版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/45726665
首先介绍一下Shark的概念
Shark简单的说就是Spark上的Hive,其底层依赖于Hive引擎的
但是在Spark平台上,Shark的解析速度是Hive的几多倍
它就是Hive在Spark上的体现,并且是升级版,一个强大的数据仓库,并且是兼容Hive语法的
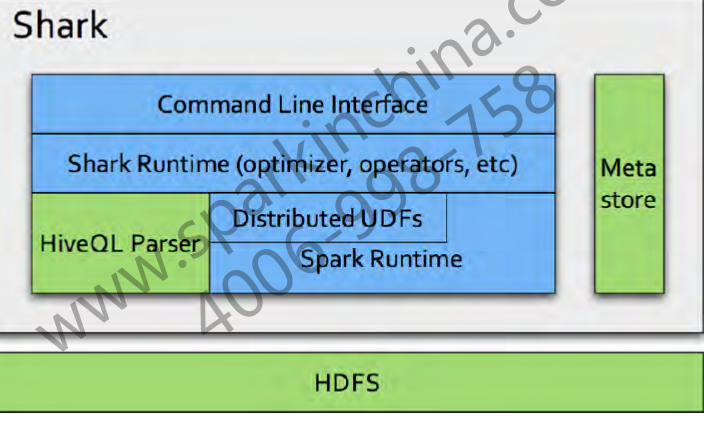
下面给出一张来自网上的Shark构架图
![Shark的构架图]()
从图上可以看出,Spark的最底层大部分还是基于HDFS的,Shark中的数据信息等也是对应着HDFS上的文件
从图中绿色格子中可以看到,在Shark的整个构架中HiveQL的引擎还是占据着底层不可分割的部分,而Meta store的制度是Hive的根本,对Shark的重要性自然不言而喻
Shark中创建一张外部分区表的代码格式如下:
create [external] table [if not exists] table_name(col_name data_type,…)
[partitioned by (col_name data_type,…)]
[row format row_format]
[fields terminated by ‘\t’]
[lines terminated by ‘\n’]
[stored as file_format]
[location hdfs_path]
基本和Hive的格式没有什么差别
在Shark中还有一种高效的表,叫做缓存表
创建缓存表的方式如下:
create table xx_cached as select …
只要在表名的最后加上_cached即可
缓存表顾名思义,将查询到的数据生成表存储在缓存中,再次查询的时候速度将是几何提升的
Shark的用法:
在Spark的bin目录下使用shark脚本进入客户端程序
shark -f 要执行的.sql文件位置
执行完后可以就生成对应的表,可以再客户端中使用SQL语句进行查询
但是…
对比起Hive,如此好用性能又好的Shark
在Spark1.0版本开始,Shark被官方抛弃了…
Why?
原因就是Shark太过依赖于Hive了,导致执行任务的时候不能灵活的添加新的优化策略
于是Spark团队决定从头开发一套完全脱离Hive,基于Spark平台的数据仓库框架
于是SparkSQL诞生了
相对于Shark,SparkSQL有什么优势呢?
第一,也是根本SparkSQL产生的根本原因,其完全脱离了Hive的限制
第二,SparkSQL支持查询原生的RDD,这点就极为关键了。RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础
第三,能够在Scala中写SQL语句。支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用
第四,Catalyst。Catalyst能够帮助用户优化查询,即使用户的水平不高,写不出高效率的代码,Catalyst也能够进行一定程度的性能优化
简简单单的从以上几点就可以看出,SparkSQL和Shark相比,在性能和可用性方面肯定提升了几个等级
在大数据处理领域,批处理、实时处理和交互式查询是三个主要的处理方式,SparkSQL诞生就是为了解决Spark平台上的交互式查询问题,并且提供SQL接口兼容原有数据库用户的使用习惯
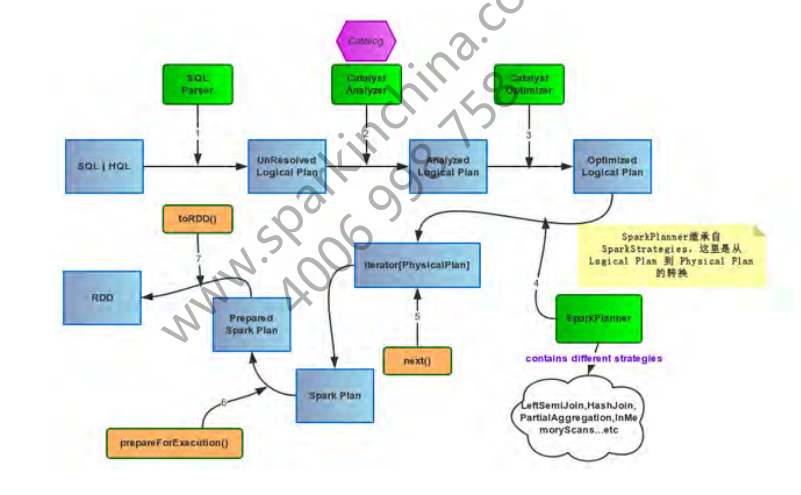
这里要重点注意一下Catalyst部分。
Catalyst是SparkSQL的调度核心,翻译SQL语句形成执行计划的过程中会对其进行优化并且仍然是遵循DAG图
执行流程:
- SqlParser 对SQL语法进行解析
- Analyzer进行属性和关系关联校验
- Optimizer进行启发式逻辑查询优化
- QueryPlanner将逻辑查询计划转化为物理查询计划
- prepareForExecution调整数据分布,转换为执行计划
- 进入Spark执行空间转为DAG图执行
下面给出一张网上的SparkSQL构架图:
![SparkSQL构架图]()
可以明显的看到,在Shark中出于底层关键地位的Hive变成了顶层可变的程序模块
并且SparkSQL还支持JDBC/ODBC等数据库接口和JSON格式,Parquet格式的数据
支持Java ,Python等编程接口
SparkSQL运行流程图:
![SparkSQL运行流程图]()
文章的最后给出一段SparkSQL的实例代码(Scala语言):
val sc:SparkContext
val sqlContext = new SqlContext(sc)
import sqlContext._
case class Person(name:String,age:String)//定义一个Person类,case class是后面数据能够生产SchemaRDD的关键
val people:RDD[Person] = sc.textFile("people.txt").map(_.split(",")).map(p => Person(p(0),p(1).toInt))
people.registerAsTable("people")
val teenagers = sql("select name from people where age >= 10 && age <= 19")
teenagers.map(t => "Name:" + t(0)).collect().foreach(println)