JsonTableSource -> from: (pro, throwable, level, ip, SPT) -> where: (AND(IS NOT NULL(pro), IS NOT NULL(throwable), IS NOT NULL(level), IS NOT NULL(ip))), select: (pro, throwable, level, ip, SPT) (1/3) (8a2c89aa3a2ea8f4c4423c69b22b2522). org.apache.flink.runtime.taskmanager.Task.run(Task.java:810)
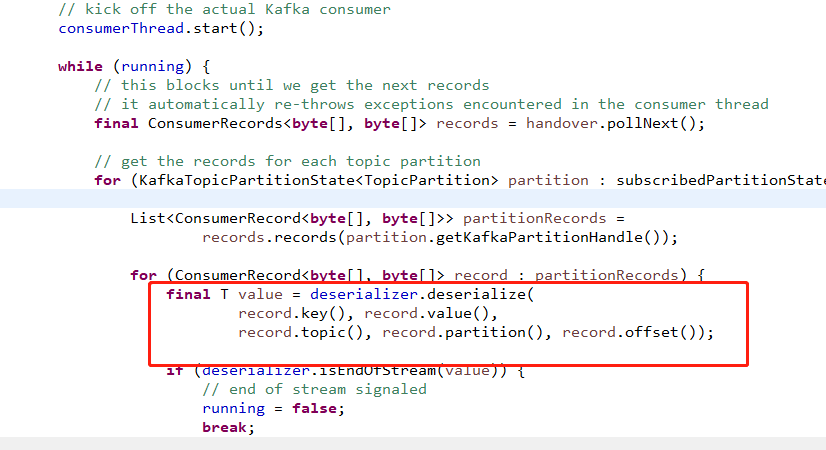
这里只是为了让大家对内部序列化的地点有个印象。
![]()
如果你看懂了,下面进入正题
1)自定义的TableSource中改写
protected FlinkKafkaConsumerBase<Row> createKafkaConsumer(String topic, Properties properties,
DeserializationSchema<Row> deserializationSchema) {
//下面2行本质是一样的,但是因为需要自定义,所以自己返回
//super.createKafkaConsumer(topic, properties, deserializationSchema);
return new FlinkKafkaConsumer010<>(Collections.singletonList(topic),
new MyKeyedDeserializationSchemaWrapper<>(deserializationSchema), properties);
}
2)MyKeyedDeserializationSchemaWrapper.java
package org.apache.flink.api.java.io.kafka;
import java.io.IOException;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.java.typeutils.RowTypeInfo;
import org.apache.flink.streaming.util.serialization.KeyedDeserializationSchemaWrapper;
import org.apache.flink.types.Row;
public class MyKeyedDeserializationSchemaWrapper<T> extends KeyedDeserializationSchemaWrapper<T> {
// private static final org.slf4j.Logger Logger = LoggerFactory
// .getLogger(MyKeyedDeserializationSchemaWrapper.class);
private static final int NOT_FOUND = -1;
/** */
private static final long serialVersionUID = -6984024233082983820L;
//
private static final String KAFKA_TOPIC = "KAFKA_TOPIC";
private int KAFKA_TOPIC_INDEX = NOT_FOUND;
//
private static final String KAFKA_PARTITION = "KAFKA_PARTITION";
private int KAFKA_PARTITION_INDEX = NOT_FOUND;
//
private static final String KAFKA_OFFSET = "KAFKA_OFFSET";
private int KAFKA_OFFSET_INDEX = NOT_FOUND;
//
private boolean inited = false;
public MyKeyedDeserializationSchemaWrapper(DeserializationSchema<T> deserializationSchema) {
super(deserializationSchema);
}
@SuppressWarnings("unchecked")
@Override
public T deserialize(byte[] messageKey, byte[] message, String topic, int partition,
long offset) throws IOException {
Row row = (Row) super.deserialize(messageKey, message, topic, partition, offset);
//只执行1次
if (false == inited) {
RowTypeInfo rowTypeInfo = (RowTypeInfo) super.getProducedType();//Row(pro: String, throwable: String, level: String, ip: String, SPT: Timestamp)
KAFKA_TOPIC_INDEX = rowTypeInfo.getFieldIndex(KAFKA_TOPIC);
KAFKA_PARTITION_INDEX = rowTypeInfo.getFieldIndex(KAFKA_PARTITION);
KAFKA_OFFSET_INDEX = rowTypeInfo.getFieldIndex(KAFKA_OFFSET);
inited = true;
}
//每次都要执行一遍
if (NOT_FOUND != KAFKA_TOPIC_INDEX) {
row.setField(KAFKA_TOPIC_INDEX, topic);
}
if (NOT_FOUND != KAFKA_PARTITION_INDEX) {
row.setField(KAFKA_PARTITION_INDEX, partition);
}
if (NOT_FOUND != KAFKA_OFFSET_INDEX) {
row.setField(KAFKA_OFFSET_INDEX, offset);
}
//返回最终结果
return (T) row;
}
}
测试一把看看效果!
完美!