目录
webpack作为前端最火的构建工具,是前端自动化工具链最重要的部分,使用门槛较高。本系列是笔者自己的学习记录,比较基础,希望通过问题 + 解决方式的模式,以前端构建中遇到的具体需求为出发点,学习webpack工具中相应的处理办法。(本篇中的参数配置及使用方式均基于webpack4.0版本)
本篇摘要:
本篇主要介绍基于webpack4.0的splitChunks分包技术。
![img_60140e31006b5776c5560aeedc0c6988.png]()
![img_d6e7802c9640264835a13b85429f5a6a.png]()
一. Js模块化开发
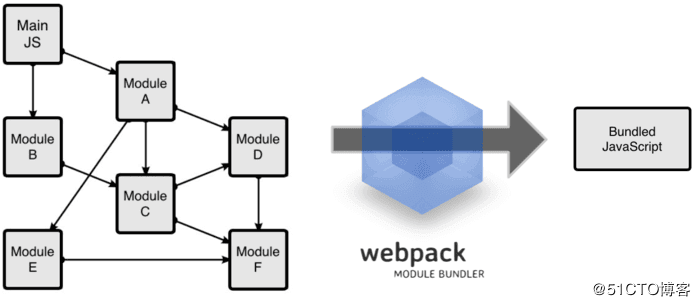
javascript之所以需要打包合并,是因为模块化开发的存在。开发阶段我们需要将js文件分开写在很多零碎的文件中,方便调试和修改,但如果就这样上线,那首页的http请求数量将直接爆炸。同一个项目,别人2-3个请求就拿到了需要的文件,而你的可能需要20-30个,结果就不用多说了。
但是合并脚本可不是“把所有的碎片文件都拷贝到一个js文件里”这样就能解决的,不仅要解决命名空间冲突的问题,还需要兼容不同的模块化方案,更别提根据模块之间复杂的依赖关系来手动确定模块的加载顺序了,所以利用自动化工具来将开发阶段的js脚本碎片进行合并和优化是非常有必要的。
二. Js文件的一般打包需求
- 代码编译(
TS或ES6代码的编译)
- 脚本合并
- 公共模块识别
- 代码分割
- 代码压缩混淆
三. 使用webpack处理js文件
3.1 使用babel转换ES6+语法
babel是ES6语法的转换工具,对babel不了解的读者可以先阅读《大前端的自动化工厂(3)——Babel》一文进行了解,babel与webpack结合使用的方法也在其中做了介绍,此处仅提供基本配置:
webpack.config.js:
...
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: [
{
loader: 'babel-loader'
}
]
}
]
},
...
.babelrc:
{
"presets":[
["env",{
"targets":{
"browsers":"last 2 versions"
}
}
]],
"plugins": [
"babel-plugin-transform-runtime"
]
}
3.2 脚本合并
使用webpack对脚本进行合并是非常方便的,毕竟模块管理和文件合并这两个功能是webpack最初设计的主要用途,直到涉及到分包和懒加载的话题时才会变得复杂。webpack使用起来很方便,是因为实现了对各种不同模块规范的兼容处理,对前端开发者来说,理解这种兼容性实现的方式比学习如何配置webpack更为重要。webpack默认支持的是CommonJs规范,但同时为了扩展其使用场景,webpack在后续的版本迭代中也加入了对ES harmony等其他规范定义模块的兼容处理,具体的处理方式将在下一章《webpack4.0各个击破(5)—— Module篇》详细分析。
3.3 公共模块识别
webpack的输出的文件中可以看到如下的部分:
/******/ function __webpack_require__(moduleId) {
/******/
/******/ // Check if module is in cache
/******/ if(installedModules[moduleId]) {
/******/ return installedModules[moduleId].exports;
/******/ }
/******/ // Create a new module (and put it into the cache)
/******/ var module = installedModules[moduleId] = {
/******/ i: moduleId,
/******/ l: false,
/******/ exports: {}
/******/ };
/******/
/******/ // Execute the module function
/******/ modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
/******/
/******/ // Flag the module as loaded
/******/ module.l = true;
/******/
/******/ // Return the exports of the module
/******/ return module.exports;
/******/ }
上面的__webpack_require__( )方法就是webpack的模块加载器,很容易看出其中对于已加载的模块是有统一的installedModules对象来管理的,这样就避免了模块重复加载的问题。而公共模块一般也需要从bundle.js文件中提取出来,这涉及到下一节的“代码分割”的内容。
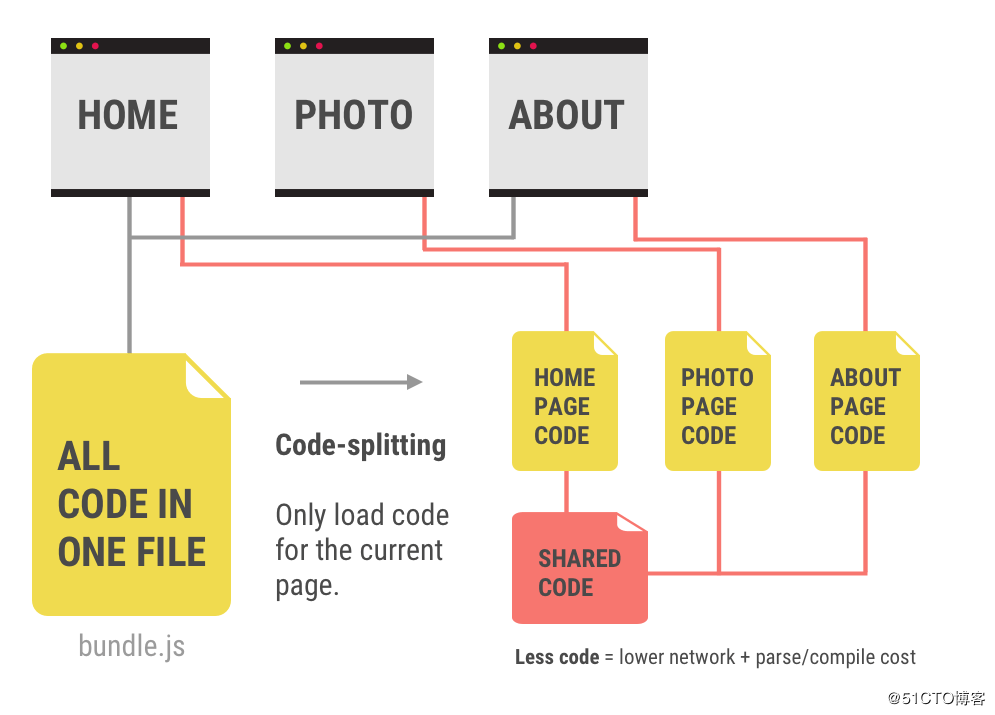
3.4 代码分割
![img_e24331e7bb9829ca805888854ce7437f.png]()
1. 为什么要进行代码分割?
代码分割最基本的任务是分离出第三方依赖库,因为第三方库的内容可能很久都不会变动,所以用来标记变化的摘要哈希contentHash也很久不变,这也就意味着我们可以利用本地缓存来避免没有必要的重复打包,并利用浏览器缓存避免冗余的客户端加载。另外当项目发布新版本时,如果第三方依赖的contentHash没有变化,就可以使用客户端原来的缓存文件(通用的做法一般是给静态资源请求设置一个很大的max-age),提升访问速度。另外一些场景中,代码分割也可以提供对脚本在整个加载周期内的加载时机的控制能力。
2. 代码分割的使用场景
举个很常见的例子,比如你在做一个数据可视化类型的网站,引用到了百度的Echarts作为第三方库来渲染图表,如果你将自己的代码和Echarts打包在一起生成一个main.bundle.js文件,这样的结果就是在一个网速欠佳的环境下打开你的网站时,用户可能需要面对很长时间的白屏,你很快就会想到将Echarts从主文件中剥离出来,让体积较小的主文件先在界面上渲染出一些动画或是提示信息,然后再去加载Echarts,而分离出的Echarts也可以从速度更快的CDN节点获取,如果加载某个体积庞大的库,你也可以选择使用懒加载的方案,将脚本的下载时机延迟到用户真正使用对应的功能之前。这就是一种人工的代码分割。
从上面的例子整个的生命周期来看,我们将原本一次就可以加载完的脚本拆分为了两次,这无疑会加重服务端的性能开销,毕竟建立TCP连接是一种开销很大的操作,但这样做却可以换来对渲染节奏的控制和用户体验的提升,异步模块和懒加载模块从宏观上来讲实际上都属于代码分割的范畴。code splitting最极端的状况其实就是拆分成打包前的原貌,也就是源码直接上线。
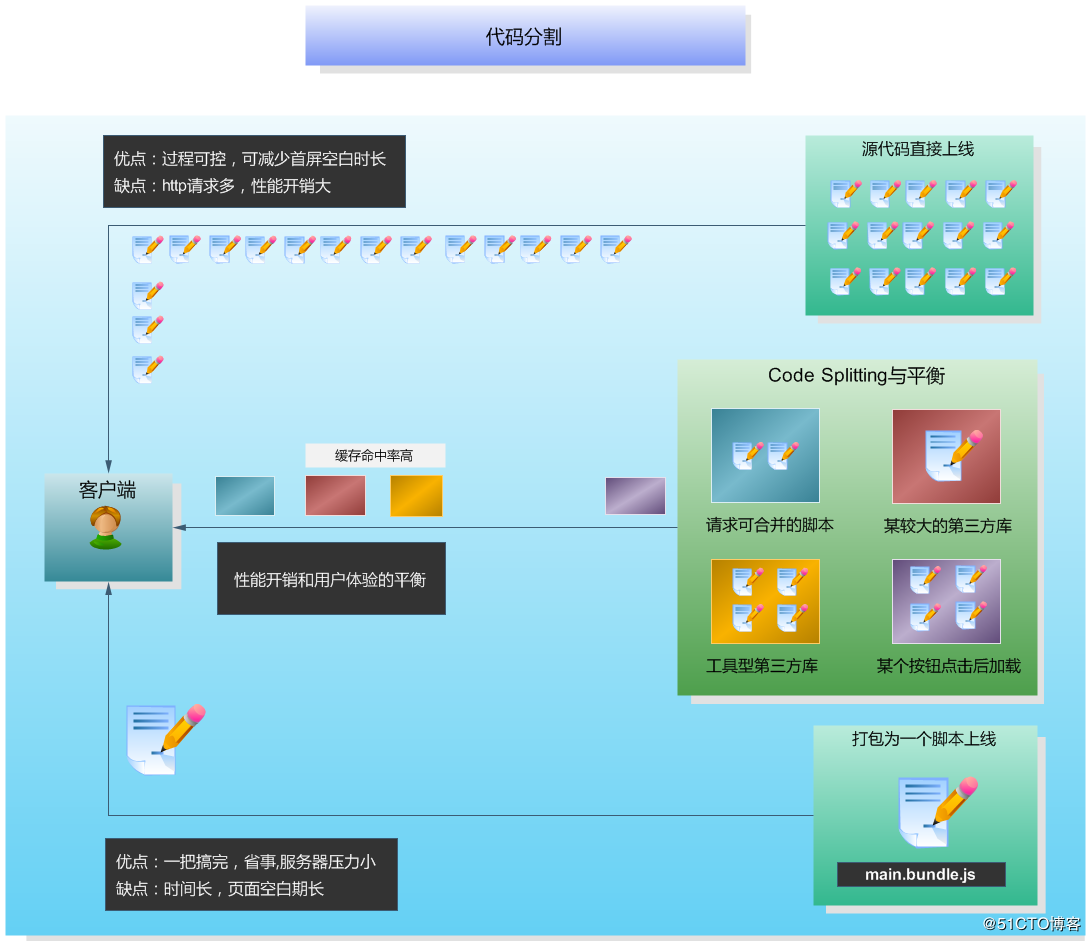
3. 代码分割的本质
![img_13dabb3d353d67e4a955ba222c419cfd.png]()
代码分割的本质,就是在“源码直接上线”和“打包为唯一的脚本main.bundle.js”这两种极端方案之间寻找一种更符合实际场景的中间状态,用可接受的服务器性能压力增加来换取更好的用户体验。
4. 配置代码分割
code-splitting技术的配置和使用方法将在下一小节详细描述。
5. 更细致的代码分割
感兴趣的读者可以参考来自google开发者社区的文章《Reduce JavaScript Payloads with Code Splitting》自行研究。
3.5 代码混淆压缩
webpack4中已经内置了UglifyJs插件,当打包模式参数mode设置为production时就会自动开启,当然这不是唯一的选择,babel的插件中也能提供代码压缩的处理,具体的效果和原理笔者尚未深究,感兴趣的读者可以自行研究。
四. 细说splitChunks技术
4.1 参数说明
webpack4废弃了CommonsChunkPlugin插件,使用optimization.splitChunks和optimization.runtimeChunk来代替,原因可以参考《webpack4:连奏中的进化》一文。关于runtimeChunk参数,有的文章说是提取出入口chunk中的runtime部分,形成一个单独的文件,由于这部分不常变化,可以利用缓存。google开发者社区的博文是这样描述的:
The runtimeChunk option is also specified to move webpack's runtime into the vendors chunk to avoid duplication of it in our app code.
splitChunks中默认的代码自动分割要求是下面这样的:
-
node_modules中的模块或其他被重复引用的模块
就是说如果引用的模块来自node_modules,那么只要它被引用,那么满足其他条件时就可以进行自动分割。否则该模块需要被重复引用才继续判断其他条件。(对应的就是下文配置选项中的minChunks为1或2的场景)
-
分离前模块最小体积下限(默认30k,可修改)
30k是官方给出的默认数值,它是可以修改的,上一节中已经讲过,每一次分包对应的都是服务端的性能开销的增加,所以必须要考虑分包的性价比。
-
对于异步模块,生成的公共模块文件不能超出5个(可修改)
触发了懒加载模块的下载时,并发请求不能超过5个,对于稍微了解过服务端技术的开发者来说,【高并发】和【压力测试】这样的关键词应该不会陌生。
-
对于入口模块,抽离出的公共模块文件不能超出3个(可修改)
也就是说一个入口文件的最大并行请求默认不得超过3个,原因同上。
4.2 参数配置
splitChunks的在webpack4.0以上版本中的用法是下面这样的:
module.exports = {
//...
optimization: {
splitChunks: {
chunks: 'async',//默认只作用于异步模块,为`all`时对所有模块生效,`initial`对同步模块有效
minSize: 30000,//合并前模块文件的体积
minChunks: 1,//最少被引用次数
maxAsyncRequests: 5,
maxInitialRequests: 3,
automaticNameDelimiter: '~',//自动命名连接符
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
minChunks:1,//敲黑板
priority: -10//优先级更高
},
default: {
test: /[\\/]src[\\/]js[\\/]/
minChunks: 2,//一般为非第三方公共模块
priority: -20,
reuseExistingChunk: true
}
},
runtimeChunk:{
name:'manifest'
}
}
}
4.3 代码分割实例
注:实例中使用的demo及配置文件已放在附件中。
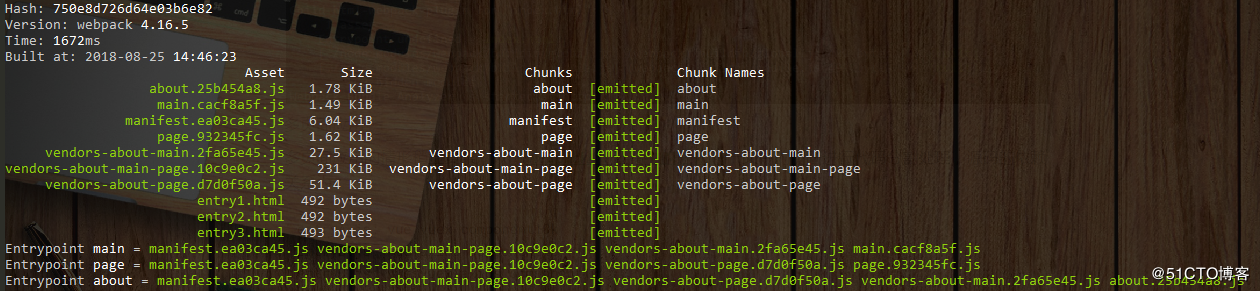
![img_85d068d31cd6bd602b427447ce02f6f4.png]()
![img_af8e5606721699a658d22e9b30869dc6.png]()
splitChunks提供了更精确的分割策略,但是似乎无法直接通过html-webpack-plugin配置参数来动态解决分割后代码的注入问题,因为分包名称是不确定的。这个场景在使用chunks:'async'默认配置时是不存在的,因为异步模块的引用代码是不需要以<script>标签的形式注入html文件的。
当chunks配置项设置为all或initial时,就会有问题,例如上面示例中,通过在html-webpack-plugin中配置excludeChunks可以去除page和about这两个chunk,但是却无法提前排除vendors-about-page这个chunk,因为打包前无法知道是否会生成这样一个chunk。这个场景笔者并没有找到现成的解决方案,对此场景有需求的读者也许可以通过使用html-webpack-plugin的事件扩展来处理此类场景,也可以使用折中方案,就是第一次打包后记录下新生成的chunk名称,按需填写至html-webpack-plugin的chunks配置项里。
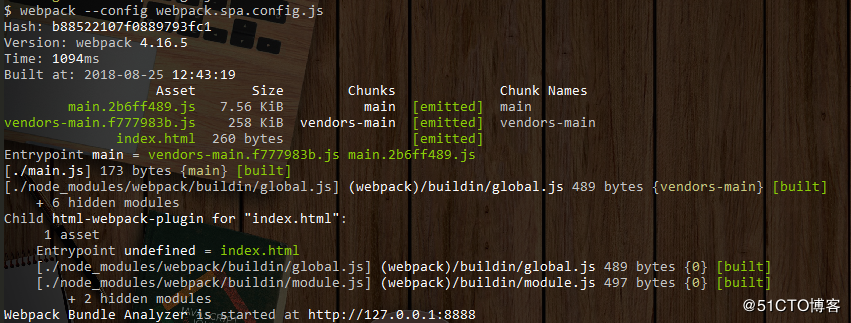
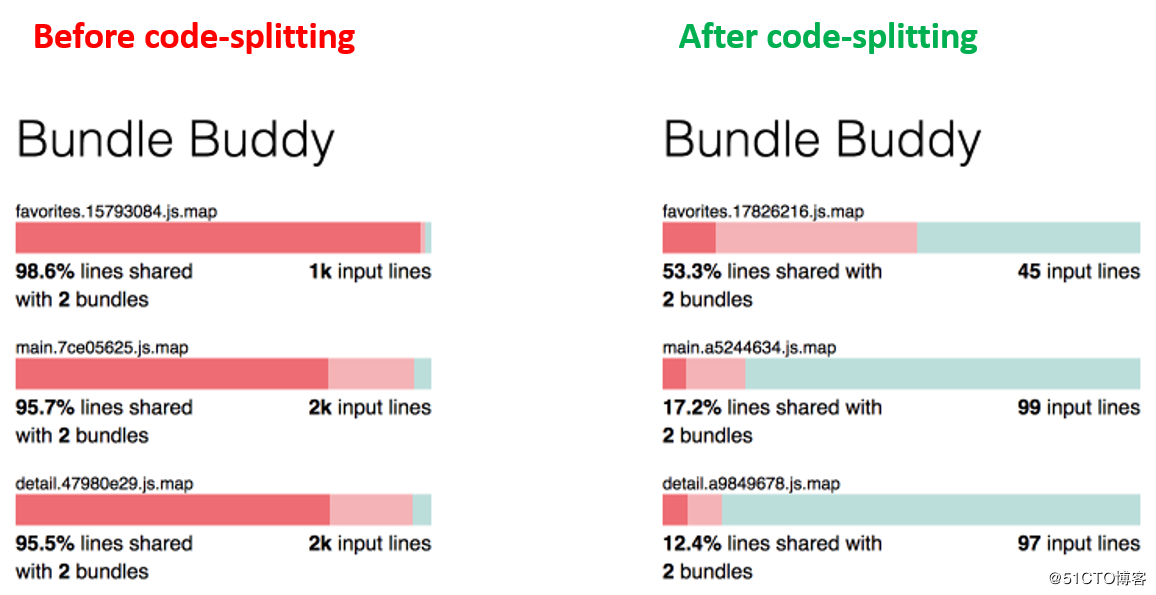
### 4.4 结果分析
通过Bundle Buddy分析工具或webpack-bundle-analyser插件就可以看到分包前后对于公共代码的抽取带来的影响(图片来自参考文献的博文):
![img_39ab17224a41a6f4e2c51bd044274a14.png]()
五. 参考及附件说明
【1】附加中文件说明:
-
webpack.spa.config.js——单页面应用代码分割配置实例
-
main.js——单页面应用入口文件
-
webpack.multi.config.js——多页面应用代码分割配置实例
-
entryA.js,entryB.js,entryC.js——多页面应用的3个入口
【2】参考文献: 《Reduce JavaScript Payloads with Code Splitting》