Scrapy的架构太重要了,单用一篇文章再总结整合下。前两张图来自《Learning Scrapy》,第三张图来自Scrapy 1.0中文官方文档(该中文文档只到1.0版),第四张图来自Scrapy 1.4英文官方文档(最新版),是我翻译的。
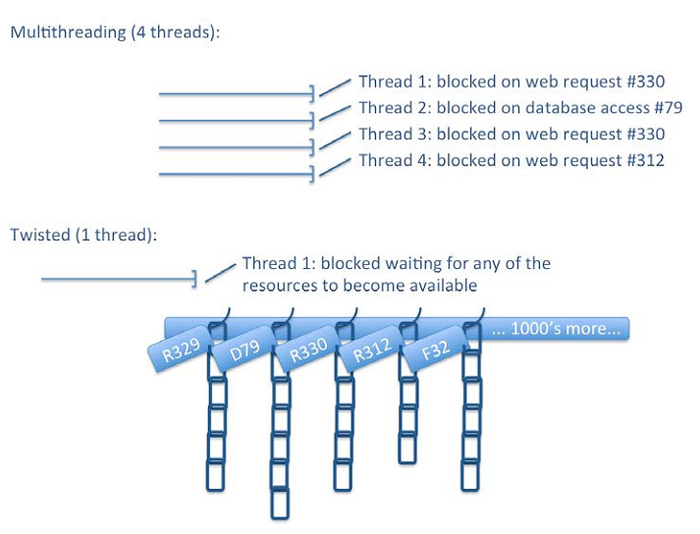
一、Scrapy的Twisted引擎模型
这里重要的概念是单线程、NIO、延迟项和延迟链。
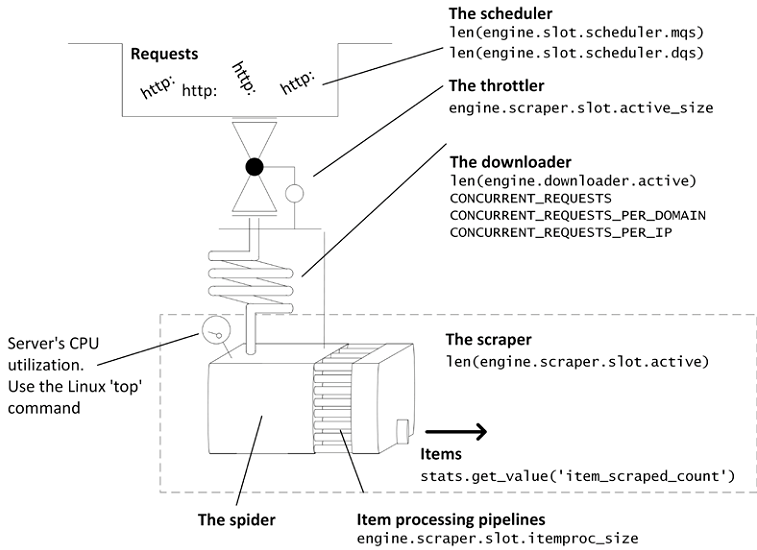
二、Scrapy的性能模型
Scrapy包括以下部分:
- 调度器:大量的Request在这里排队,直到下载器处理它们。其中大部分是URL,因此体积不大,也就是说即便有大量请求存在,也可以被下载器及时处理。
- 阻塞器:这是抓取器由后向前进行反馈的一个安全阀,如果进程中的响应大于5MB,阻塞器就会暂停更多的请求进入下载器。这可能会造成性能的波动。
- 下载器:这是对Scrapy的性能最重要的组件。它用复杂的机制限制了并发数。它的延迟(管道长度)等于远程服务器的响应时间,加上网络/操作系统、Python/Twisted的延迟。我们可以调节并发请求数,但是对其它延迟无能为力。下载器的能力受限于CONCURRENT_REQUESTS*设置。
- 爬虫:这是抓取器将Response变为Item和其它Request的组件。只要我们遵循规则来写爬虫,通常它不是瓶颈。
- Item Pipelines:这是抓取器的第二部分。我们的爬虫对每个Request可能产生几百个Items,只有CONCURRENT_ITEMS会被并行处理。这一点很重要,因为,如果你用pipelines连接数据库,你可能无意地向数据库导入数据,pipelines的默认值(100)就会看起来很少。
爬虫和pipelines的代码是异步的,会包含必要的延迟,但二者不会是瓶颈。爬虫和pipelines很少会做繁重的处理工作。如果是的话,服务器的CPU则是瓶颈。
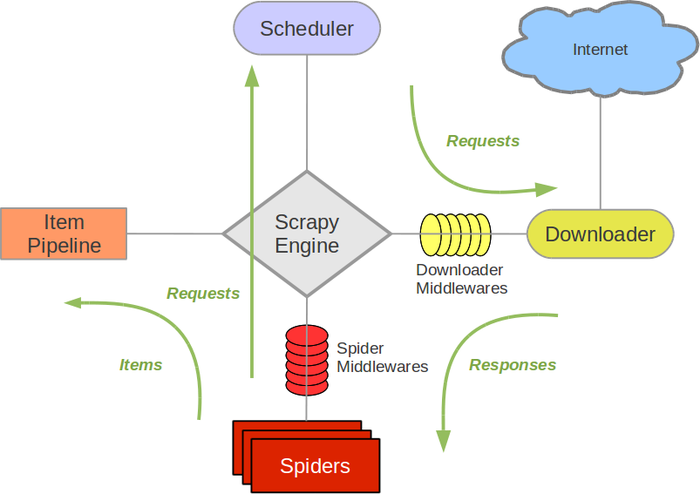
三、Scrapy架构
原文链接:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/architecture.html
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
事件驱动网络(Event-driven networking)
Scrapy基于事件驱动网络框架 Twisted 编写。因此,Scrapy基于并发性考虑由非阻塞(即异步)的实现。
关于异步编程及Twisted更多的内容请查看下列链接:
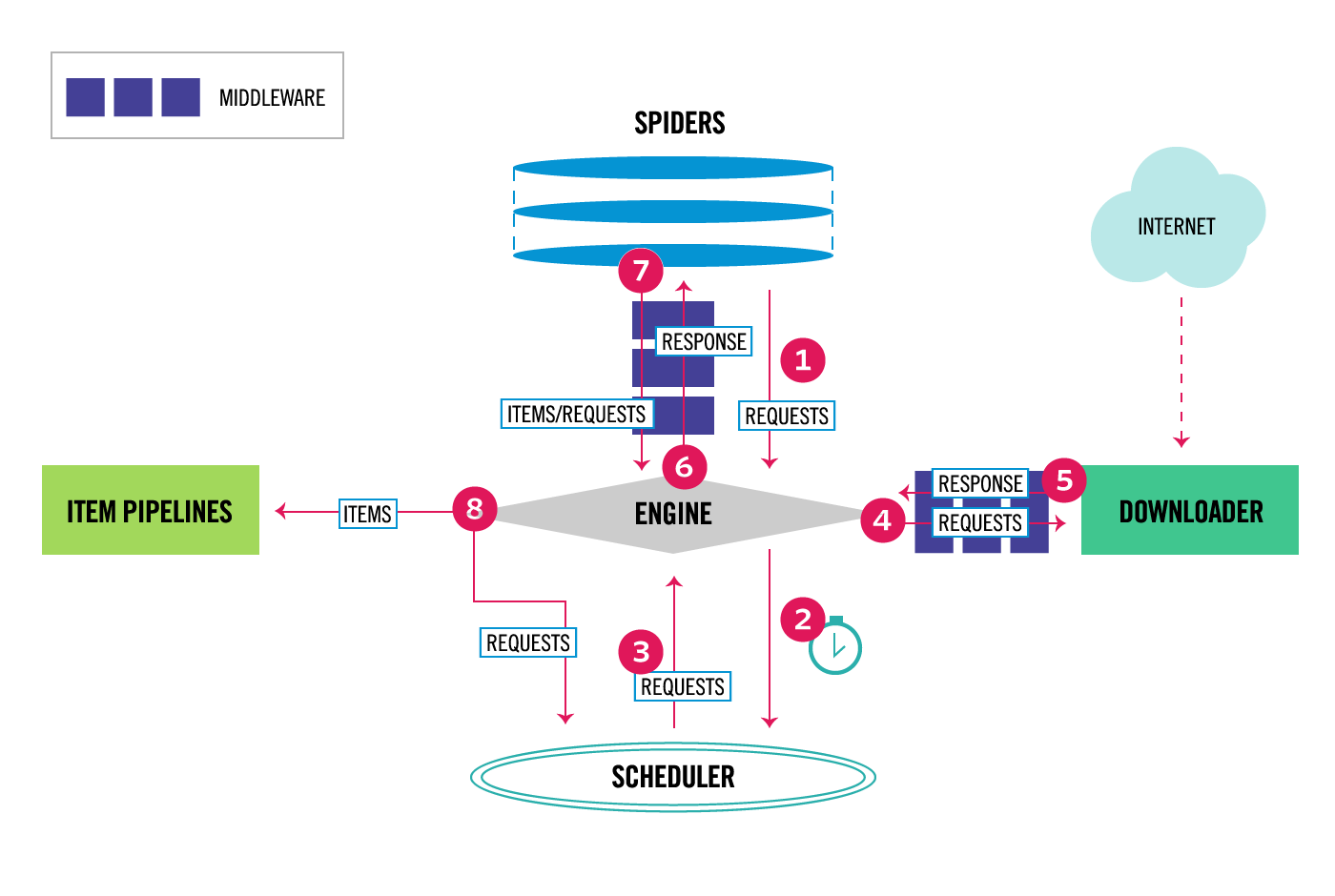
四、Scrapy架构
原文链接:https://docs.scrapy.org/en/latest/topics/architecture.html
下图展示了Scrapy的架构、它的组件及数据流(红色箭头)。分别对组件和数据流进行了说明。
数据流
数据流是受执行引擎控制的,流程如下:
- 引擎从爬虫得到初始请求;
- 引擎在调度器中调度请求,并请求下一个要爬取的请求;
- 调度器返回引擎下一个要爬取的请求;
- 通过下载中间件,引擎将请求发送到下载器;
- 页面下载完毕之后,下载器生成一个该页面的响应,并通过下载中间件发送给引擎;
- 引擎收到来自下载器的响应,并通过爬虫中间件,将它发送到爬虫进行处理;
- 爬虫处理响应,而后返回抓取到的items和新的请求到引擎,返回还要要通过爬虫中间件;
- 引擎将处理好的items发送到Item Pipelines,然后发送已处理的请求到调度器,并询问下个可能的请求;
- 这个过程重复进行(从1开始),直到调度器没有更多的请求。
组件
Scrapy引擎
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。
调度器
调度器从引擎接受请求并将其排队,以便之后引擎请求它们时提供给引擎。
下载器
下载器负责获取页面,并提供给引擎,引擎再将其提供给爬虫。
爬虫
Spider是Scrapy用户编写的用于解析请求并提取item或额外跟进的请求的类。
Item Pipeline
Item Pipeline负责处理爬虫提取出来的item。典型的任务有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),当请求从引擎到下载器时处理请求,响应从下载器到引擎时处理响应。
如果要做以下的工作,就可以使用下载器中间件:
- 请求发送给下载器之前,处理这个请求(即,在Scrapy发送请求到网站之前);
- 传递响应到爬虫之前,修改收到的响应;
- 发送一个新的请求到爬虫,而不是传递收到的响应到爬虫;
- 没有获取网页,直接传递响应给爬虫;
- 默默丢弃一些请求。
爬虫中间件
爬虫中间件是在引擎及爬虫之间的特定钩子(specific hook),处理爬虫的输入(响应)和输出(items和请求)。
爬虫中间件的可以用来:
- 对爬虫调回的输出做后处理 —— 修改、添加、移除请求或items;
- 后处理初始请求(start_requests);
- 处理爬虫异常;
- 调用errback,而不是基于响应内容调回一些请求。
事件驱动网络
Scrapy是基于事件驱动网络框架 Twisted 编写的。因此,Scrapy基于并发考虑由非阻塞(异步)代码实现。
关于异步编程及Twisted更多的内容请查看下列链接: