一、前言
计算机视觉长久以来没有大的突破,卷积神经网络的出现,给这一领域带来了突破,本篇博客,将通过具体的实例来看看卷积神经网络在图像识别上的应用。
导读
1、问题描述
2、解决问题的思路
3、用DL4J进行实现
二、问题
有如下一组验证码的图片,图片大小为60*160,验证码由5个数字组成,数字的范围为0到9,并且每个验证码图片上都加上了干扰背景,图片的文件名,表示验证码上的数字,样本图片如下:
![]()
穷举每张图片的可能性几乎不可能,所以传统的程序思路不可能解这个问题,那么必须让计算机通过自我学习,获取识别验证码的能力。先让计算机看大量的验证码的图片,并告诉计算机这些图片的结果,让计算机自我学习,慢慢地计算机就学会了识别验证码。
三、解决思路
1、特征
每个数字的形状各异,各自特征明显,这里的特征实际上指的是线条的走向、弯曲程度等等形状上的不同表征,那么对于侦测图形上的形状,卷积神经网络加上Relu和Max采样,可以很精确的做到这一点,本质原因在于,把卷积核拉直了看,本质上所做的事情就算向量的点积运算,求一个向量在另一个向量上的投影。对于卷积神经网络的原理可以看看《有趣的卷积神经网络》
2、网络结构设计
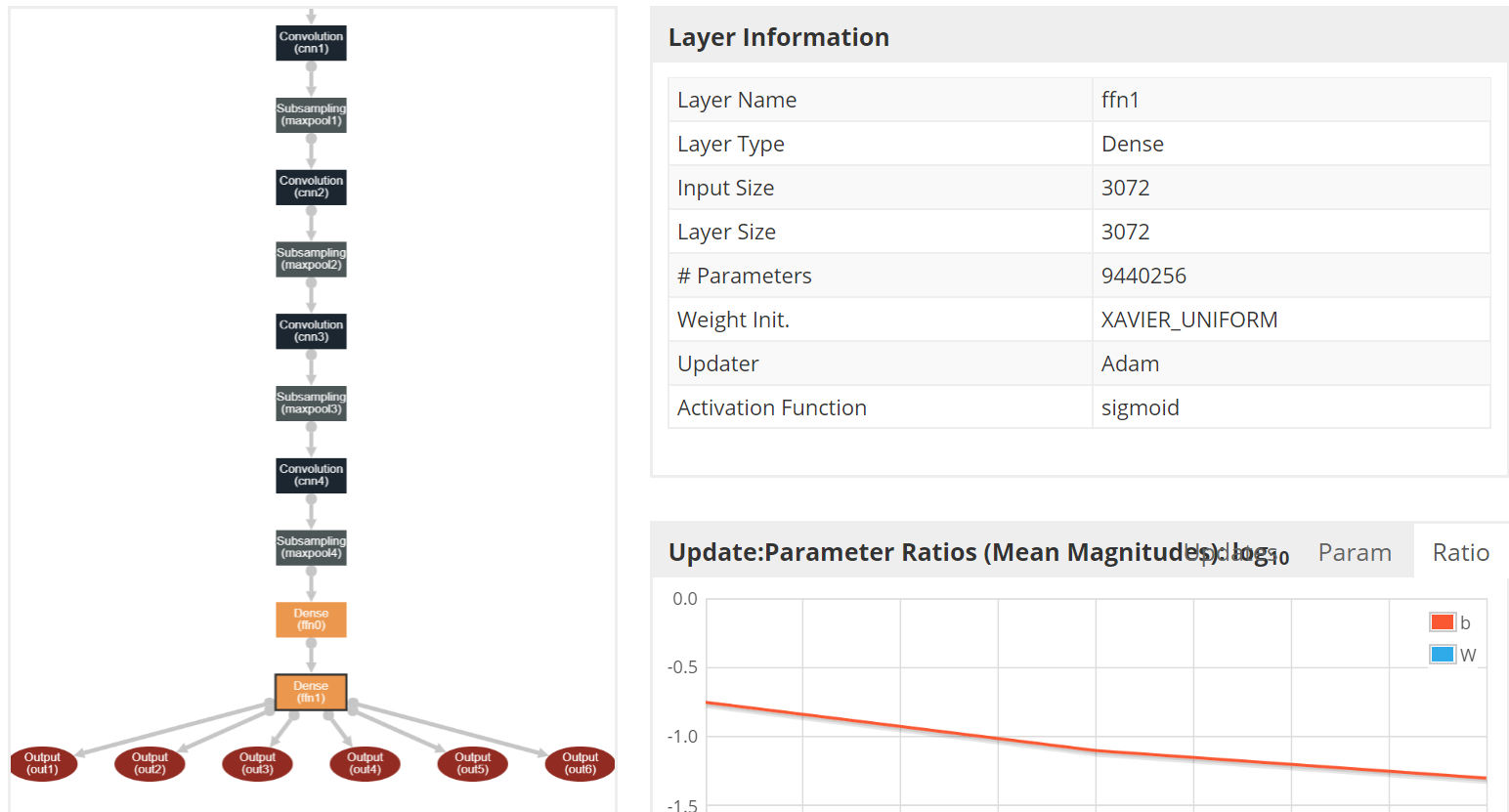
对于每张图片而言,有5个数字作为输出结果,那么得设计一个有5个output的深度神经网络,首先用多个卷积核+Max采样层的结构来抽取明显特征,最后获得的特征经过两个全连接层逼近,这里加全连接层有两个目的,第一:经过sigmoid函数把值压缩到0到1之间,便于softmax计算,第二,加上全连接层可以更加抽象特征,让函数的逼近更加容易。最终的网络结构如下:
![]()
3、张量表示
对于Label的表示用one-hot来表示,这样可以很好的配合softmax,下图展示了从0到9的数字表示,沿着行的方向,由上而下,分别表示0到9
![]()
对于图片上的像素点,值域在0到255之间,图片如果是彩色,那么实际上会有三个通道,这里都是黑白色,所以,只有一个通道,取图片上真实像素点的值,除以255进行归一化即可。
四、代码实现
1、网络结构
public static ComputationGraph createModel() {
ComputationGraphConfiguration config = new NeuralNetConfiguration.Builder()
.seed(seed)
.gradientNormalization(GradientNormalization.RenormalizeL2PerLayer)
.l2(1e-3)
.updater(new Adam(1e-3))
.weightInit( WeightInit.XAVIER_UNIFORM)
.graphBuilder()
.addInputs("trainFeatures")
.setInputTypes(InputType.convolutional(60, 160, 1))
.setOutputs("out1", "out2", "out3", "out4", "out5", "out6")
.addLayer("cnn1", new ConvolutionLayer.Builder(new int[]{5, 5}, new int[]{1, 1}, new int[]{0, 0})
.nIn(1).nOut(48).activation( Activation.RELU).build(), "trainFeatures")
.addLayer("maxpool1", new SubsamplingLayer.Builder(PoolingType.MAX, new int[]{2,2}, new int[]{2, 2}, new int[]{0, 0})
.build(), "cnn1")
.addLayer("cnn2", new ConvolutionLayer.Builder(new int[]{5, 5}, new int[]{1, 1}, new int[]{0, 0})
.nOut(64).activation( Activation.RELU).build(), "maxpool1")
.addLayer("maxpool2", new SubsamplingLayer.Builder(PoolingType.MAX, new int[]{2,1}, new int[]{2, 1}, new int[]{0, 0})
.build(), "cnn2")
.addLayer("cnn3", new ConvolutionLayer.Builder(new int[]{3, 3}, new int[]{1, 1}, new int[]{0, 0})
.nOut(128).activation( Activation.RELU).build(), "maxpool2")
.addLayer("maxpool3", new SubsamplingLayer.Builder(PoolingType.MAX, new int[]{2,2}, new int[]{2, 2}, new int[]{0, 0})
.build(), "cnn3")
.addLayer("cnn4", new ConvolutionLayer.Builder(new int[]{4, 4}, new int[]{1, 1}, new int[]{0, 0})
.nOut(256).activation( Activation.RELU).build(), "maxpool3")
.addLayer("maxpool4", new SubsamplingLayer.Builder(PoolingType.MAX, new int[]{2,2}, new int[]{2, 2}, new int[]{0, 0})
.build(), "cnn4")
.addLayer("ffn0", new DenseLayer.Builder().nOut(3072)
.build(), "maxpool4")
.addLayer("ffn1", new DenseLayer.Builder().nOut(3072)
.build(), "ffn0")
.addLayer("out1", new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(10).activation(Activation.SOFTMAX).build(), "ffn1")
.addLayer("out2", new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(10).activation(Activation.SOFTMAX).build(), "ffn1")
.addLayer("out3", new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(10).activation(Activation.SOFTMAX).build(), "ffn1")
.addLayer("out4", new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(10).activation(Activation.SOFTMAX).build(), "ffn1")
.addLayer("out5", new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(10).activation(Activation.SOFTMAX).build(), "ffn1")
.addLayer("out6", new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(10).activation(Activation.SOFTMAX).build(), "ffn1")
.pretrain(false).backprop(true)
.build();
ComputationGraph model = new ComputationGraph(config);
model.init();
return model;
}
2、训练集构建
public MultiDataSet convertDataSet(int num) throws Exception {
int batchNumCount = 0;
INDArray[] featuresMask = null;
INDArray[] labelMask = null;
List<MultiDataSet> multiDataSets = new ArrayList<>();
while (batchNumCount != num && fileIterator.hasNext()) {
File image = fileIterator.next();
String imageName = image.getName().substring(0,image.getName().lastIndexOf('.'));
String[] imageNames = imageName.split("");
INDArray feature = asMatrix(image);
INDArray[] features = new INDArray[]{feature};
INDArray[] labels = new INDArray[6];
Nd4j.getAffinityManager().ensureLocation(feature, AffinityManager.Location.DEVICE);
if (imageName.length() < 6) {
imageName = imageName + "0";
imageNames = imageName.split("");
}
for (int i = 0; i < imageNames.length; i ++) {
int digit = Integer.parseInt(imageNames[i]);
labels[i] = Nd4j.zeros(1, 10).putScalar(new int[]{0, digit}, 1);
}
feature = feature.muli(1.0/255.0);
multiDataSets.add(new MultiDataSet(features, labels, featuresMask, labelMask));
batchNumCount ++;
}
MultiDataSet result = MultiDataSet.merge(multiDataSets);
return result;
}
五、后记
用deeplearning4j构建一个深度神经网络,几乎没有多余的代码,非常优雅就可以解一个复杂的图像识别问题,对于上述代码有几点说明:
1、对于DenseLayer层,这里没有设置网络输入的size,实际上在dl4j内部已经做了这个set操作
2、对于梯度更新优化,这里选用Adam,Adam融合了动量和自适应learningRate两方面的因素,通常会有更好的效果
3、损失函数用的类Log函数,和交叉熵有相同的效果
4、模型训练好可以使用 ModelSerializer.writeModel(model, modelPath, true)来保存网络结构,就可以用于图像识别了
完整的代码,可以查看deeplearning4j的example
---------------------------------------------------------------------------------------------------------
快乐源于分享。
此博客乃作者原创, 转载请注明出处