上周末搬家后,家里的宽带一直没弄好,跟电信客服反映了N遍了终于约了个师傅明天早上来迁移宽带,可以结束一个多星期没网的痛苦日子了。这段时间也是各种忙,都一个星期没更新博客了,再不写之前那种状态和激情都要慢慢褪去了,总觉得心里慌的一逼,这怎么行呢?!趁明天周末,在公司电脑上记录下这周的一些学习内容。近期在看一本很经典的java书籍:《深入理解java虚拟机 第二版》,几年前也翻过,但那时候功力不够,不太能看懂就没看了。现在回过头来看,发现确实写的很好,很多知识点都能理解了,而且讲的也很有深度,收获颇多。后期计划按照这本书的内容写出一系列博客,来深入学习和复习下java虚拟机相关的知识。
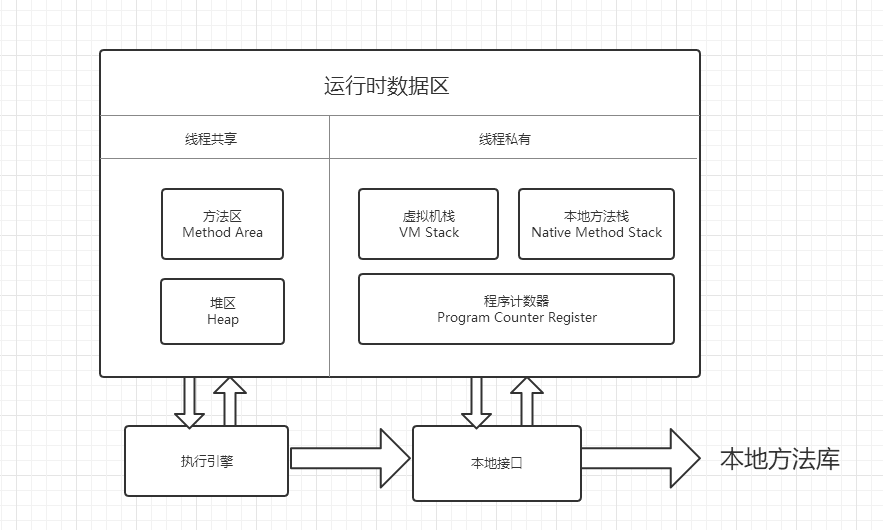
一、JVM内存模型概述
JVM内存模型其实也挺简单的,这里先提2个知识点:
1、组成:java堆,java栈(即虚拟机栈),本地方法栈,方法区和程序计数器。
2、是否共享:其中方法区和堆区是线程共享的,虚拟机栈,本地方法栈和程序计数器是线程私有的,也称线程隔离的,每个区域存储不同的内容。这2个知识点必须牢记,是掌握JVM内存模型的基础。
![]()
二、程序计数器
JVM中的程序计数器是一块很小的内存区域,但是这块内存区域挺有意思的。主要特性有3个:
1、存储内容:对于java普通方法(即没用native关键字修饰的方法),存储的是执行过程中当前指令的地址,而对于native方法,这里是空的(undefined),为啥呢?因为调用本地方法的时候可能已经超出了JVM虚拟机的内存地址了。
2、线程私有的:为什么程序计数器是线程私有的?根据存储内容也好理解,假如是线程共享的,那多个线程执行的时候,都不知道自己当前线程执行的地址是哪个了,有的线程快,有的线程慢,快的执行完就进入下一步,等慢的线程执行完回来发现自己的地址都变了,岂不乱套?
3、是JVM中唯一不会报内存溢出(OutOfMemoryError)的区域。
三、虚拟机栈
虚拟机栈主要存储的是一个个栈帧,每个栈帧中存储的是局部变量表,操作数栈,动态链接和方法出口信息等。其中局部变量表中存储的是方法中定义的一些局部变量,对象的引用,参数,和方法的返回地址等。局部变量表所占用的空间大小在编译期就能确定,在方法运行的时候,并不会改变局部变量表的空间大小,这结合局部变量表存储的内容就很好理解。操作数栈可以理解为对当前操作的数据入出栈,对于64位长度的long和double类型,每个操作数占用2个字宽(slot),其他类型的操作数占用一个字宽(slot)。每个方法调用时都会创建一个栈帧,执行的过程对应的就是一个栈帧在虚拟机栈中从入栈到出栈的过程。有关栈帧的内容可以参考一个网友写的一篇博客:https://blog.csdn.net/xtayfjpk/article/details/41924283,讲的很好很详细。这里放个栈帧的图,看了一目了然。
![]()
关于虚拟机栈内存溢出有2种情况:
1、线程请求的栈深度 超过了虚拟机允许的深度,会抛出StackOverflowError,所以当我们在代码中看到这个异常时,就应该想到可能是虚拟机栈出了问题。
2、如果虚拟机栈可以动态扩展(当前大部分JVM都可以动态扩展,不过JVM也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时,会抛出OutOfMemoryError异常。
四、本地方法栈
这块知识点比较简单,本地方法栈和虚拟机栈的功能类似,只不过是为JVM调用native方法时服务的,而且JVM对本地方法使用的语言(比如Java调用C语言实现的功能,就需要定义native方法来实现)、使用方式和数据结构都没有强制规定,因此不同的虚拟机可以自由实现。而且HotSpot虚拟机直接把本地方法栈和虚拟机栈合二为一。与虚拟机栈类似,本地方法栈也会抛出StackOverflowError和OutOfMemoryError。
五、方法区
方法区是一个比较重要的区域,java虚拟机规范中把方法区描述为堆的一个逻辑部分,但是为了和Heap(堆区)对应,也称Non-Heap(非堆区)。主要存储的是静态变量,常量(包括运行时常量),类的加载信息和java编译后的代码。这部分空间不需要连续,可以选择固定大小和可扩展,通常在这部分是没有GC的,因为GC回收的都是些静态变量,常量和类的加载信息,这些对象回收效果通常不尽人意,因此可以选择不实现垃圾回收。这块区域也称为持久代,当这块内存不足时,也会报OutOfMemoryError异常。
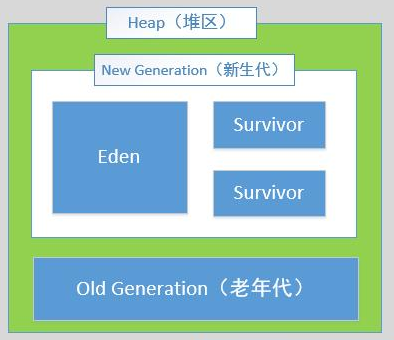
六、堆区
Java堆区是JVM内存中最胖的一块区域,因为这里存储的都是对象的实例和数组对象。这块区域是线程共享的,在JVM启动时就会创建,想想如果这么大的空间是线程私有的,那内存不得爆掉吗?按照java虚拟机规范,堆区的内容可以物理上不连续,只要逻辑上连续即可,在实现时可以是固定大小的,也可以是可扩展的,而且通常都是可扩展的,我们常用的内存参数-Xms和-Xmx就是用来调节堆大小的。java堆区按生命周期不同,分为新生代和老年代。新生代又可以细分为Eden和Survivor区,而Survivor又可以细分为Survivor1和Survivor2,这两者通常只使用其中一块,另一块用来GC时保留存活的对象。大部分的new出来的对象都是存放在Eden区,如果是大对象,比如一个很大的数组或者List对象,可以通过JVM参数-XX:PretenureSizeThreshold将超过指定大小的对象直接存入到老年代,需要注意的是,写程序时应该尽量避免朝生夕死的大对象进入老年代,因为相比年轻代的GC,老年代GC的成本更大。Eden和Survivor的默认大小比值的8:1:1,新生代默认的GC算法是复制算法。老年代的默认GC算法是标记整理法。关于这2种GC算法,会在下篇博客讲解。
当堆中没有足够内存时,会抛出OutOfMemoryError异常。关于堆区的内存模型,可以参考下面的图片:
![]()