开篇
写TreeMap本身是一件让我感到无比怂逼的事情,因为红黑树的数据结构从大学到现在我就没弄明白过,估计在很长的一段时间里应该也弄不明白,不过我打算投入点时间去研究研究红黑树了。
后来查看了下网上关于讲解TreeMap的文章,发现避开红黑树直接直接将它当做黑盒来讲的思路貌似也是可行的,所以我打算也从这个角度来写这个文章。
TreeMap的特性
- TreeMap 是有序的,按照自然排序或者指定比较器排序,不允许 null 键,允许 null 值,是不同步。
- TreeMap 是基于红黑树实现的最大的好处就是可以按照业务场景得到已排序的结果。
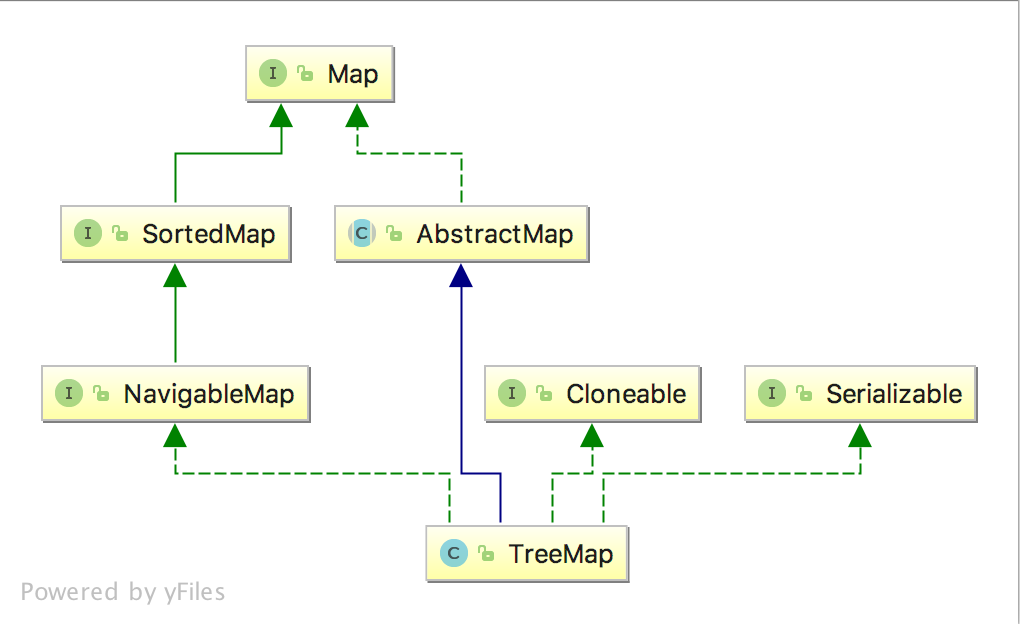
TreeMap类图
说明:
TreeMap实现了SortedMap接口并集成了AbstractMap,这些其实我并没有深究,只是想说明的是TreeMap是有序的。
TreeMap源码分析系列
TreeMap类成员变量
TreeMap的核心数据结构当中,主要是root的数据节点,主要是用于标识红黑树的根节点。
TreeMap的Entry就是用于保存Map的key/value数据结构,除了常见的key/value变量外,还有TreeMap特有的left指针,right指针,parent指针。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
// 比较器对象
private final Comparator<? super K> comparator;
// 根节点
private transient Entry<K,V> root;
// 集合大小
private transient int size = 0;
// 树结构被修改的次数
private transient int modCount = 0;
// 静态内部类用来表示节点类型
static final class Entry<K,V> implements Map.Entry<K,V> {
K key; // 键
V value; // 值
Entry<K,V> left; // 指向左子树的引用(指针)
Entry<K,V> right; // 指向右子树的引用(指针)
Entry<K,V> parent; // 指向父节点的引用(指针)
boolean color = BLACK;
}
TreeMap的构造函数
// 无参构造方法
public TreeMap() {
// 默认比较机制,也就是key对象自带的比较机制
comparator = null;
}
// 自定义比较器的构造方法
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
// 构造已知Map对象为TreeMap
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null; // 默认比较机制
putAll(m);
}
// 构造已知的SortedMap对象为TreeMap
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator(); // 使用已知对象的构造器
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
TreeMap的put方法
典型的使用红黑树的方法,通过比较器comparator的比较来维持全局有序,每次插入红黑树之后需要重新执行fixAfterInsertion来平衡红黑树。
public V put(K key, V value) {
Entry<K,V> t = root;
// 如果根节点为空也就是整个TreeMap为空的情况,走默认check检查key是否为null
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
Comparator<? super K> cpr = comparator;
// 如果比较器对象不为空,也就是自定义了比较器
if (cpr != null) {
do { // 循环比较并确定元素应插入的位置(也就是找到该元素的父节点)
parent = t; //parent代表新增节点应该保存的父节点
// 调用比较器对象的compare()方法,该方法返回一个整数
cmp = cpr.compare(key, t.key);
if (cmp < 0) // 待插入元素的key"小于"当前位置元素的key,则查询左子树
t = t.left;
else if (cmp > 0) // 待插入元素的key"大于"当前位置元素的key,则查询右子树
t = t.right;
else
return t.setValue(value); // "相等"则替换其value。
} while (t != null);
}
// 如果比较器对象为空,使用默认的比较机制
else {
if (key == null) //不支持key为null的情况
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key; // 取出比较器对象
do {// 同样是循环比较并确定元素应插入的位置(也就是找到该元素的父节点)
parent = t;
cmp = k.compareTo(t.key); // 调用比较方法并返回一个整数
if (cmp < 0) // 待插入元素的key"小于"当前位置元素的key,则查询左子树
t = t.left;
else if (cmp > 0) // 待插入元素的key"大于"当前位置元素的key,则查询右子树
t = t.right;
else
return t.setValue(value); // "相等"则替换其value
} while (t != null);
}
// 根据key找到父节点后新建一个节点
Entry<K,V> e = new Entry<>(key, value, parent);
// 根据比较的结果来确定放在左子树还是右子树
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 重新维持红黑树的平衡
fixAfterInsertion(e);
// 集合大小+1
size++;
// 集合结构被修改次数+1
modCount++;
return null;
}
TreeMap的get相关方法
TreeMap的get相关方法说白了就是在TreeMap是二叉平衡树的基础上进行比较查询的,比当前key小就查找左子树,比当前key大就查找右子树,如果相等就说明找到了。
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
// 如果有比较器,那么就用比较器
if (comparator != null)
return getEntryUsingComparator(key);
// 如果没有比较器,那么就用key自带的比较器进行比较
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
// 由于TreeMap本身就是一个有序的二叉树,所以直接通过二飞查找就可以了
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
// 同样通过二分查找就可以了
final Entry<K,V> getEntryUsingComparator(Object key) {
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
Entry<K,V> p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
}
return null;
}
firstKey()方法就是采用二叉平衡树的特性获取最左子树的值。
public K firstKey() {
return key(getFirstEntry());
}
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
lastKey()方法就是采用二叉平衡树的特性获取最右子树的值。
public K lastKey() {
return key(getLastEntry());
}
final Entry<K,V> getLastEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.right != null)
p = p.right;
return p;
}
pollFirstEntry和pollLastEntry说白了也是TreeMap是二叉平衡树的基础上直接查找最左子树或查找最右子树返回结果。
public Map.Entry<K,V> pollFirstEntry() {
Entry<K,V> p = getFirstEntry();
Map.Entry<K,V> result = exportEntry(p);
if (p != null)
deleteEntry(p);
return result;
}
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
public Map.Entry<K,V> pollLastEntry() {
Entry<K,V> p = getLastEntry();
Map.Entry<K,V> result = exportEntry(p);
if (p != null)
deleteEntry(p);
return result;
}
final Entry<K,V> getLastEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.right != null)
p = p.right;
return p;
}
TreeMap的Iterator相关方法
TreeMap的iterator方法其实就是按照平衡二叉树的左中右的顺序进行迭代遍历的,具体来说就是先遍历左子树,然后遍历父节点,最后遍历右子树。
遍历过程中successor函数比较关键,相关注释已写明
public Set<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet());
}
class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator(getFirstEntry());
}
}
final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> {
EntryIterator(Entry<K,V> first) {
super(first);
}
public Map.Entry<K,V> next() {
return nextEntry();
}
}
abstract class PrivateEntryIterator<T> implements Iterator<T> {
Entry<K,V> next;
Entry<K,V> lastReturned;
int expectedModCount;
PrivateEntryIterator(Entry<K,V> first) {
expectedModCount = modCount;
lastReturned = null;
next = first;
}
public final boolean hasNext() {
return next != null;
}
// 遍历的核心在于successor()方法,遍历顺序是二叉树的中序遍历法
final Entry<K,V> nextEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = successor(e);
lastReturned = e;
return e;
}
final Entry<K,V> prevEntry() {
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = predecessor(e);
lastReturned = e;
return e;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
// deleted entries are replaced by their successors
if (lastReturned.left != null && lastReturned.right != null)
next = lastReturned;
deleteEntry(lastReturned);
expectedModCount = modCount;
lastReturned = null;
}
}
// successor的逻辑其实就是中序遍历的逻辑
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
// 如果右子树不为空,那么就找到右子树的最左子树
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
// 如果右子树为空,那么就找父节点,因为中序遍历是左中右
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
// 如果该节点刚好是父节点的右子节点,
// 那么就证明父节点的右子树遍历完毕且本身也遍历完毕,
// 那么就继续往上找父节点
ch = p;
p = p.parent;
}
return p;
}
}
参考文献
教你初步了解红黑树