版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/45954731
Intellij Idea下载地址:
官方下载
选择右下角的Community Edition版本下载安装即可
本文中使用的是windows系统
环境为:
jdk1.6.0_45
scala2.10.5
在网上下载jdk和scala的安装包双击运行安装即可
注意:如果之后要将scala文件打包成jar包并在spark集群上运行的话,请确保spark集群和打包操作所在机器 环境保持一致!不然运行jar包会出现很多异常
要使用idea开发spark程序首先要安装scala插件
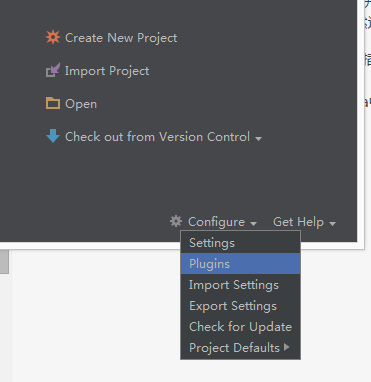
进入idea主界面
在线安装:
选择Plugins
![这里写图片描述]()
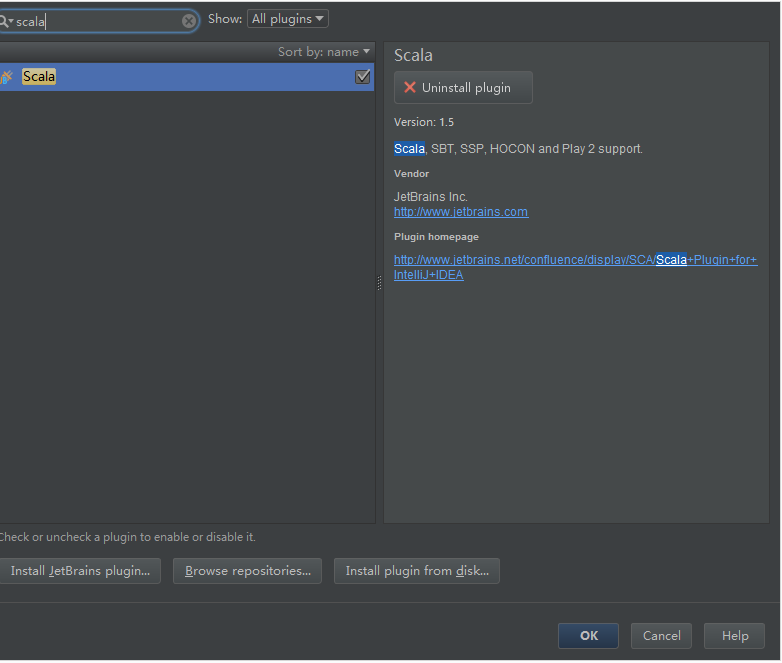
输入scala
![这里写图片描述]()
选择安装即可
离线安装:
scala离线插件包
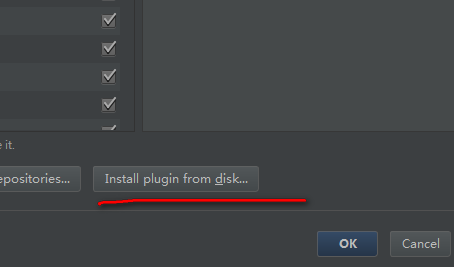
下载完scala插件包之后,在idea主界面的Plugins中选择从本地安装
![这里写图片描述]()
选择下载好的scala插件安装即可
本文使用的是Idea14.1.3 对应的scala插件版本为1.5
不同版本的Idea对应的scala插件版本可能不同,无法识别
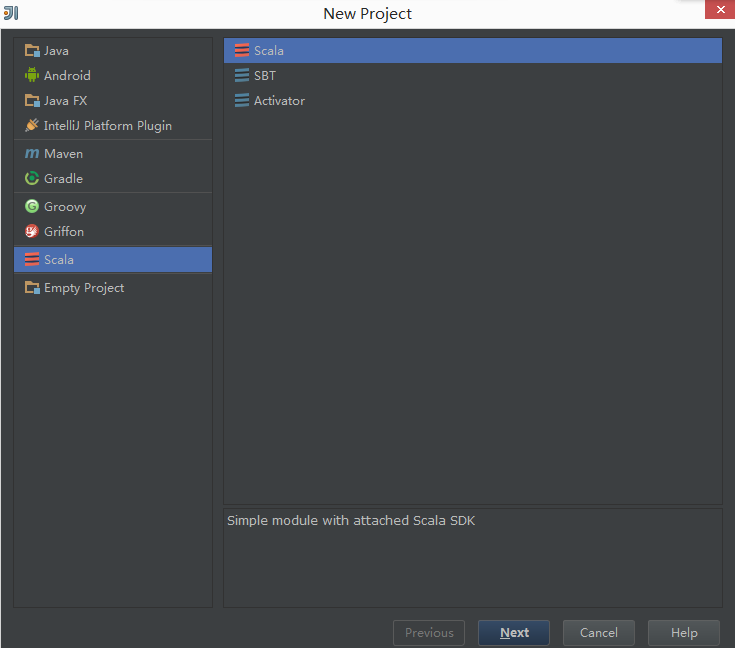
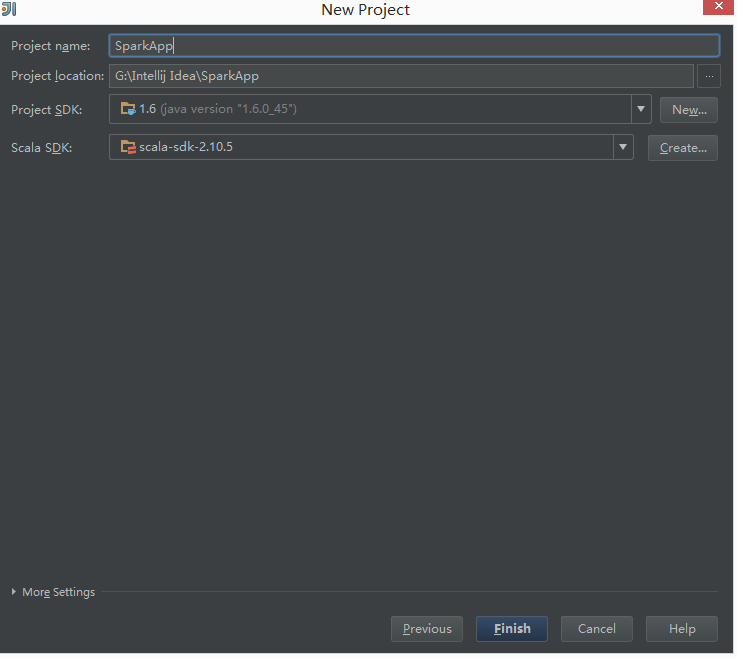
现在可以用idea来新建一个scala项目
New Project->Scala
![这里写图片描述]()
再此页面中选择jdk和scala安装的目录,Idea会自动识别
![这里写图片描述]()
Finish完成Project的创建
在File中选择Project Structure对项目进行配置
![这里写图片描述]()
选中左侧的Mudules,点击+号添加一下新的Module。Idea中的Project相当于Eclipse中的一个WorkSpace,里面的Module相当于Project
![这里写图片描述]()
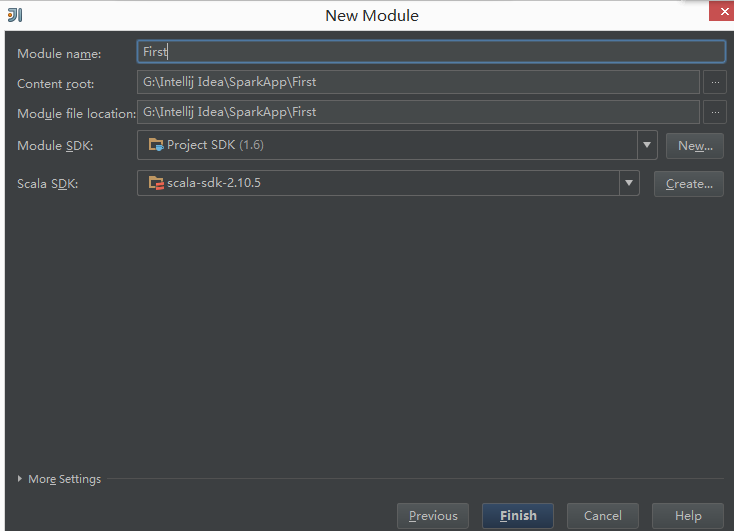
新建一个First的Module
![这里写图片描述]()
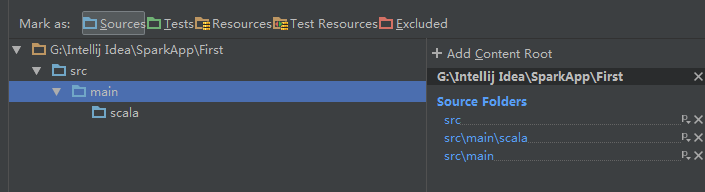
在src目下新新建main和scala目录,并设置为Sources类型
![这里写图片描述]()
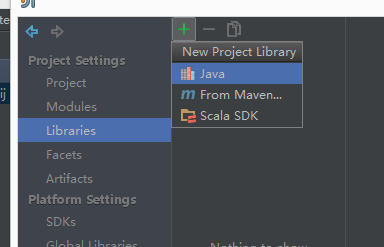
点击左侧的Liberaries,点击+进行添加spark的jar包
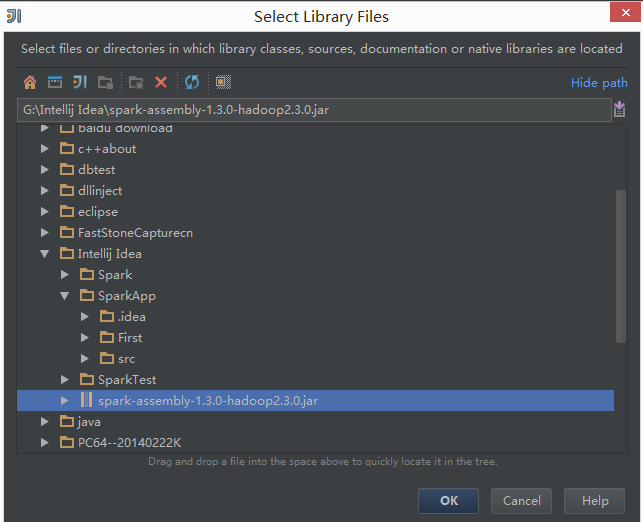
![这里写图片描述]()
只要引入图中的那个jar包即可,spark版本为1.3.1,一般下载spark之后可以在其目录下找到
![这里写图片描述]()
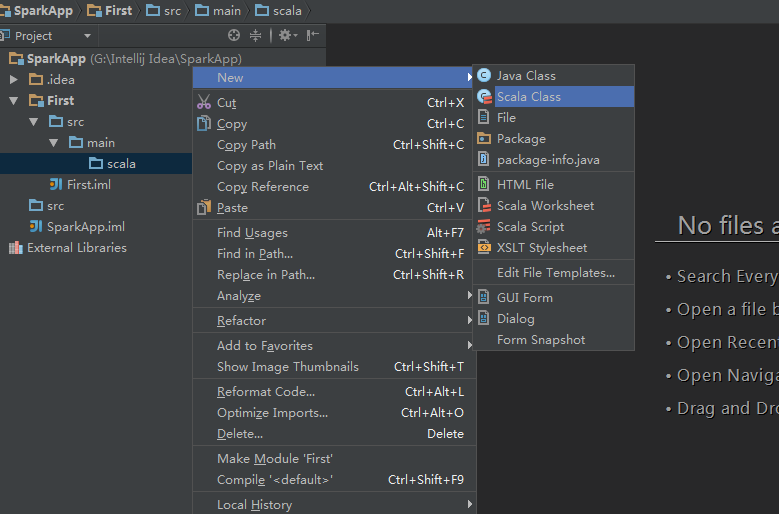
在scala文件夹下右键新建一个scala class,类型选择为Object
![这里写图片描述]()
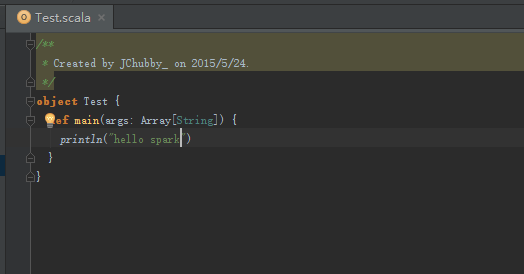
编写简单的代码
![这里写图片描述]()
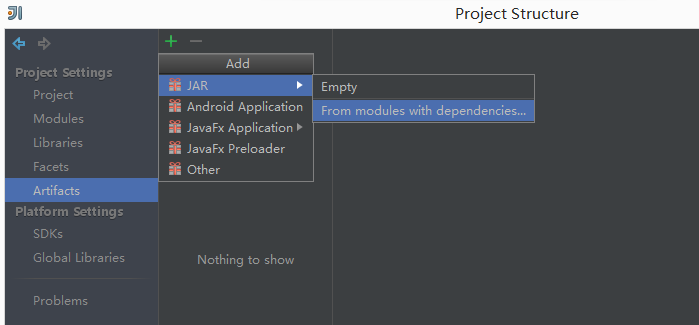
File->Project Structure->在右侧选择Artifacts->JAR->From modules with dependencies
![这里写图片描述]()
选择新建的Test
![这里写图片描述]()
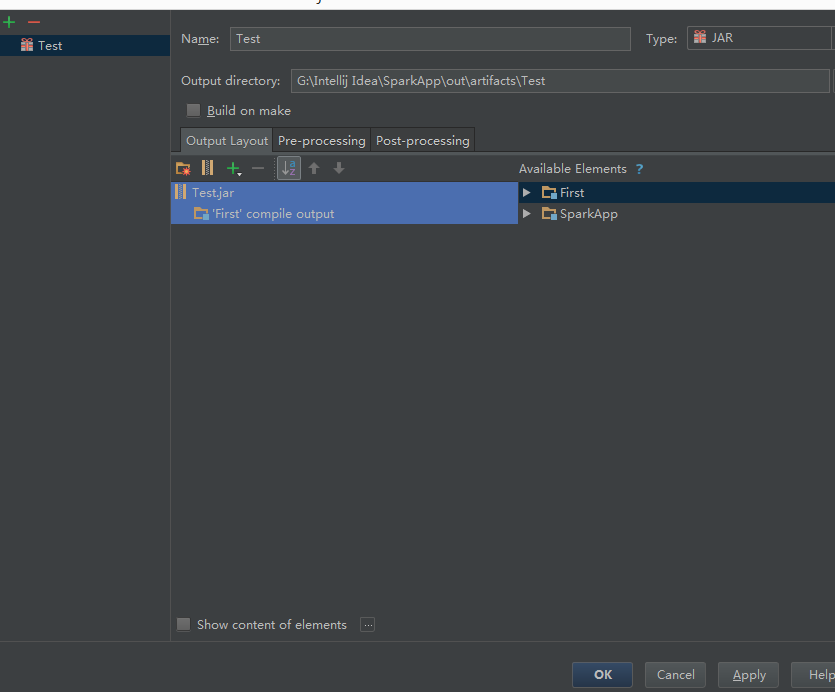
将默认的SparkApp:jar重新名一下,并将依赖包删除,只剩First这个module本身(因为集群上已经安装了jdk,scala和spark,所以那些包可以去掉节省编译时间)
![这里写图片描述]()
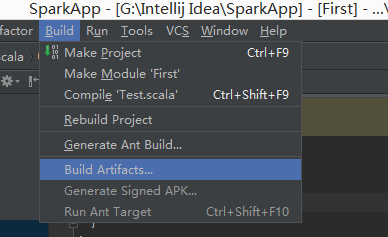
在菜单栏上选择Build->Build Artifacts
![这里写图片描述]()
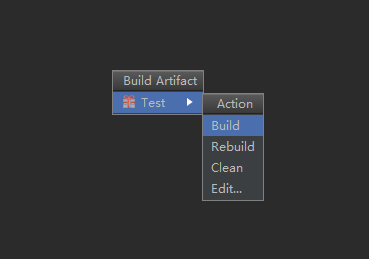
如图所示的操作
![这里写图片描述]()
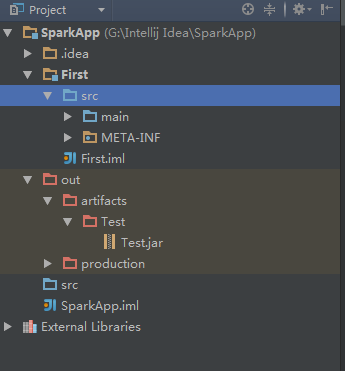
编译成功后可以在对应的输出文件夹下找到jar包
![这里写图片描述]()
需要注意:
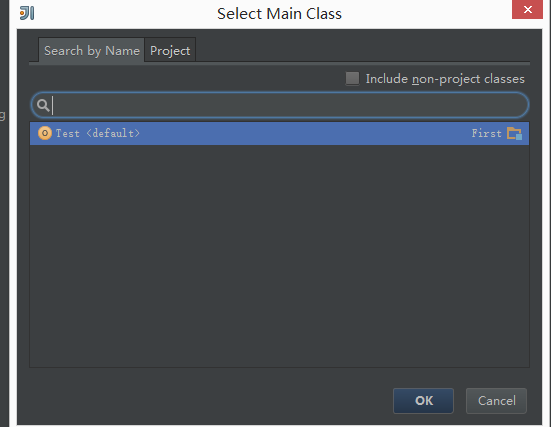
编译选择Main Class时如果是手动选择Object的话,Idea会弹出错误提示xx is not acceptable,而让其自动过滤选择的时候就不会。。。
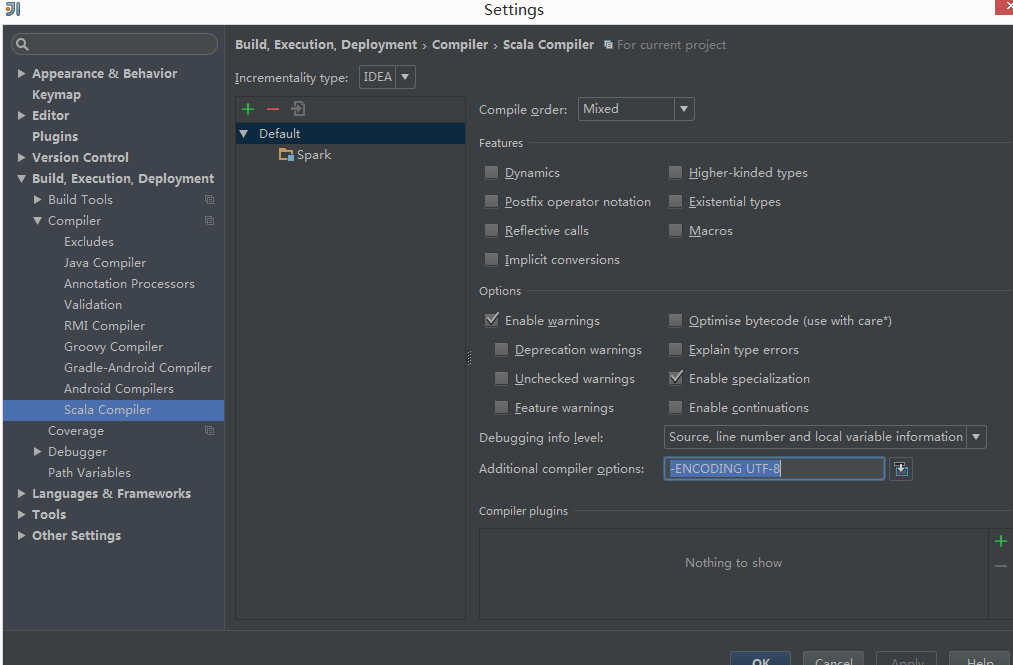
scala代码中,如果注释中有中文默认可能会编译错误
在下图设置中加入
-ENCODING UTF-8
即可
![这里写图片描述]()