1.概述
在分布式系统中,负载均衡是一个非常重要的功能,在HBase中通过Region的数量来实现负载均衡,HBase中可以通过hbase.master.loadbalancer.class来实现自定义负载均衡算法。下面将为大家剖析HBase负载均衡的相关内容以及性能指标。
2.内容
在HBase系统中,负载均衡是一个周期性的操作,通过负载均衡来均匀分配Region到各个RegionServer上,通过hbase.balancer.period属性来控制负载均衡的时间间隔,默认是5分钟。触发负载均衡操作是有条件的,但是如果发生如下情况,则不会触发负载均衡操作:
- 负载均衡自动操作balance_switch关闭,即:balance_switch false
- HBase Master节点正在初始化操作
- HBase集群中正在执行RIT,即Region正在迁移中
- HBase集群正在处理离线的RegionServer
2.1 负载均衡算法
HBase在执行负载均衡操作时,如何判断各个RegionServer节点上的Region个数是否均衡,这里通过以下步骤来判断:
- 计算均衡值的区间范围,通过总Region个数以及RegionServer节点个数,算出平均Region个数,然后在此基础上计算最小值和最大值
- 遍历超过Region最大值的RegionServer节点,将该节点上的Region值迁移出去,直到该节点的Region个数小于等于最大值的Region
- 遍历低于Region最小值的RegionServer节点,分配集群中的Region到这些RegionServer上,直到大于等于最小值的Region
- 负责上述操作,直到集群中所有的RegionServer上的Region个数在最小值与最大值之间,集群才算到达负载均衡,之后,即使再次手动执行均衡命令,HBase底层逻辑判断会执行忽略操作
2.2 实例分析
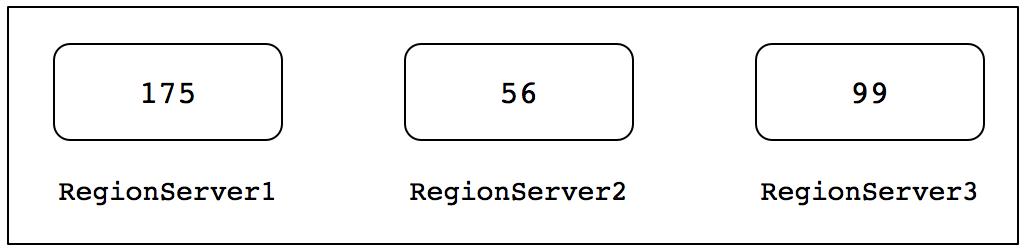
下面笔者通过一个实际的应用场景来给大家剖析HBase负载均衡算法的实现流程。举个例子,假如我们当前有一个5台节点规模的HBase集群(包含Master和RegionServer),其中2台Master和3台RegionServer组成,每台RegionServer上的Region个数,如下图所示。
![]()
在执行负载均衡操作之前,会计算集群中总的Region个数,当前实例中集群中的Region总个数为175+56+99=330。然后计算每个RegionServer需要容纳的Region平均值。计算结果如下:
平均值(110) = 总Region个数(330) / RegionServers总数(3)
计算最小值和最大值来判断HBase集群是否需要进行负载均衡操作,计算公式如下:
# hbase.regions.slop 权重值,默认为0.2
最小值 = Math.floor(平均值 * (1-0.2))
最大值 = Math.ceil(平均值 * (1+0.2))
HBase集群如果判断各个RegionServer中的最小Region个数大于计算后的最小值,并且最大Region个数小于最大值,这是直接返回不会触发负载均衡操作。根据实例中给出的Region数,计算得出最小值Region为88,最大值Region为120。
由于实例中RegionServer2的Region个数为56,小于最小值Region数88,而RegionServer1的Region个数为175,大于了最大值Region数120,所以需要负载均衡操作。
HBase系统有提供管理员命令,来操作负载均衡,具体操作如下:
# 使用hbase shell命令进入到HBase控制台,然后开启自动执行负载均衡
hbase(main):001:0> balance_switch true
这样HBase负载均衡自动操作就开启了,但是,如果我们需要立即均衡集群中的Region个数怎么办?这里HBase也提供了管理命令,通过balancer命令来实现,操作如下:
hbase(main):001:0> balancer
但是,这样每次手动执行,每次均衡的个数不一定能满足要求,那么我们可以通过封装该命令,用脚本来调度执行,具体实现代码如下:
#! /bin/bash
num=$1
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : RegionServer Start Balancer..."
if [ ! -n "$num" ]; then
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Default Balancer 20 Times."
num=20
elif [[ $num == *[!0-9]* ]]; then
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Input [$num] Times Must Be Number."
exit 1
else
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : User-Defined Balancer [$num] Times."
fi
for (( i=1; i<=$num; i++ ))
do
echo "[`date "+%Y-%m-%d %H:%M:%S"`] INFO : Balancer [$i] Times,Total [$num] Times."
echo "balancer"|hbase shell
sleep 5
done
脚本默认执行20次,可以通过输入一个整型参数来自定义执行次数。
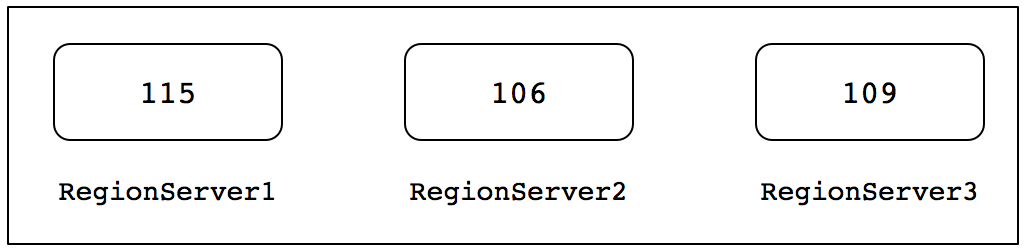
当HBase集群检查完所有的RegionServer上的Region个数已打要求,那么此时集群的负载均衡操作就已经完成了。如果没有达到要求,可以再次执行上述脚本,直到所有的Region个数在最小值和最大值之间为止。当HBase集群中所有的RegionServer完成负载均衡后,实例中的各个RegionServer上的Region个数分布,如下图所示。
![]()
此时,各个RegionServer节点上的Region个数均在最小值和最大值范围内,HBase集群各个RegionServer节点上的Region处理均衡状态。
3.性能指标
在HBase系统中,有一个非常重要的性能指标,那就是集群处理请求的延时。HBase系统为了反应集群内部处理请求所耗费的时间,提供了一个工具类,即:org.apache.hadoop.hbase.tool.Canary,这个类主要用户检查HBase系统的耗时状态。如果不知道使用方法,可以通过help命令来查看具体的用法,命令如下:
hbase org.apache.hadoop.hbase.tool.Canary -help
(1)查看集群中每个表中每个Region的耗时情况
hbase org.apache.hadoop.hbase.tool.Canary
(2)查看money表中每个Region的耗时情况,多个表之间使用空格分割
# 查看money表和person表
hbase org.apache.hadoop.hbase.tool.Canary money person
(3)查看每个RegionServer的耗时情况
hbase org.apache.hadoop.hbase.tool.Canary -regionserver dn1
通常情况下,我们比较关注每个RegionServer节点的耗时情况,将该命令封装一下,然后打印集群中每个RegionServer的耗时情况,脚本实现如下所示:
#########################################################
# 将捕获的RS耗时,写入到InfluxDB中进行存储,用于绘制历史趋势图
#########################################################
#!/bin/bash
post_influxdb_write='http://influxdb:8086/write?db=telegraf_rs'
source /home/hadoop/.bash_profile
for i in `cat rs.list`
do
timespanStr=`(hbase org.apache.hadoop.hbase.tool.Canary -regionserver $i 2>&1) | grep tool.Canary`
timespanMs=`echo $timespanStr|awk -F ' ' '{print $NF}'`
timespan=`echo $timespanMs|awk -F "ms" '{print $1}'`
echo `date +'%Y-%m-%d %H:%M:%S'` INFO : RegionServer $i delay $timespanMs .
currentTime=`date "+%Y-%m-%d %H:%M:%S"`
currentTimeStamp=`date -d "$currentTime" +%s`
insert_sql="regionsever,host=$i value=$timespan ${currentTimeStamp}000000000"
#echo $insert_sql
curl -i -X POST "$post_influxdb_write" --data-binary "$insert_sql"
done
exit
4.总结
在维护HBase集群时,比如重启某几个RegionServer节点后,可能会发送Region不均衡的情况,这时如果开启自动均衡后,需要立即使当前集群上其他RegionServer上的Region处于均衡状态,那么就可以使用手动均衡操作。另外,HBase集群中各个RegionServer的耗时情况,能够反映当前集群的健康状态。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。
作者:哥不是小萝莉 [关于我][犒赏]
转载请注明出处,谢谢合作!