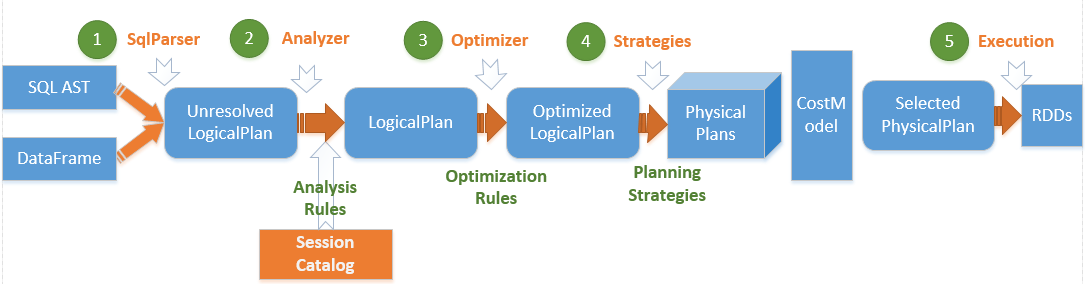

Spark的那些外部框架
Spark Package 要使用Spark库,你首先必须了解的东西是Spark package。它有点像Spark的包管理器。当你给Spark集群提交job时,你可以到存放Spark package的网站下载任何package。所有package都存放在这个站点。http://spark-packages.org/当你想用一个Spark package时,可以在spark-submit命令或者spark- shell命令中增加包选项: $ $Spark_HOME/bin/Spark-shell \ -packages com.databricks:Spark-avro_2.10:2.0.1 如果使用了--packages选项,Spark package就会自动把它的JAR包添加到你指定的路径下。你不仅能在Spark集群上使用社区的库,还能到公开发布自己的库。如果要把一个Spark package发布到这个托管服务下,必须遵守下列规则: 源代码必须放在Github上。 代码库的名字必须与包名相同。 代码库的主分支必须有README.md文件,在根目录下必须有LICENSE文件。 换句话...